Turning a Fast Network into a Smart Network with Autopilot

Directeur de l’ingénierie (Director of Engineering), Fastly

Principal Network Engineer, Fastly

Senior Manager of Technical Operations, Fastly

SVP of Engineering, Fastly
At Fastly we often highlight our powerful POPs and modern architecture when asked how we’re different, and better than the competition. Today we’re excited to give you another peek under the hood at the kind of innovation we can achieve on a modern network that is fully software-defined.
This past February, Fastly delivered a new record of 81.9 Tbps of traffic during the Super Bowl, and absolutely no one had to do anything with egress policies to manage that traffic over the course of the event thanks to Autopilot. Autopilot is our new zero-touch egress traffic engineering automation system, and because it was running, no manual interventions were required even for this record-breaking day of service. This means that for the first time ever at Fastly we set a new traffic record for the Fastly network while reducing the number of people who were needed to manage it. (And we notably reduced that number all the way to zero.) It took a lot of people across different Fastly teams, working incredibly hard, to improve the self-managing capabilities of our network, and the result is a network with complete automation that can react quickly and more frequently to failures, congestion, and performance degradation with zero manual intervention.
Autopilot brings many benefits to Fastly, but it is even better for our customers who can now be even more confident in our ability to manage events like network provider failures or DDoS attacks and unexpected traffic spikes — all while maintaining a seamless and unimpacted experience for their end users. Let’s look at how we got here, and just how well Autopilot works. (Oh, but if you’re not a customer yet, get in touch or get started with our free tier. This is the network you want to be on.)
Getting to this result required a lot of effort over several years. Exactly three years ago, we shared how we managed the traffic during the 2020 Super Bowl. At that time, an earlier generation of our traffic engineering automation would route traffic around common capacity bottlenecks while requiring operators to deal with only the most complex cases. That approach served us well for the traffic and network footprint we had three years ago, but it still limited our ability to scale our traffic and network footprint because, while we had reduced human involvement, people were still required to deal reactively with capacity. This translates to hiring and onboarding becoming a bottleneck of its own as we would need to scale the number of network operators at least at the same rate of the expansion of our network. On top of that, while we can prepare and be effective during a planned event like a Super Bowl, human neurophysiology is not always at its peak performance when woken up in the middle of the night to deal with unexpected internet weather events.
Achieving Complete automation with Autopilot and Precision Path
The only way forward was to remove humans from the picture entirely. This single improvement allows us to scale easily while also greatly improving our handling of capacity and performance issues. Manual interventions have a cost. They require a human to reason about the problem at hand and make a decision. This cannot be performed infinite times, so that requires us to preserve energy and only act when the problem is large enough to impact customer performance. It also means that when a human-driven action is taken, it normally moves a larger amount of traffic to avoid having to deal with the same issue again soon, and to minimize the amount of human interventions needed.
A modern CDN gives you huge improvements in caching, SEO, performance, conversions, & more.
With complete automation the cost of making an action is virtually 0, allowing very frequent micro-optimizations whenever small issues occur, or are about to occur. The additional precision and reactivity provided by full automation makes it possible to safely run links at higher utilization and rapidly move traffic around as necessary.
