
It is certainly a difficult time in the world. As the COVID-19 global pandemic continues to unfold, our priority is the health and safety of our employees, customers, and partners. We’re also ensuring that we provide the right support to our customers who rely on Fastly to help a vast number of people across the internet to create content, watch videos, read articles, and search for news and information. An essential component of that support is continuing to responsibly manage and grow our network as we adjust to working as a fully distributed team. Our approach allows us to observe, respond, and adapt to rapidly changing conditions in managing our global traffic.
In this post we’ll take you through how we’re managing our capacity, supply chain, and human capital as we navigate today’s world. You can also subscribe to updates and view our COVID-19 business continuity plans on our Status Page.
Capacity planning with headroom
Fastly has grown quickly and intentionally over the years. Our globally distributed network consists of 68 points of presence (POPs) across 26 countries on 6 continents. These POPs connect to a mix of IP transit, internet exchange points, cloud service peering, and private network interconnection totaling 74 Tbps of capacity (as of December 31, 2019).
We have long recognized that our upper bound of capacity must be sufficient to meet our customer’s upper bound of usage, and therefore we must thoughtfully build our network ahead of customer demand. We also know that conditions on the internet change at a moment’s notice, from unplanned traffic spikes to distributed denial of service attacks to carrier outages — all of which consume capacity in different ways. Our jobs are to model, plan, and deploy for those scenarios, which is why we build headroom and safety into every dimension we manage.
Our Capacity Planning Team uses a multi-dimensional approach to understand how Fastly is growing, and therefore, how much additional deployment is required. We track and trend historical utilization across our network at global, regional, and per POP levels, and create extrapolated models of future usage. We build scenarios to model traffic flows should a POP fail, or if we were to experience a failure of connectivity supporting a POP, to ensure we have sufficient regional capacity to manage overflow. Our models examine utilization patterns across multiple dimensions, including CPU usage, bandwidth usage, and a wide variety of other vectors in our systems.
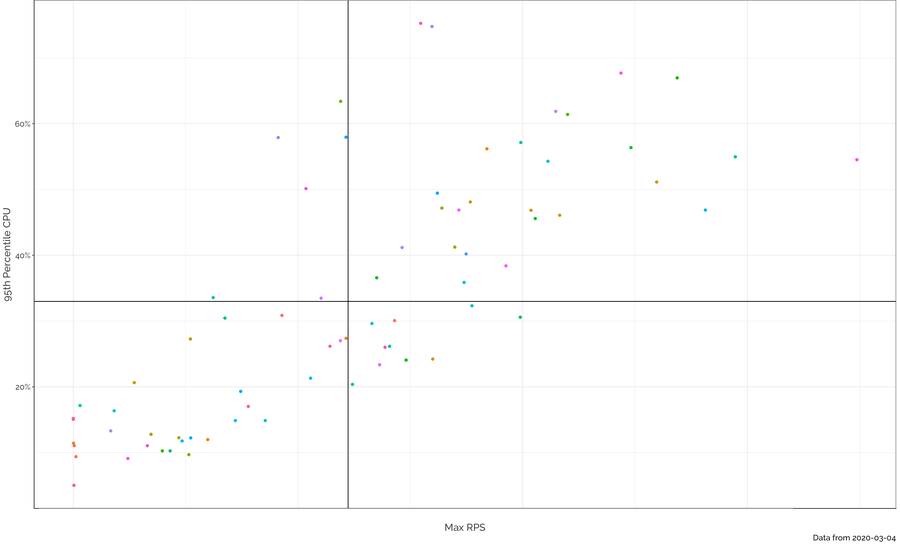
One of our many models: Correlating CPU and RPS (requests per second) on a per-server basis allows us to identify how resources in different POPs are handling the traffic load.
On a weekly basis, we check in on how our systems are doing and compare the results against our predictions, adjust our expectations of how much time we will need before the next required upgrade, and highlight areas of concern company wide so that we can thoughtfully manage growth.
The team reports any hot spots on our network so that our Edge Cloud Operations teams can take proactive mitigating actions (if not handled already by software — see Ryan’s blog about network automation). And finally, we report on abnormal usage patterns, such as spikes or DDoS events, so that teams can respond quickly.
From a planning perspective, we aggregate this data on a monthly basis to help develop our long-term forecasts. These forecasts enable us to plan future POP buildouts several months in advance, and support our capital expenditure and operational expenditure budgeting for future periods. We share the information with our hardware supply chain, network strategy, and datacenter infrastructure teams so that they can mobilize downstream activities.
