
これは「無駄のない脅威インテリジェンス」シリーズの第3部です。第1部と第2部はこちら。
「無駄のない脅威インテリジェンス」シリーズ第2部の基盤編では、Chef を使用してログ管理システム Graylog を構築する方法について説明しました。今回は、分析またはエンリッチ化のためにメッセージを異なるエンドポイントにルーティングできるようにする、メッセージパイプラインを作成する方法について取り上げます。Graylog のみをホストすることの制約として、Graylog インスタンスにメッセージを送信するようすべてのホストを設定する必要があり、それらのログを変更、エンリッチ化、検査することができません。このブログ記事では、以下の Fastly の元のシステム図が示すように、メッセージキューの Kafka を実装することによってその問題にどのように対処したかについて解説します。
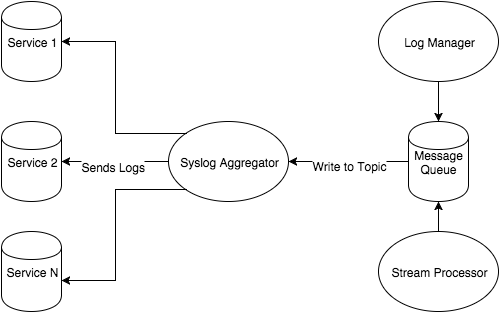
この記事では、メッセージキューが大量のデータを一元化されたポイントに移動させるのに必要なコンポーネントである理由についてご説明します。Kafka メッセージキューは単にこの目的を果たすだけでなく、ログが Gralylog に配置される前に Fastly がそのログから侵害のインジケーターを検索するのに役立ちます。
メッセージキュー
Fastly のシステム図のコンテキストでは、メッセージキューを使用することによってログをメッセージとして1つのサービスに一元化できます。このサービスには、多数の出力の可能性があることがわかります。これは、ロギングクラスターのセットアップに、以下のメリットをもたらします。
スケーラビリティ : ログ/メッセージのボリュームの増加に合わせてノードを追加し、メッセージキューのスループットを向上させることができます。
サービスの分離 : メッセージをキューから送信またはプルできます。収集が一元化されることは、データのコンシューマーやプロデューサーにとっては魅力的です。ほぼすべてがメッセージキューとの統合に依存するため、お使いのさまざまなサービスすべてとの統合を作成する必要がないためです。
論理的なパイプライン : メッセージキューからのデータを消費することに関心がある機能が多数存在する可能性があります。それらの中には、エンリッチ化または変更されたメッセージをキューに戻す必要がある場合もあれば、そのエンリッチ化されたデータを別のサービスが必要とする場合もあります。多くの依存関係を持ち混乱を招くような複雑なパイプラインを作成するのではなく、常にキューに戻るようにすることで、理解しやすいパイプラインを作成できます。
メッセージキューの詳細については、cloudamqp1 と IBM 2 が分かりやすいガイドを提供します。
多数のメッセージキューテクノロジーを検討した結果、Fastly は Kafka を採用しました。Kafka には数々の著名な企業に採用され成功を収めてきたすばらしい実績3がありますが、Fastly が Kafka を選んだ理由は、主にそのパブリッシュ/サブスクライブ型モデル4、ログクエリ戦略5、スループット6 のほか、Graylog やその他 Fastly が使用するテクノロジーとの統合が容易であったためです。これらの機能は Fastly とデータ処理量の拡張に役立ちます。Datadog7 では Kafka とその機能に関する便利なガイドが提供されていますが、ここでは Kafka ノードのスピンアップについて取り上げます。
Vagrant を使用して Kafka をデプロイする
次の行を第2部で使用した Berksfile に追加します (または Kafka でいろいろと試すために新しい行を作成します)。
cookbook 'apt'
cookbook 'runit'
cookbook 'apache_kafka'
cookbook 'zookeeper', git: 'git://github.com/evertrue/zookeeper-cookbook'上流の「apache_kafka」クックブックと、「evertrue」の「zookeeper」クックブックを使用します。これにより、Kafka の単一ノードデプロイを開始するのに十分なレシピを取得できます。
次の行を Vagrantfile に追加します。
# -* -mode: ruby -*-
# vi: set ft=ruby :
Vagrant.configure(2) do |config|
config.vm.define 'kafka01' do |kafka_config|
kafka_config.vm.box = 'ubuntu/trusty64'
kafka_config.berkshelf.enabled = true