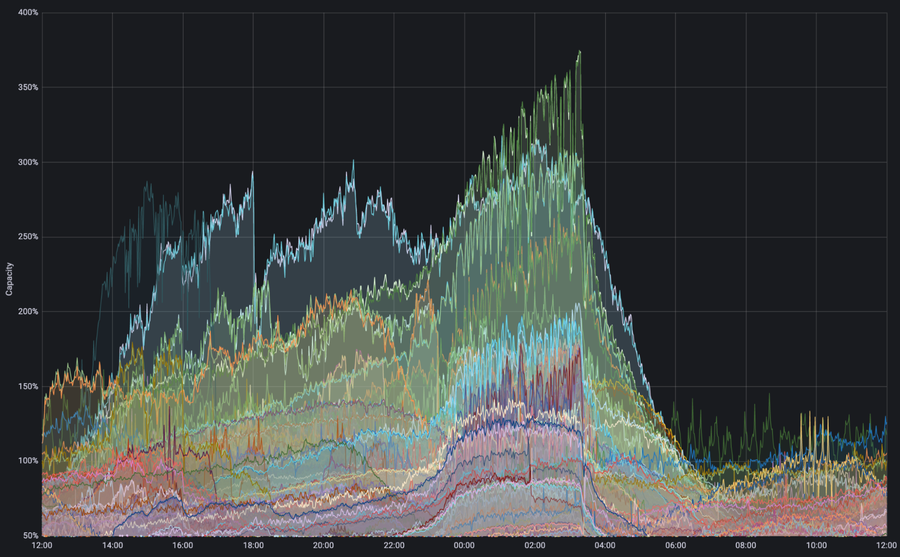
Figure: Egress interface traffic demand over capacity. Multiple interfaces had a demand that exceeded three times the physical capacity available during the Super Bowl, triggering automated traffic engineering overrides, which enabled continued efficient delivery without negative consequences to the network.
The graph above shows an example where Autopilot detected traffic demand exceeding physical link capacity. During the Super Bowl this demand exceeded 3 times the available capacity in some cases. Without Autopilot the peaks in traffic demand would have overwhelmed those links, requiring a lot of human intervention to prevent failure, but then to manage all of the downstream impacts of those interventions in order to get the network operating at top efficiency again. With Autopilot the network deflected traffic onto secondary paths automatically and we were able to deliver the excess demand without any performance degradation.
This post sheds light on the systems we built to scale handling large traffic events without any operator intervention.
Technical problem
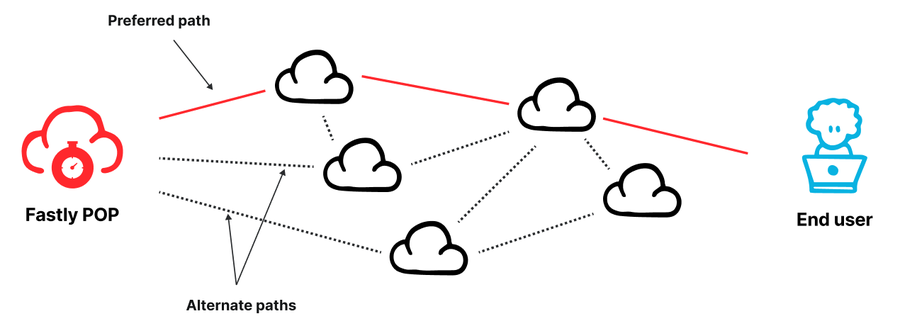
Figure - Fastly POP is interconnected to the Internet via multiple peers and transit providers
The Fastly network of Points of Presence (POPs) is distributed across the world. Each POP is “multihomed”, i.e., it is interconnected to the Internet via a number of different networks, which are either peers or transit providers, for capacity and reliability purposes. With multiple routing options available, the challenge is how to select the best available path. We need to ensure that we pick the best performing route (in any given moment), and quickly move traffic away from paths experiencing failures or congestion.
Network providers use a protocol called Border Gateway Protocol (BGP) to exchange information about the reachability of Internet destinations. Fastly consumes BGP updates from its neighbors, and learns which neighbor can be used to deliver traffic to a given destination. However, BGP has several limitations. First, it is not capacity or performance aware: it can only be used to communicate whether an Internet destination can be reached or not, but not whether there is enough capacity to deliver the desired amount of traffic or what the throughput or latency would be for that delivery. Second, BGP is slow at reacting to remote failures: if a failure on a remote path occurs, it typically takes minutes for updates to be propagated, during which time blackholes and loops may occur.
