



「Fastly は他のソリューションとどう異なるのか」、「どの点が他より優れているのか」と聞かれた場合、これまではパワフルな POP</u> や先進的なアーキテクチャ</u>と答えてきました。今回はさらに一歩前進し、完全にソフトウェア定義型の先進的なネットワークだからこそ実現できる新たなイノベーションの一端をご紹介します。
今年2月に開催されたスーパーボウルの配信中、Fastly は 81.9 Tbps という記録的なトラフック</u>を処理しましたが、Autopilot 機能のおかげで、このイベント中にトラフィックを管理するために誰かがデータ送信のポリシーを操作する必要はまったくありませんでした。Autopilot は、Fastly のゼロタッチのエグレス・トラフィック・エンジニアリングの自動化システムです。Autopilot が機能していたため、このように記録的なトラフィックが発生したサービスでも手動による介入は一切不要でした。おかげで Fastly として初めて、Fastly ネットワークのトラフィック記録を更新する一方で、管理担当者の人数の削減を実現したのです。(実のところ、必要な人手はゼロでした。) Fastly のさまざまなチームに属する大勢のスタッフが共同で Fastly ネットワークの自己管理機能の改善に取り組みました。その結果、手動による介入ゼロで、障害や輻輳、パフォーマンスの低下に迅速かつより頻繁に対応できる自動化機能を備えたネットワークの構築に成功しました。
Autopilot は Fastly に多くのメリットをもたらしますが、ネットワークプロバイダーの障害や DDoS 攻撃、予想外のトラフィックスパイクなどのイベントへの対応能力が向上したことで、お客様にもより安心していただけるようになりました。もちろん、エンドユーザーへのシームレスなエクスペリエンスが損なわれることはありません。このブログ記事では、どのようにしてこの Autopilot が実現したか、またどのように効果的に機能しているかについてご紹介します。(まだ Fastly をご利用でない方はご連絡ください</u>。または無料アカウント</u>をお試しください。Fastly ネットワークは皆さまの期待にお応えします。)
ここまでたどり着くのに、長い年月にわたる多くの努力を必要としました。ちょうど3年前のブログで、2020年のスーパーボウルの配信中のトラフィックにどのように対応</u>したかについて解説しました。当時は、前バージョンのトラフィックエンジニアリングの自動化機能によって、一般的な容量のボトルネックを回避するようトラフィックがルーティングされ、非常に複雑なケースの場合のみ運用チームによる介入が必要でした。3年前は、当時の Fastly のトラフィック量とネットワークフットプリントを管理するのに、このアプローチで問題ありませんでしたが、トラフィック容量とネットワークフットプリントのスケールアップが制限されていました。人による介入は減ったものの、容量の問題が発生した際に対応するために相変わらず人員が必要だったためです。その結果、人員の雇用とオンボーディングが必要となり、それ自体がボトルネックと化していました。少なくともネットワークが拡大するのと同時に、ネットワーク運用担当者の数を増やす必要があったということです。スーパーボウルのように計画されたイベントでは、ネットワークが効果的に機能するように準備することができます。しかし、人間の神経生理学的な見地から言うと、予想外のインターネット環境の問題に対応するために真夜中に起こされた場合、常に最高のパフォーマンスを発揮できるとは限りません。
Autopilot と Precision Path で完全な自動化を実現
これらの問題を解決する唯一の方法は、プロセスから人間を完全に排除することでした。これだけで、より簡単にスケールアップが可能になるだけでなく、キャパシティと容量の問題に対してはるかに効率的に対応できるようになります。手動の介入にはコストがかかります。目の前にある問題について推論し、判断を下す人が必要になるためです。さすがにこれを延々と繰り返すわけにはいかないので、お客様のパフォーマンスに影響を及ぼすほど問題が深刻な場合にのみ人が対応することで、エネルギーを保存する必要がありました。その上、人によるアクションが行われる場合、再び同じ問題にすぐに対応せずに済むよう、また必要となる人による介入作業の量を最小限に抑えるため、大量のトラフィックが通常ルーティングされます。
A modern CDN gives you huge improvements in caching, SEO, performance, conversions, & more.