kafka_config.berkshelf.berksfile_path = './Berksfile'
kafka_config.vm.network 'private_network', ip: '192.168.50.101'
kafka_config.vm.provider 'virtualbox' do |v|
v.memory = 512
end
kafka_config.vm.provision :chef_solo do |chef|
chef.add_recipe('apt')
chef.add_recipe('java')
chef.add_recipe('zookeeper')
chef.add_recipe('zookeeper::service')
chef.add_recipe('apache_kafka')
chef.json = {
'apt': {
'compile_time_update': true
},
'java': {
'oracle': {
'accept_oracle_download_terms': true,
},
'install_flavor': 'oracle',
'jdk_version': 8
},
'apache_kafka': {
'scala_version': '2.11',
'version': '0.9.0.0',
'checksum': '6e20a86cb1c073b83cede04ddb2e92550c77ae8139c4affb5d6b2a44447a4028',
'md5_checksum': '084fb80cdc8c72dc75bc3519a5d2cc5c'
}
}
end
end
endこれにより、Ubuntu 14.04 上に1つの virtualbox vm が作成され、「apt-get update」を介してマシンが更新されて、Java、Zookeeper、Kafka がインストールされます。各 Kafka ノードは、ノードの正常性、トピック情報、コンシューマー情報などの統計情報を Zookeeper に報告します。このリレーションシップの詳細については、Datadog の writeup7をご覧ください。
Vagrantfile と Berksfile の準備が整ったら、「vagrant up kafka01」と入力します。「vagrant ssh kafka01」を介してログインし、「sudo netstat -apunt」を実行します。これで、Zookeeper がポート2181で、Kafka がポート9092で接続をリッスンしているのがわかります。ポート2181に接続されているローカルマシンのイーサリアルポートをチェックすることで、Zookeeper への Kafka の接続を確認します。
vagrant@vagrant-ubuntu-trusty-64:~$ sudo netstat -apunt | grep 2181
tcp6 0 0 :::2181 :::* LISTEN 15745/java
tcp6 0 0 127.0.0.1:51867 127.0.0.1:2181 ESTABLISHED 15806/java
tcp6 0 0 127.0.0.1:2181 127.0.0.1:51867 ESTABLISHED 15745/java読み取りと書き込み
Kafka はログマネージャーかつメッセージキューであるため、メッセージとして格納されるログをいくつか送信してみましょう。Kafka は「publish/subscribe」と呼ばれるパラダイムを使用して、「topic」にメッセージをパブリッシュし、それをサブスクライブしてメッセージを受信します。トピックは、リーダーまたはライターが Kafka に接続するときに自動的に作成されますが、分かりやすく1つ作成してみましょう。
まず、「sudo /usr/local/kafka/kafka_2.11-0.9.0.0/bin/kafka-topics.sh --create -topic test --replication-factor 1 --partitions 1 --zookeeper localhost:2181」と入力します。
次に、「sudo /usr/local/kafka/kafka_2.11-0.9.0.0/bin/kafka-topics.sh --describe --zookeeper localhost:2181」と入力します。
以下のように表示されます。
vagrant@vagrant-ubuntu-trusty-64:~$ sudo /usr/local/kafka/kafka_2.11-0.9.0.0/bin/kafka-topics.sh --describe --zookeeper localhost:2181