Solving these problems without creating new ones is challenging, especially when operating at the scale of tens of Terabits per second (Tbps) of traffic. In fact, while it is desirable to rapidly route around failures, we need to be careful in those processes as well because rerouting large amounts of traffic erroneously can move traffic away from a well performing path onto a worse performing one and create congestion downstream as a result of our action, resulting in poor user experience. In other words, if decisions are not made carefully, some actions that are taken to reduce congestion will actually increase it instead - sometimes significantly.
Fastly’s solution to the problem is to use two different control systems that operate at different timescales to ensure we rapidly route around failures while keeping traffic on most performing paths.
The first system, which operates at a timescale of tens of milliseconds (to make a few round trips), monitors the performance of each TCP connection between Fastly and end users. If the connection fails to make forward progress for a few round trip times it reroutes that individual connection onto alternate paths until it resumes progress. This is the system underlying our Precision Path product for protecting connections between Fastly and end users, and it makes sure we rapidly react to network failures by surgically rerouting individual flows that are experiencing issues on these smaller timescales.
The second system, internally named Autopilot, operates over a longer timescale. Every minute it estimates the residual capacity of our links and the performance of network paths collected via network measurements. It uses that information to ensure traffic is allocated to links in order to optimize performance and prevent links from becoming congested. This system has a slower reaction time, but makes a more informed decision based on several minutes of high resolution network telemetry data. Autopilot ensures that large amounts of traffic can be moved confidently without downstream negative effects.