完全な自動化により、アクションのコストは実質ゼロとなり、小さな問題が発生する度、もしくは発生しそうになる度に、小規模な最適化を非常に頻繁に実施できるようになります。完全な自動化によってもたらされる正確性と反応性の向上により、高い利用率でもリンクを安全に実行し、必要に応じて迅速にトラフィックをルーティングできます。
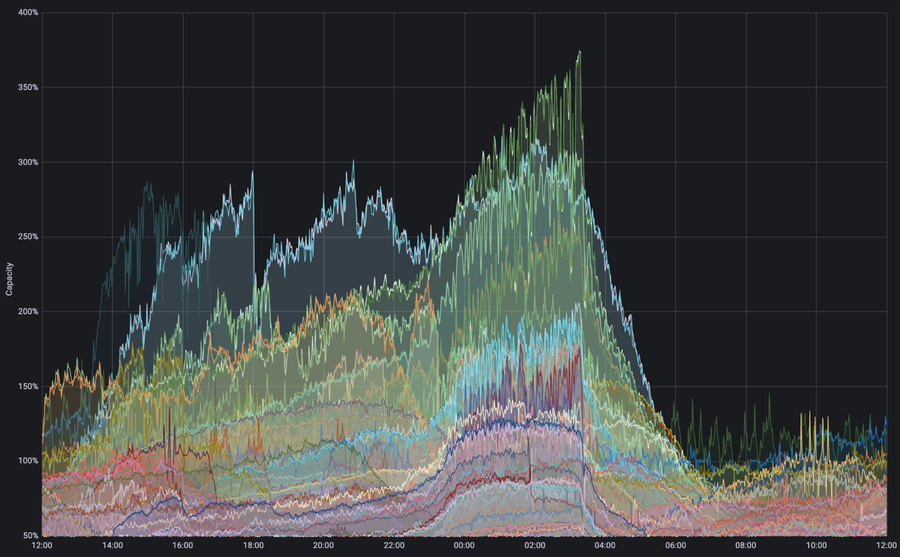
図 : 容量に対するデータ送信インターフェイスのトラフィック需要。スーパーボウルの配信中、複数のインターフェイスで利用可能な物理的容量の3倍を超えるトラフィックが発生しました。しかし、自動トラフィックエンジニアリングのオーバーライド機能がトリガーされ、ネットワークに悪影響を及ぼすことなく効率的に配信を継続することができました。
上のグラフは Autopilot によって物理的なリンク容量を超えるトラフィックの発生が検出された例を示しています。スーパーボウルの配信中、トラフィックが利用可能な容量の3倍を上回るケースもありました。Autopilot がなければ、ピークトラフィックによってこれらのリンクが過負荷の状態に陥り、障害を回避するために人による多くの介入作業を必要とし、これらの介入作業によるダウンストリームへのあらゆる影響を抑えてネットワークの効率をトップレベルに再び引き上げるため、人によるさらなる作業が必要だったでしょう。Autopilot のおかげでネットワークはトラフィックを自動的にセカンダリパスに振り分け、パフォーマンスを損ねることなく容量を超えるトラフィックに対応することができたのです。
このブログ記事では、運用チームによる介入なしに大量のトラフィック発生を処理する能力を拡大するために私たちが構築したシステムに焦点を当てます。
技術的な課題
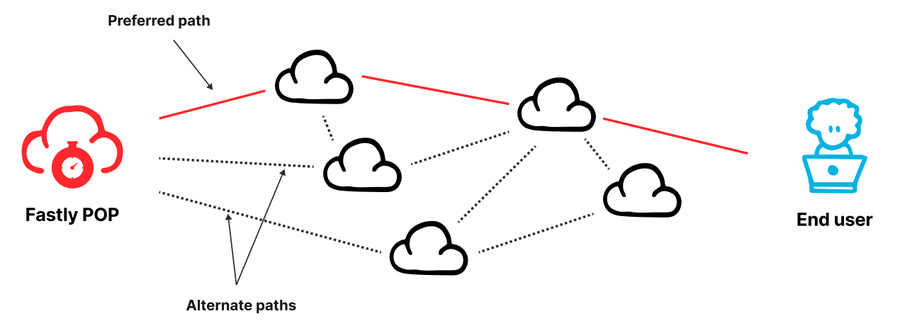
図 : Fastly の POP は、複数のピアやトランジットプロバイダーを通じてインターネットに相互接続されています。
Fastly の配信拠点 (POP) ネットワーク</u>は世界中に分散しています。各 POP はマルチホーム接続されています。すなわち、容量と信頼性を確保する目的で、ピアまたはトランジットプロバイダーで構成される複数のネットワークを経由してインターネットに相互接続されているのです。そのため、複数の利用可能なルーティングオプションの中から、どのようにして最良のパスを選択するのかというのが大きな課題でした。その時点でベストなパフォーマンスを提供できるルートを選び、障害や輻輳が発生しているパスからトラフィックを迅速に移行させる必要があります。
ネットワークプロバイダーは Border Gateway Protocol (BGP)</u> と呼ばれるプロトコルを使用して、インターネットの宛先への到達の可能性に関する情報を交換します。Fastly は BGP の更新情報をネイバーから取得し、目的の宛先にトラフィックを送信するのに使用できるネイバーを特定します。しかし BGP にはいくつかの限界があります。まず第一に、BGP は容量やパフォーマンスを把握していません。BGP は、インターネットの宛先に到達できるかどうかという情報しか伝達せず、必要な量のトラフィックを配信するのに十分な容量があるか、また配信のスループットやレイテンシはどのくらいかといった情報は提供しません。次に BGP には、離れた場所で発生した障害に対する反応が遅いという問題があります。リモートパスで障害が発生した場合、BGP によって更新が伝達されるのに通常数分かかるため、その間にブラックホールやループが発生する可能性があります。