Hardware supply chain management
Our hardware supply chain consists of servers, network gear, optics, fiber and copper cables, racks, and more — including massive amounts of velcro! We provide quarterly forecasts to our supply chain partners, so that they can source upstream components such as CPUs, DRAM, and SSDs on a calculated basis. Our equipment is produced and warehoused with our partners, who then integrate our racks, and deliver them to the final site of installation through a process we call Rack and Roll). When we can’t use Rack and Roll, we perform a “loose build” where our partners ship individual components to a datacenter.
We work with our supply chain partners so that we have multiple rack and loose build stock available to us at any time. This allows us to promptly dispatch racks of capacity to their final deployment location following an order. In addition, we maintain ready stocks of spare parts, such as replacement servers, switches, optics, and cables in a warehouse for our teams to self dispatch to solve repair problems in the network. We use warehouse management software to manage inventory and to establish “safe levels” of ready stock to support the maintenance cycles we incur in our business.
Back to the people: our datacenter infrastructure team
Until recently, our team of Datacenter Infrastructure Engineers were traveling the globe to deploy, maintain, and decommission Fastly infrastructure. On March 1 we suspended all non-essential travel for employees, including our datacenter infrastructure team, which meant immediate adjustments to protect our people. Fortunately, our approach already incorporates the use of local partners so that we can continue deploying and maintaining our network.
Fastly makes use of the Remote Hands services available at our colocation sites. To guide work, we produce detailed documentation for our partners to consume. For example, Rack and Roll is documented in painstaking detail, from offloading our racks on trucks, to bolt down requirements, power and inter-cabinet network cabling diagrams, to initial power up and acceptance testing. For Loose Builds, we increase the level of documentation by adding specifications about our racking and intra-cabinet cabling requirements. As a supplement to our colocation provider’s Remote Hands services, we have built a network of relationships with Managed Service Providers who can locally attend to our needs at Fastly POPs. Fastly utilizes these services when the amount of work or complexity of work exceeds the available capacity of Remote Hands, or we seek a particular consistency of work gained by sending a common team to multiple buildouts.
With data security paramount to our business practices, it is very important that we are clear in communicating expectations any time a third party interacts with Fastly equipment. Each service provider engaged in executing a Fastly deployment is vetted, and bound by contract to protect the data on our equipment. Our deployment process is structured such that no customer data, credentials, or configuration is loaded until we have assumed full control of the infrastructure. Our deployment tooling and processes verify the integrity of our hardware before any customer data, credentials, or configuration is loaded, and that the new environment is immediately compliant to Fastly’s security program. Partners are never allowed operating system access (except for initial power up and acceptance testing) nor to any layer of the stack containing our customer’s customer data, credentials, or configuration.
Maintenance activities taken on our network are fully scripted using detailed Methods of Procedure (MOPs) populated with specific activities, such as cross-connect installation, swapping bad memory out, or replacing a faulty optic. These activities are performed with Fastly staff monitoring the progress of work so we can manage security and other risks associated with vetted third parties interacting with our equipment. We can collaborate with these parties via Slack chat and Zoom video conferences to guide their work as though we’re on site, which greatly enhances our ability to quickly diagnose any issues that may arise throughout a maintenance procedure.
Similar data security concerns arise when using third party services during a scheduled maintenance event, and we apply the same level of rigor to protecting data during these procedures. For example, when swapping storage components, we follow NIST 800-88 standards to wipe or purge the affected storage device before interaction with Remote Hands. For all components, we maintain a chain of trust down to the component serial number to understand how Fastly assets are moved, changed, or accessed. And while we’d never expect a partner to purposefully deviate from our scripted maintenance procedures, we have a number of intrusion detection systems in place to allow us to detect and respond if that were ever to occur.
The people behind the process

Fastly’s Infrastructure team, together in Annapolis, Maryland for an offsite meeting in November 2018.
Capacity Planning for a network as complex and distributed as Fastly’s Edge Cloud involves far more than mathematical models and analysis. At the heart of it, it’s about people. As a team, we often reflect that the data we see is representative of how people are living their lives. It’s why deeply understanding our customers and their needs is the starting point for creating detailed plans that flow down to our teams, supply chain, and third party partners. And, it’s why we’re tremendously thankful for our team of seasoned operators. Their flexibility and resilience through these adjustments has bred creativity and innovation that we believe will live on in our culture going forward.