These two systems working together, make it possible to rapidly reroute struggling flows onto working paths and periodically adjust our overall routing configuration with enough data to make safe decisions. These systems operate 24/7 but had a particularly prominent role during the Super Bowl where they rerouted respectively 300 Gbps and 9 Tbps of traffic which would have otherwise been delivered over faulty, congested or underperforming paths.
This approach to egress traffic engineering using systems operating at different timescales to balance reactivity, accuracy, and safety of routing decisions is the first of its type in the industry to the best of our knowledge. In the remainder of this blog post, we are going to cover how both systems work but we’ll need to first make a small digression to explain how we route traffic out of our POPs, which is unusual and another approach where we’re also industry leaders.
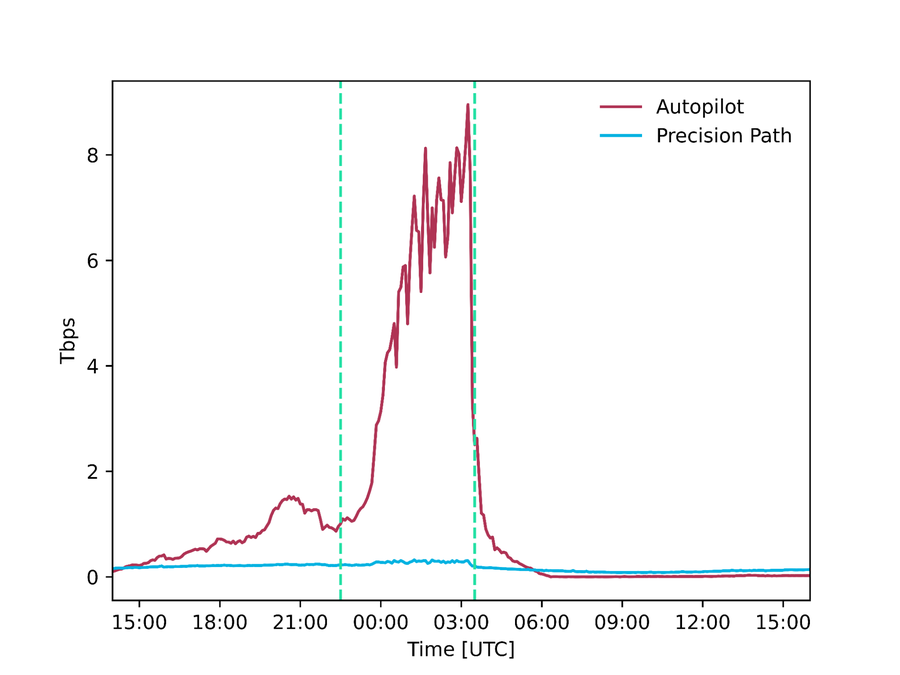
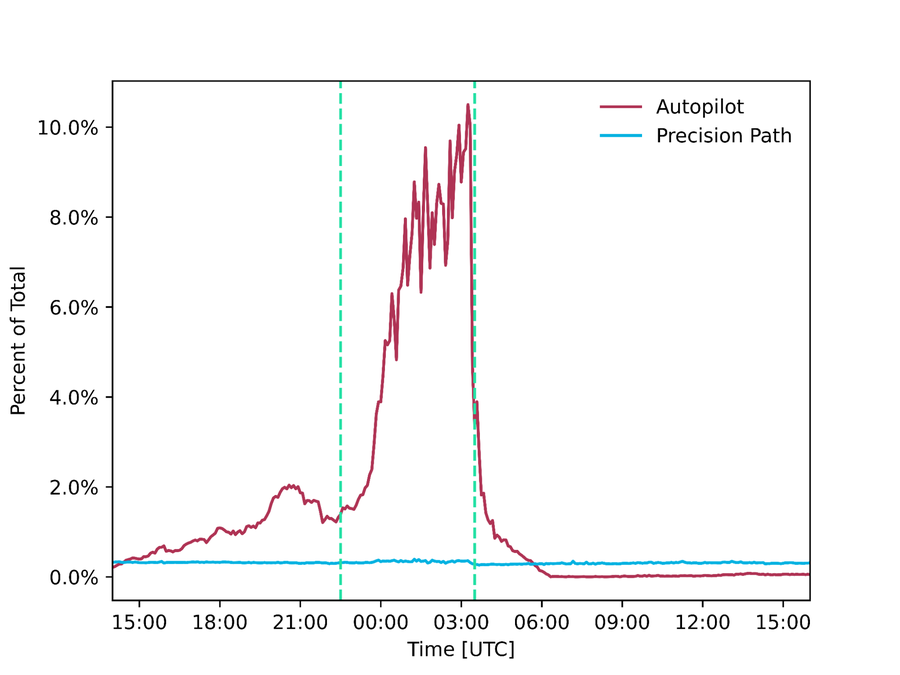
Figure - Amount of traffic (absolute and percentage of total traffic) delivered by Precision Path and Autopilot respectively during the Super Bowl
Fastly network architecture
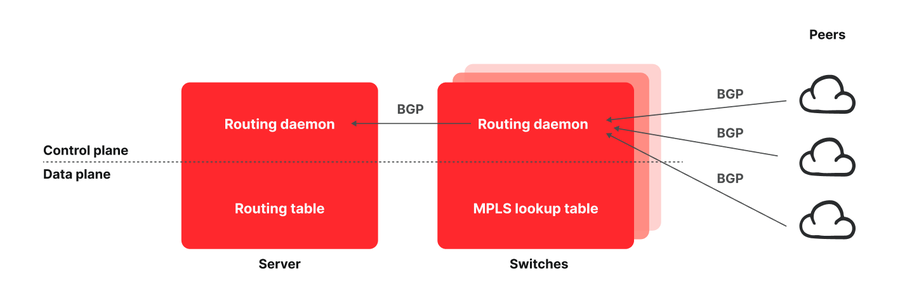
Figure - Fastly POP architecture
A typical Fastly POP comprises a layer of servers that are interconnected with all peers and transit providers via a tier of network switches. The typical approach to build an edge cloud POP consists in using network routers, which have a large enough memory to store the entire Internet routing table. In contrast, Fastly started designing a routing architecture that pushed all routes to end hosts in order to build a more cost-effective network, but we quickly realized and embraced the powerful capabilities that this architecture made possible. Endpoints that have visibility into the performance of flows now also have the means to influence their routing. This is one of the key reasons Fastly’s networking capabilities, programmability, flexibility, and ease of use continue to exceed the competition.