特に1秒間に数十テラビット規模のトラフィックを処理している環境では、新たな問題を引き起こさずにこれらの問題を解決するのは至難の業です。実際、障害を回避するよう迅速にルーティングすることが望ましいのは確かですが、気を付けないと、大量のトラフィックを誤ってパフォーマンスの高いパスから低いパスへと再ルーティングしてしまい、その結果ダウンストリームで輻輳が発生してユーザーエクスペリエンスを損ねるおそれがあります。すなわち、よく注意して判断しないと、輻輳を軽減するためのアクションによって実際には (場合によっては大幅に) 輻輳が悪化する可能性があるということです。
Fastly ではこの問題を解決するため、それぞれ異なるタイムスケールで動作する2つの異なるコントロールシステムを使用し、最もパフォーマンスの高いパスにトラフィックを送信しながら迅速にルーティングして障害を回避できるようにしています。
ひとつ目のシステムは数十ミリ秒のタイムスケールで動作し (ラウンドトリップを数回行うため)、Fastly とエンドユーザー間の各 TCP 接続のパフォーマンスをモニタリングします。数回のラウンドトリップタイムで進行が見られない接続がある場合、進行が再開されるまでその接続を代わりのパスに再ルーティングします。Fastly とエンドユーザー間の接続を保護する Fastly の Precision Path</u> 機能は、このシステムがベースにあります。問題が発生している個々のフローをこのように短いタイムスケールで適切に再ルーティングすることによって、ネットワーク障害に迅速に対応します。
もうひとつのシステムは社内で「Autopilot」と呼ばれているもので、より長いタイムスケールで動作します。このシステムは毎分、リンクの残りの容量と、ネットワーク測定機能を通じて収集されたデータを基にネットワークパスのパフォーマンスレベルを推定します。そしてこれらの情報を基に、リンクが混雑する状況を回避しながらパフォーマンスを最適化できるよう、トラフィックを適切なリンクに割り当てます。このシステムでは反応時間が遅くなるものの、数分間分の高分解能のネットワークテレメトリデータに基づく、より多くの情報が考慮された決定が行われます。つまり、Autopilot によって、ダウンストリームに悪影響を及ぼすことなく安心して大量のトラフィックを移行することが可能になるのです。
そして、これら2つのシステムを連携させることで、問題に直面しているフローを正常に機能しているパスに迅速に再ルーティングしながら、安全な判断に必要なデータに基づいて、定期的に全体的なルーティング設定を調整することが可能になります。これらのシステムは24時間365日稼働していますが、特にスーパーボウルの配信中に重要な役割を果たしました。それぞれ 300 Gbps と 9 Tbps のトラフィックを再ルーティングし、これらのトラフィックが障害や輻輳が発生しているパスやパフォーマンスの低いパスに送信されるのを回避したのです。
異なるタイムスケールで動作する複数のシステムを使用して、スピードや精度、安全性においてバランスのとれたルーティングに関する決定を行うという、エグレス・トラフィック・エンジニアリングのこのアプローチは、私たちの知る限りでは業界初の業界初の試みです。このブログ記事の後半では、両システムの仕組みについて解説しますが、その前に少し脱線して、Fastly でトラフィックが Fastly POP からどのようにルーティングされているのかについてお話ししたいと思います。この点においても Fastly のアプローチは業界をリードしています。
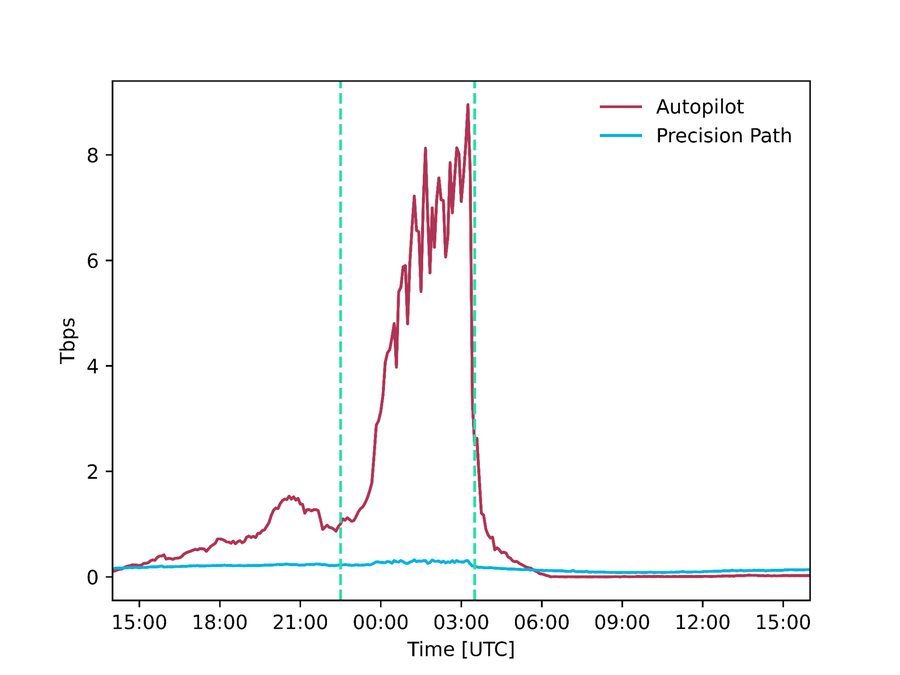
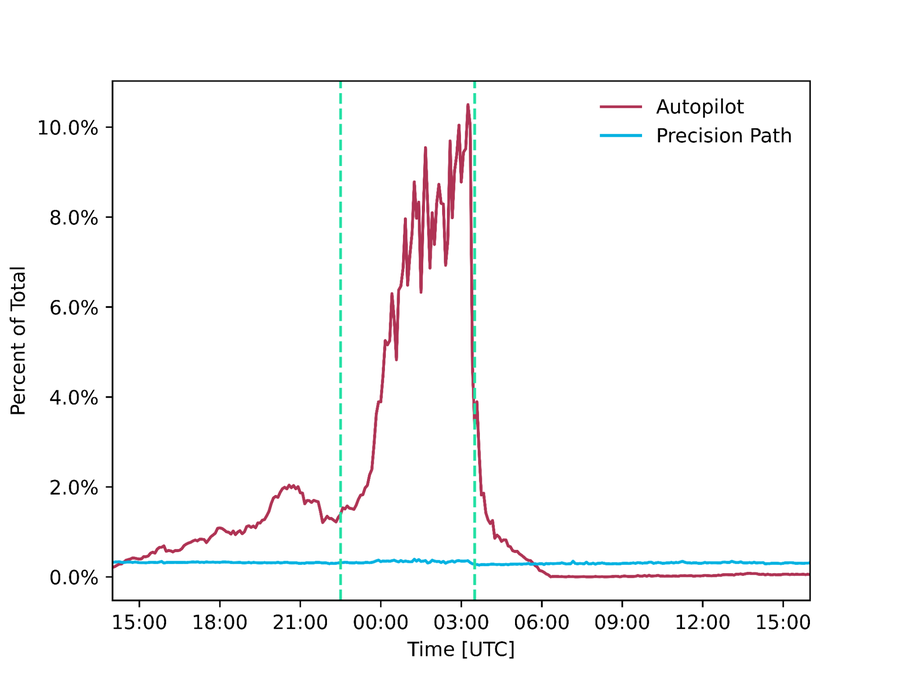
図 : スーパーボウルの配信中に Precision Path と Autopilot によってそれぞれ配信されたトラフィックの量 (絶対値と合計トラフィックに対する割合)
Fastly ネットワークのアーキテクチャ
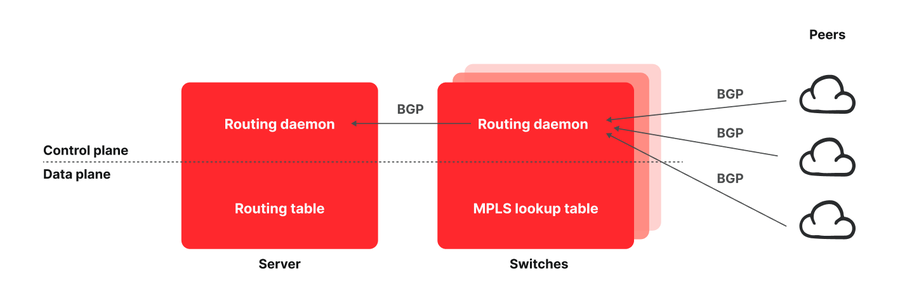
図 : Fastly POP のアーキテクチャ