Here’s how our routing architecture works: Both switches and servers run routing daemons, which are instances of the BIRD Internet Routing Daemon with some proprietary patches applied to it. The daemons running on switches learn all routes advertised by our transits and peers. However, instead of injecting those routes in the routing table of the switches, they propagate them down to the servers which will then inject them into their routing tables. To make it possible for servers to then route traffic to the desired transit or peer, we use the Multiprotocol Label Switching (MPLS) protocol. We populate each switch with an entry in their MPLS lookup table (Label Forwarding Information Base [LFIB]) per each egress port and we tag all BGP route announcements propagated down to the servers with a community encoding the MPLS label that is used to route that traffic. The servers use this information to populate their routing table and use the appropriate label to route traffic out of the POP. We discuss this more at length in a scientific paper we published at USENIX NSDI ‘21.
Quickly routing around failures with Precision Path
Our approach of pushing all routes to the servers, giving endpoints the ability to reroute based on transport and application-layer metrics, made it possible to build Precision Path. Precision Path works on a timeframe of tens of milliseconds to reroute individual flows in cases of path failures and severe congestion. It’s great at quickly routing away from failures happening right in the moment, but it’s not aware or able to make decisions about proactively selecting the best path. Precision Path is good at steering away from trouble, but not zooming out and getting a better overall picture to select an optimized new route. The technology behind our precision path product is discussed in this blog post and, more extensively in this peer-reviewed scientific paper, but here’s a brief explanation.
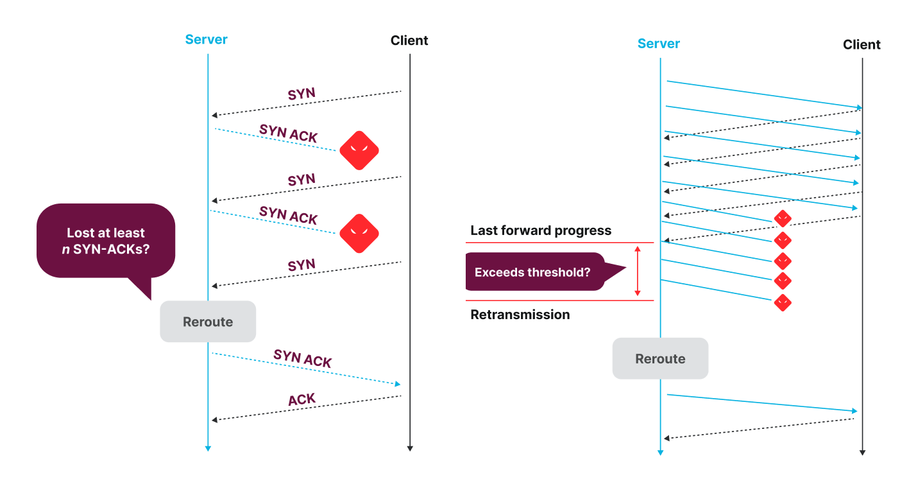
Figure - Precision path rerouting decision logic for connections being established (left) and connections already established (right).
This system is a Linux kernel patch that monitors the health status of individual TCP connections. When a connection fails to make forward progress for some Round Trip Time (RTT), indicating a potential path failure, it is rerouted onto a randomly chosen alternate path until it resumes forward progress. Being able to make per-flow rerouting decisions is made possible by our host-based routing architecture where servers select routes of outgoing traffic by applying MPLS labels. End hosts can move traffic rapidly on a per-flow granularity because they have both visibility into the progress of connections, and the means to change network route selection. This system is remarkably effective at rapidly addressing short-lived failures and performance degradation that operators or any other telemetry-driven traffic engineering would be too slow to address. The downside is that this system only reacts to severe performance degradations that are already visible in the data plane and moves traffic onto randomly selected alternate paths, just to select non-failing paths, but they might not be the best and most optimal paths.
Making more informed long-term routing decision with Autopilot
Autopilot complements the limitations of Precision Path because it’s not great at responding as quickly, but it makes more informed decisions based on knowledge of which paths are able to perform better, or are currently less congested. Rather than just moving traffic away from a failed path (like Precision Path), it moves larger amounts of traffic *toward* better parts of a network. Autopilot has not been presented before today, and we are excited to detail it extensively in this post.
Autopilot is a controller that receives network telemetry signals from our network such as packet samples, link capacity, RTT, packet loss measurements, and availability of routes for each given destination. Every minute, the Autopilot controller collects network telemetry, uses it to project per-egress interface traffic demand without override paths, and makes decisions to reroute traffic onto alternate paths if one or more links are about to reach full capacity or if the currently used path for a given destination is underperforming its alternatives.
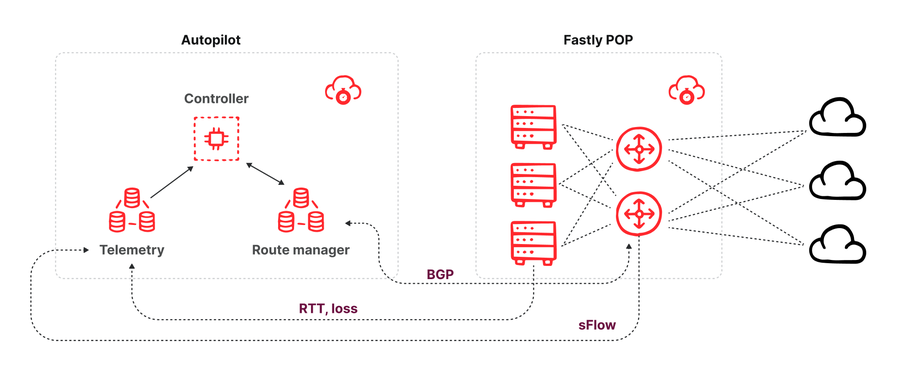
Figure - Autopilot architecture diagram
Autopilot’s architecture is comprised of three components (shown above):
A route manager, which peers with each switch within a POP and receives all route updates the switch received from its neighbors over a BGP peering session. The route manager provides an API that allows consumers to know what routes are available for a given destination prefix. The route manager also offers the ability to inject route overrides via its API. This is executed by announcing a BGP route update to the switch with a higher local preference value than routes learned from other peers and transit providers. This new route announcement will win the BGP tie-breaking mechanism and be inserted into servers’ routing tables and used to route traffic.
A telemetry collector, which receives sFlow packet samples from all the switches of a POP which allow an estimation of the volume of traffic broken down by destination interface and destination prefix as well as latency and packet loss measurements for all the traffic between Fastly POPs over all available providers from servers.
A controller, which consumes (every minute) the latest telemetry data (traffic volumes and performance) as well as all routes available for the prefixes currently served by the POP, and then computes whether to inject a BGP route override to steer traffic over alternate paths.
Making Precision Path and Autopilot work together
One challenge of having multiple control systems operating on the same inputs and outputs is having them work collaboratively to select the overall best options rather than compete with each other. Trying to select the best option from the limited vantage point of each separate optimization process could actually lead to additional disruption and do more harm than good. To the best of our knowledge, we are the first in the industry using this multi-timescale approach to traffic engineering.
The key challenge here is that once a flow is being rerouted by Precision Path, it no longer responds to BGP routing changes, including those triggered by Autopilot. As a result, Autopilot needs to account for the amount of traffic currently controlled by Precision Path in its decisions. We addressed this problem in two ways: first we tuned Precision Path to minimize the amount of traffic it reroutes, and by making that traffic observable by Autopilot so that it can be factored into Autopilot decisions.