典型的な Fastly の POP は、すべてのピアとトランジットプロバイダーにネットワークスイッチ経由で相互接続されているサーバーのレイヤーで構成されています。エッジクラウド POP を構築する一般的なアプローチでは、インターネット・ルーティング・テーブル全体を格納できる大きさのメモリを備えたネットワークルーターが使用されます。それとは対照的に私たちは、よりコスト効果の高いネットワークを構築するため、すべてのルートをエンドホストにプッシュしたルーティングアーキテクチャの設計を始めた</u>ところ、このアーキテクチャによって実現可能なパワフルな機能にすぐに気付き、活用しました。フローのパフォーマンスに対する可視性を備えたエンドポイントは、それをルーティングに活かすことが可能になりました。これは、ネットワーク機能、プログラミングのしやすさ、柔軟性、使いやすさにおいて、一貫して Fastly が他の製品よりも優れている主な理由のひとつです。
Fastly のルーティングアーキテクチャの仕組みを見てみましょう。スイッチとサーバーの両方がルーティングデーモンを実行しています。これらはいくつかの専用パッチが適用されている BIRD Internet Routing Daemon のインスタンスです。スイッチで動作しているデーモンは、Fastly のトランジットやピアによってアドバタイズされるすべてのルートを認識します。しかし、これらのルートをスイッチのルーティングテーブルに挿入する代わりにサーバーに伝達し、サーバーによってサーバーのルーティングテーブルにこれらが挿入されます。サーバーによって、望ましいトランジットまたはピアにトラフィックがルーティングされるようにするために、Multiprotocol Label Switching (MPLS) を使用しています。各スイッチの MPLS ルックアップテーブル (Label Forwarding Information Base [LFIB]) にエグレスポートごとに入力し、サーバーに伝達されたすべての BGP ルートアナウンスに、トラフィックのルーティングに使用される MPLS ラベルをエンコーディングするコミュニティをタグ付けします。サーバーはこの情報をルーティングテーブルに読み込み、適切なラベルを使用して POP からトラフィックをルーティングします。この詳細については、USENIX NSDI ‘21 で発表した科学論文</u>をご覧ください。
Precision Path で迅速にルーティングして障害を回避
すべてのルートをサーバーにプッシュし、トランスポートとアプリケーションレイヤーのメトリクスに基づいてエンドポイントが再ルーティングすることを可能にするアプローチは、Precision Path</u> の構築につながりました。Precision Path は数十ミリ秒のタイムフレームで動作し、パスで障害や深刻な輻輳が発生した場合にそのパスへのフローを再ルーティングします。Precision Path は、障害の発生直後にルーティングして障害を回避できるという点で優れていますが、どのパスがベストかを認識したり、最良のパスをプロアクティブに選択するための判断を行ったりすることはできません。つまり、Precision Path によって問題の回避はできるものの、大局的な視点で全体的な状況をより的確に把握し、最適化された別のルートを選択することは不可能です。Precision Path の基盤にあるテクノロジーについて詳しくは、こちらのブログ記事</u>をご覧ください。また、同業者による審査を受けたこちらの科学論文</u>でさらに詳細をご確認いただけますが、以下に簡単にご説明します。
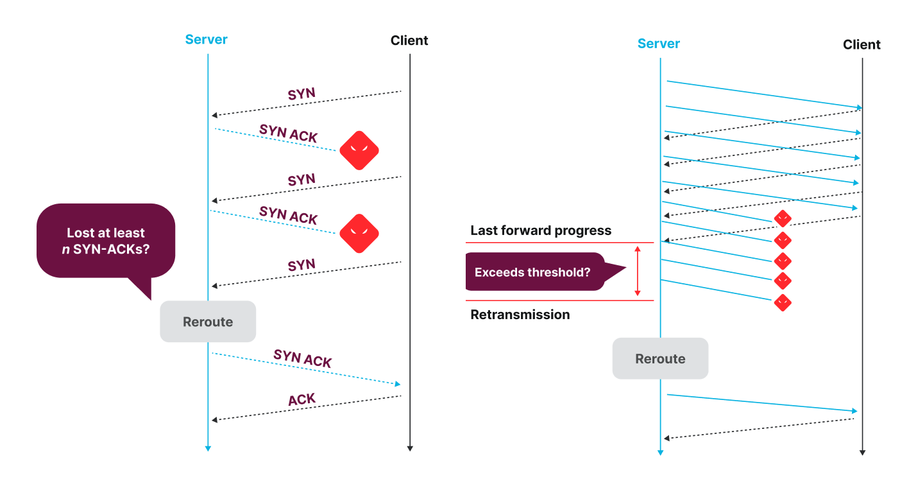
図 : 接続が確立中の場合 (左) とすでに接続が確立されている場合 (右) の Precision Path による再ルーティングにおける決定ロジック