When we first deployed Precision Path, we fine-tuned its configuration to minimize false positives. False positives would result in traffic being rerouted away from an optimal path that is temporarily experiencing a small hiccup, and onto longer paths with worse performance, which could in turn lead to a worse degradation by impacting the performance of affected TCP connections. We reported extensively on our tuning experiments in this paper. However, this is not enough, because even if we make the right decision at the time of rerouting a connection, the originally preferred path may recover a few minutes after the reroute, and this is typically what happens when BGP eventually catches up with the failure and withdraws routes through the failed path. To make sure we reroute connections back onto the preferred path when recovered, Precision Path probes the original path every five minutes after the first reroute, and if the preferred path is functional, it moves the connection back onto it. This mechanism is particularly helpful for long-lived connections, such as video streaming, which would otherwise be stuck on a backup path for their entire lifetime. This also minimizes the amount of traffic that Autopilot cannot control, giving it more room to maneuver.
The problem of making the amount of traffic routed by Precision Path visible to Autopilot is trickier. As we discuss earlier in this post, Autopilot learns the volume of traffic sent over each interface from sFlow packet samples emitted by switches. These samples report, among other things, over what interface the packets were sent to and which MPLS label it carried but do not report any information about how that MPLS label was applied. Our solution was to create a new set of alternate MPLS labels for our egress ports and allocate them for exclusive usage by Precision Path. This way, by looking up an MPLS label in our IP address management database, we can quickly find out if that packet was routed according to BGP path selection or according to Precision Path rerouting. We expose this information to the Autopilot controller which treats Precision Path as “uncontrollable”, i.e., traffic that will not move away from its current path even if the preferred route for its destination prefix is updated.
Making automation safe
Customers trust us with their business to occupy a position as a middleman between their services and their users, and we take that responsibility very seriously. While automating network operations allows for a more seamless experience for our customers, we also want to provide assurances to its reliability. We design all our automation with safety and operability at its core. Our systems fail gracefully when issues occur and are built so that network operators can always step in and override their behaviors using routing policy adjustments. The last aspect is particularly important because it allows operators to use tools and techniques learned in environments without automation and apply them here. Minimizing cognitive overhead by successfully automating more and more of the problem is particularly important to reduce the amount of time needed to solve problems when operating under duress. These are some of the approaches we used to make our automation safe and operable:
Standard operator tooling: both Precision Path and Autopilot can be controlled using standard network operator tools and techniques.
Precision Path can be disabled on individual routes by injecting a specific BGP community on an individual route announcement, which is a very common task that network engineers typically perform for a variety of reasons. Precision Path can also be disabled on an individual TCP session by setting a specific forwarding mark on the socket, which makes it possible to run active measurements without Precision Path kicking in and polluting results.
Autopilot route reselection is based on BGP best path selection, i.e., it will try to reroute traffic onto the second best path according to BGP best path selection. As a result, operators can influence which path Autopilot will fail over to by applying BGP policy changes such as altering MED or local pref values, and this is also a very common technique.
Finally, data about whether connections were routed on paths selected by precision path or autopilot is collected by our network telemetry systems, which allows us to reconstruct what happens
Data quality auditing: We audit the quality of data fed into our automation and have configured our systems to avoid executing any change if input data is inconsistent. In the case of Autopilot, for example, we compare egress flow estimation collected via packet samples against an estimation collected via interface counters, and if they diverge beyond a given threshold it means at least one of the estimations must be wrong, and we do not apply any change. The graph below shows the difference between those two estimations during the Super Bowl on one North American POP.