このシステムは、Linux カーネルのパッチで、各 TCP 接続のヘルスステータスをモニタリングします。数回のラウンドトリップタイム (RTT) で進行が見られない接続では、パスに障害が発生している可能性があるため、進行が再開されるまで、ランダムに選択された代替パスに再ルーティングされます。Fastly のホストベースのルーティングアーキテクチャでは、MPLS ラベルを適用することでサーバーが送信トラフィックのルートを選択します。この仕組みのおかげで、トラフィックのフローごとに再ルーティングの決定を行うことができるのです。エンドホストがフロー単位という細かさで迅速にトラフィックを移行させることができるのは、接続の進歩状況に対する可視性とネットワークルートの選択を変更できる能力を備えているためです。このシステムは、運用チームやテレメトリに基づいて作業するトラフィックエンジニアによる対応では間に合わない短期間の障害やパフォーマンスの低下に迅速に対処する上で非常に効果的です。一方、データプレーンで確認できる深刻なパフォーマンスの低下にしか反応しない上、ランダムに選択された代替パスにトラフィックを移行するという欠点がこのシステムにはあります。選ばれたパスが正常に機能しているのは確かですが、必ずしも最適かつ最もパフォーマンスの高いパスとは限りません。
Autopilot でより多くのデータに基づく長期的な妥当性の高いルーティング決定を実現
Autopilot によって Precision Path の欠点を補うことが可能です。Autopilot は迅速な対応は得意ではありませんが、パスのパフォーマンスレベルや、現在の込み具合など、パスに関するより豊富な情報に基づいてルーティングに関する決定を行うことができます。(Precision Path のように) 単に障害のあるパスからトラフィックを遠ざけるのではなく、より大量のトラフィックをネットワークのより最適な部分に「誘導する」のです。このブログ記事では、これまで公開されていなかった Autopilot の詳細をご紹介します。
Autopilot は、パケットサンプルやリンク容量、RTT、パケットロス測定値、各宛先へのルートの可用性などのネットワークテレメトリシグナルをネットワークから受信するコントローラーです。Autopilot コントローラーは毎分、ネットワークテレメトリを収集し、その情報を基にエグレスインターフェイスごとにトラフィック需要を予測し (オーバーライドパスなし)、ひとつ以上のリンクでトラフィックが容量に達しそうになるか、ある宛先向けに現在使用されているパスのパフォーマンスが他に利用可能なパスよりも劣っている場合に、代替パスにトラフィックを再ルーティングする決定を行います。
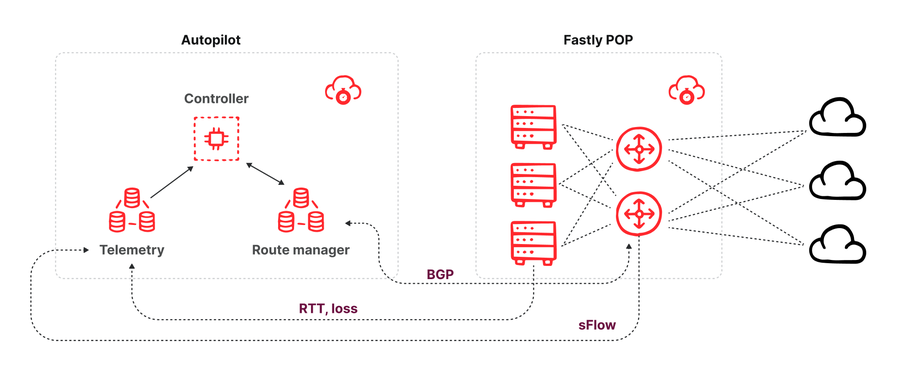
図 : Autopilot アーキテクチャの略図
上の図が示すように、Autopilot のアーキテクチャは3つのコンポーネントで構成されています。
ルートマネージャー : POP 内の各スイッチとピアリングし、スイッチが BGP ピアリングセッションを通じてネイバーから受信したルートに関するあらゆる更新情報を取得します。ルートマネージャーの API によって、コンシューマーは特定の宛先プリフィックスで使用可能なルートを把握できます。また、ルートマネージャーによって API 経由でルートのオーバーライドを挿入することもできます。これは、他のピアやトランジットプロバイダーから提供されたルートよりも高いローカル優先度の値を持つ BGP ルート更新をスイッチにアナウンスすることで実行されます。この新しいルートアナウンスは BGP のタイブレークメカニズムで優先され、サーバーのルートテーブルに挿入されてトラフィックのルーティングに使用されます。
テレメトリコレクター : POP にあるすべてのスイッチから sFlow パケットサンプルを受け取ります。すべての利用可能なプロバイダーを通じて Fastly POP 間の全トラフィックについて、宛先インターフェイスや宛先プリフィックス、レイテンシ、パケットロスの測定値ごとに、推定トラフィック量の内訳が得られます。
毎分、最新のテレメトリデータ (トラフィック量およびパフォーマンス) に加えて、特定の POP によって現在配信されているプリフィックスのために使用可能なあらゆるルートに関する情報を取り込み、BGP ルートオーバーライドを挿入してトラフィックを代替パスに誘導すべきかどうかを計算します。
Precision Path と Autopilot を連携させる
同じ入力と出力に対して動作する複数のコントロールシステムが存在する場合の課題のひとつは、これらが競合するのではなく、うまく連携し合い、総合的に見てベストなオプションが選択される仕組みを構築することです。それぞれ個別の最適化プロセスが持つ限られた視点からベストなオプションを選ぼうとすると、実際には余計な混乱が生じ、利益よりも害がもたらされる可能性があります。私たちの知る限り、こうした複数のタイムスケールを使用するアプローチをトラフィックエンジニアリングに採用しているのは、Fastly だけです。
ここでの重要な課題は、フローが Precision Path によって再ルーティングされると、Autopilot によってトリガーされるものも含め、BGP ルート更新に応答しなくなるということです。そのため、Autopilot はルーティング決定において、Precision Path によって現在コントロールされているトラフィックの量を考慮する必要があります。私たちはこの問題に2つの方法で対処しました。まず、再ルーティングするトラフィックの量を最小限に抑えるよう Precision Path を調整し、さらにそのトラフィックを Autopilot が観測できる状態にすることで、Autopilot による決定でそれが考慮されるようにしました。
最初に Precision Path をデプロイした際、誤検知を最小限に抑えるために設定を細かく調整しました。誤検知によって、一時的に小さな問題が発生したものの実は最適なパスから、パフォーマンスの低い長いパスへとトラフィックが再ルーティングされ、その結果、影響を受ける TCP 接続のパフォーマンスが悪化する恐れがあります。こちらの論文</u>で、私たちが行った設定の調整について詳しくご紹介しています。しかし、これだけでは不十分でした。接続を再ルーティングする時点ではそれが正しい決定だったとしても、再ルーティングしてから数分後に元の優先パスが回復する可能性があります。しかも BGP が発生した障害を認識し、障害があったパスを使用するルートが取り消された直後に元の優先パスが回復することがよくあるのです。優先パスが回復した際に接続をそのパスに再ルーティングするため、Precision Path は最初に再ルーティングした後、5分置きに元のパスを確認し、優先パスである元のパスが正常に機能していると判断した場合、接続をそのパスに戻します。このメカニズムはビデオストリーミングなどの長期間の接続において有効です。そうでなければ、接続期間全体を通じてバックアップパスの使用を続けることになります。また、この仕組みにより、Autopilot でコントロールできないトラフィックの量を最小限に抑えることができるため、トラフィックをより操作しやすくなるというメリットもあります。
Precision Path でルーティングされているトラフィックの量を Autopilot が把握できるようにするという課題は、簡単ではありません。上述のように、Autopilot はスイッチから出力される sFlow パケットサンプルを基に各インターフェイスを通じて送信されるトラフィックの量を把握します。これらのサンプルによって、どのインターフェイスを通じてパケットが送信されたか、どの MPLS ラベルが使用されていたかといった情報が報告されますが、MPLS ラベルがどのように適用されたかという情報は報告されません。そこで解決策として、エグレスポート向けに新たに代わりの MPLS ラベルのセットを作成し、Precision Path に限定して使用されるように割り当てました。