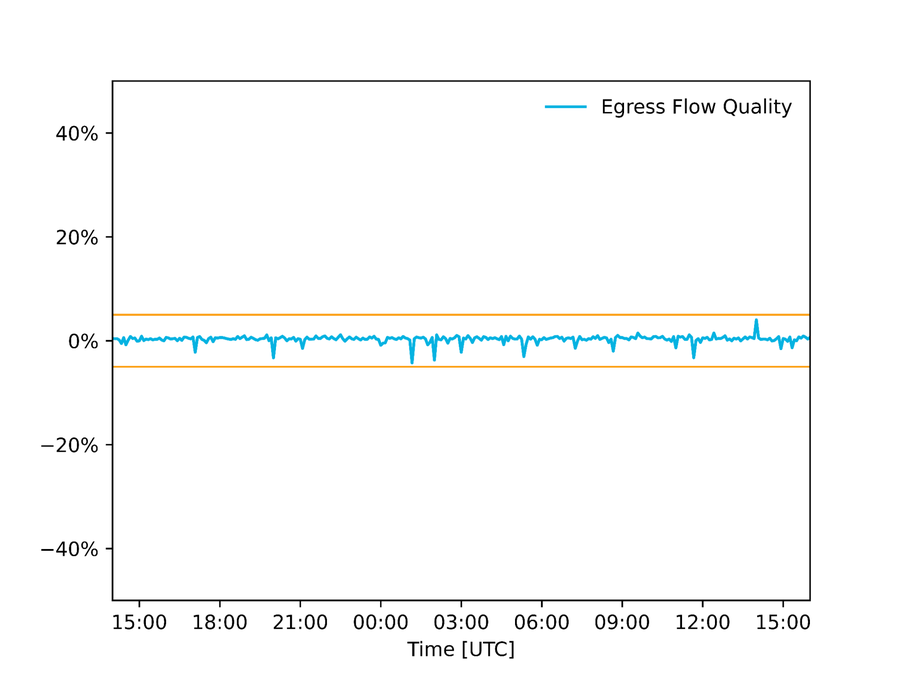
Figure - Difference between link utilization estimates obtained via interface counters and packet samples. The +/- 5% thresholds represent the acceptable margins of error
What-if analysis and control groups: in addition to monitoring input data we also audit the decisions made by systems and step in to correct them if they misbehave. Precision Path uses treatment and control groups. We randomly select a small percentage of connections to be part of a control group for which Precision Path is disabled and then monitor their performance compared to the others where precision path is enabled. If control connections perform better than treatment connections our engineering team is alerted, and steps in to investigate and remediate. Similarly, in Autopilot, before deploying a configuration change to our algorithm, we run it in “shadow” mode where the new algorithm makes decisions, but they are not applied to the network. The new algorithm will only be deployed if it performs at least as well as the one that is currently running.
Fail-static: when a failure occurs at any component of our systems, rather than failing close or open, they fail static, i.e., leave the network in the last known working configuration and alert our engineering team to investigate the problem.
Conclusions
This blog post is a view into how Fastly automates egress traffic engineering to make sure our customers’ traffic reaches their end users reliably. We continue to innovate and push the boundaries of what is possible while maintaining a focus on performance that is unrivaled. If you are thinking that you want your traffic to be handled by people who are not only experts, but also care this much, now is a great time to get in touch. Or if you’re thinking you want to be a part of innovation like this, check out our open listings here: https://www.fastly.com/about/careers/current-openings.
Open Source Software
The automation built into our network was made possible by open source technology. Open source is a part of Fastly’s heritage — we’re built on it, contribute to it, and open source our own projects whenever we can. What’s more, we’ve committed $50 million in free services to Fast Forward, to give back to the projects that make the internet, and our products, work. To make our large network automation possible, we used:
Kafka - distributed event streaming platform
pmacct - sFlow collector
goBGP - BGP routing daemon library, used to build the Autopilot route collector/injector
BIRD - BGP routing daemon running on our switches and servers.
We did our best to contribute back to the community by submitting to their maintainers improvements and bug fixes that we implemented as part of our work. We are sending our deepest gratitude to the people that created these projects. If you’re an open source maintainer or contributor and would like to explore joining Fast Forward, reach out here.