こうすることで、Fastly の IP アドレス管理データベースで MPLS ラベルをルックアップし、パケットのルーティングが BGP によるパス選択によるものなのか、Precision Path による再ルーティングの結果なのかを迅速に見分けることができます。そしてこの情報は Autopilot コントローラーに公開されます。Autopilot コントローラーは Precision Path が再ルーティングしたトラフィックを「コントロール不可」として扱い、宛先プリフィックスの優先パスが更新されても現在のパスから動かすことができないトラフィックとして認識します。
安全な自動化
お客様とユーザーをつなぐ仲介者の役割を果たす私たちを信頼して、お客様はビジネスを委ねています。私たちはこの責任を真摯に受け止めています。ネットワークの運用を自動化することで、お客様によりシームレスなエクスペリエンスを提供するだけでなく、信頼性も保証できるようしたいと私たちは考えています。 そのため、安全性と運用のしやすさを中核に据えて自動化を設計しています。私たちのシステムは問題が発生すると効果的にフェイル機能が作動し、ネットワーク運用担当者が介入してルーティングポリシーを調整し、システムの動作をオーバーライドできるように設計されています。この最後の部分が特に重要です。運用担当者は自動化がない環境で学んだツールや手法を問題の解決に利用することができるということです。より多くの問題の解決に自動化をうまく利用して認知的なオーバーヘッドを最小限に抑えることで、忙しい状況での問題解決に要する時間を削減することが特に重要です。以下に、安全かつ操作可能な自動化を実現するために私たちが採用したアプローチをいくつかご紹介します。
標準的な運用ツール : Precision Path と Autopilot は共に、標準的なネットワーク運用ツールや手法を使ってコントロールすることができます。
個々のルートアナウンスで特定の BGP コミュニティを挿入することで、それぞれのルートで Precision Path を無効にすることができます。これは、さまざまな理由でネットワークエンジニアがよく使う手法です。また、ソケットに特定の転送マークを設定することで、それぞれの TCP セッションで Precision Path を無効にすることも可能です。これにより、Precision Path がトリガーされて結果が汚染されることなく、能動的な測定を実行することができます。
一方、Autopilot によるルートの再選択は BGP による最良パスの選択に基づいています。すなわち、BGP による選択に基づいて、2番目にベストなパスにトラフィックが再ルーティングされます。そのため、運用担当者は MED 値 や local pref 値に変更を加えるなど、BGP ポリシーに変更を適用することで、Autopilot によるフェイルオーバー先のパスの選択に影響を与えることができます。これも非常に一般的な手法です。
最後に、接続が Precision Path または Autopilot によって選択されたパスにルーティングされたかという点に関するデータが Fastly のネットワークテレメトリシステムによって収集され、このデータを基に状況を把握できます。
データ品質の監査 : Fastly では、自動化システムにフィードされるデータの質に関する監査を実施し、入力データに一貫性が無い場合、いかなる変更も実行されないようにシステムを設定しています。例えば Autopilot の場合、パケットサンプル経由で収集された送信フローの推定値を、インターフェイスカウンター経由で収集された推定値と比較し、しきい値を超える差があった場合、少なくともいずれかの値が間違っていることを意味するため、いかなる変更も適用されません。下のグラフは、スーパーボウル配信中に北米にある POP のひとつで収集されたこれら2つの推定値の差を示しています。
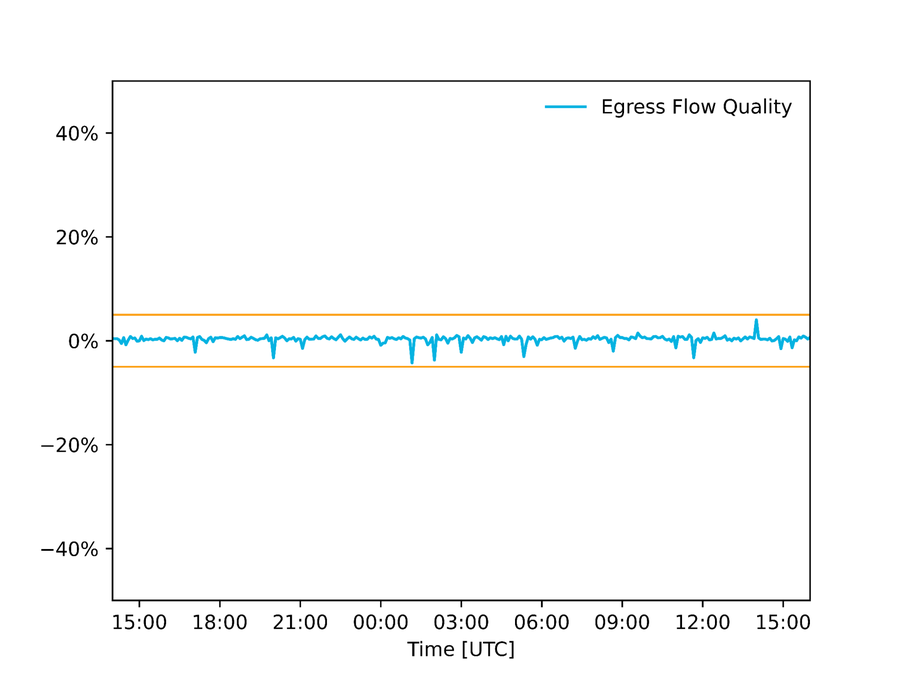
図 : インターフェイスカウンターとパケットサンプル経由で取得したリンク使用率の推定値の差。+/- 5%のしきい値は許容範囲の誤差を示しています。
What-if 分析とコントロールグループ : 入力データのモニタリングに加えて、システムによる決定を監査し、動作がおかしい場合はシステムを修正します。Precision Path では、この機能が有効化されているグループとコントロールグループが使用されます。具体的には、Precision Path を無効にするコントロールグループとして小さな割合の接続をランダムに選択し、それらの接続のパフォーマンスを Precision Path が有効化されている接続のパフォーマンスと比較しました。コントロールグループのパフォーマンスが、Precision Path が有効化されている接続を上回った場合、Fastly のエンジニアリングチームは通知を受け、問題を調べて対処します。同様に Autopilot の場合、アルゴリズムに設定変更をデプロイする前に「シャドウ」モードで実行し、このモードでは新しいアルゴリズムによって決定が行われますが、それらはネットワークには適用されません。新しいアルゴリズムは、現在使用されているアルゴリズムと少なくとも同じレベルのパフォーマンスを達成できない限り、デプロイされません。
Fail Static : Fastly システムのいずれかのコンポーネントで障害が発生すると、フェイルクローズやフェイルオープンではなく、「Fail Static」と呼ばれる対応をします。これは、最後に機能していた設定のままネットワークを維持し、通知を受けたエンジニアリングチームが問題を調査するという対処法です。
最後に
このブログ記事では、お客様のトラフィックがエンドユーザーに確実に届くよう Fastly がエグレス・トラフィック・エンジニアリングを自動化している方法についてご紹介しました。私たちは今後も、卓越したパフォーマンスの実現に注力しながら、可能性の限界を押し広げるイノベーションに取り組み続けます。ここまでパフォーマンスにこだわりのあるネットワーク専門家に自社のトラフィックを委ねたいという方は、ぜひご連絡ください</u>。また、私たちと一緒にイノベーションを実現したいという方は、以下で現在募集中のポジションをご確認いただけます。/about/careers/current-openings</u>
オープンソースソフトウェア
Fastly ネットワークに組み込まれている自動化機能は、オープンソーステクノロジーで構築されています。オープンソースは Fastly で長く受け継がれてきた伝統の一部であり、私たちはオープンソースをベースに構築し、そのコミュニティに貢献し、可能な限りプロジェクトをオープンソース化しています。さらに、Fastly Forward</u> プログラムを通じて5,000万米ドル相当の無料サービスを提供し、優れたインターネット や Fastly 製品の実現に貢献しているプロジェクトに恩返しをしています。ちなみに、Fastly の大規模なネットワークの自動化では、以下が活用されています。
Kafka</u> : 分散型イベントストリーミングプラットフォーム
pmacct</u> : sFlow コレクター
goBGP</u> : BGP ルーティングデーモンライブラリ (Autopilot ルートコレクター/インジェクターの構築に使用)
BIRD</u> : Fastly のスイッチとサーバーで実行される BGP ルーティングデーモン
私たちは、オープンソースプロジェクトのメンテナーに、Fastly の取り組みの中で実装した改良やバグ修正を提出することで、オープンソースコミュニティにできる限り貢献しています。私たちはこれらのプロジェクトを作成してくださった方々に心から感謝しています。オープンソースのメンテナーまたはコントリビューターの方で、Fastly Forward への参加にご興味のある方はこちら</u>までお問い合わせください。