Topic:test PartitionCount:1 ReplicationFactor:1 Configs:
Topic: test Partition: 0 Leader: 0 Replicas: 0 Isr: 0この出力については、Kafka website8で分かりやすく解説されています。
ここで出力について説明します。最初の行はすべてのパーティションの概要を示し、追加の行は各パーティションについての情報を提供します。このトピックには1つのパーティションのみ存在するため、1行のみとなります。「leader」は指定されたパーティションのすべての読み取りと書き込みを担うノードです。各ノードは、パーティションのランダムに選択された部分のリーダーになります。「replicas」は、リーダーかどうか、または現在アライブかどうかに関係なく、このパーティションのログをレプリケートするノードのリストです。「isr」は、「in-sync (同期された)」レプリカのセットです。これは現在ライブで、かつリーダーに同期されたレプリカのリストのサブセットです。
読み取りと書き込みの両方で Kafka とやり取りをするために、「kafkacat」の使用をお勧めします。コマンドライン「consumer/producer」にはバグが多く、「kafkacat」にはインタラクションを簡単にする、強力なコマンドライン引数ツールセットがあります。以下のスニペットは、git (必要な Kafka ライブラリ) をインストールし、コードをクローンしてビルドしてから、それを「/bin」に移動します。
sudo apt-get install git librdkafka-dev libyajl-dev -y
git clone https://github.com/edenhill/kafkacat.git
cd kafkacat
./bootstrap.sh
sudo mv kafkacat /binファイル「echo '{"msg":"foo"}' >> foo」に JSON メッセージを書き込み、それを Kafka のクラスター「kafkacat -P -b localhost -t test -p 0 foo」に書き込みます。これは、ローカルホストのブローカー、特定のトピック (この例では「test」)、パーティション、ファイル名を指定します。このメッセージをトピックから読み取るため、「kafkacat -b localhost -t test」を実行します。出力は以下のようになります。
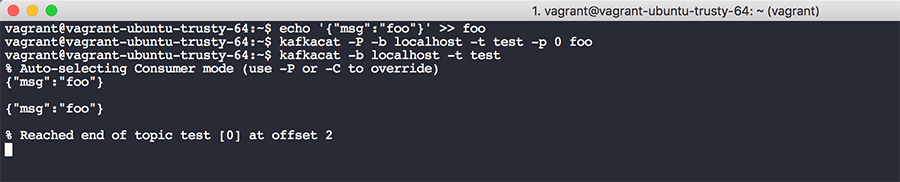
*注意 : このトピックにはテストの結果として2つのメッセージがありますが、最初の「kafkacat」コマンドを実行するごとにキューに1つのメッセージが配置されます。
この出力からいくつかのことが確認できます。キューのメッセージは、オフセット0の最初のメッセージから始まり、オフセット N の最後のメッセージまで続きます。N はそのトピックに作成されたメッセージの合計数を表します。メッセージをトピックに配置すると、メッセージキュー内でオフセットが割り当てられます。従来のコンピューターサイエンスのキューでは、一般的にオフセットを追跡または気にすることがないため、これは理解しづらいかもしれませんが、これにより Kafka が読み込みを行う際、トピックの所定のオフセットから読み込みを開始することができます。このメカニズムは、サービス停止時のデータ損失や障害の発生を防ぐのに役立ちます。コンシューマーに過去のオフセットを指定し、そこからリストの末尾までメッセージを取得させることができます。また、理論上、保持期間を長く設定して Kafka のメッセージを格納し、将来のある時点でログデータに対してフォレンジックを実行することもできます。
Kafka と Graylog
Kafka と Graylog はネイティブに連携します。Graylog で Kafka の入力を可能にし、Kafka のトピックからすぐにメッセージを取得することができます。Kafka の入力を有効にするには、「System」->「Inputs」を選択します。

「Launch new input」のドロップダウンで、「Kafka」と入力すると、Kafka の入力タイプが3つ表示されます。ここで必要なのは「Raw/Plaintext Kafka」であるため、このオプションを選択し、Zookeeper サーバーに CSV リストにあるとおりにポートを入力します。「Topic Filter Regex」に読み取り元のトピックを入力し、「Launch」をクリックします。「Show received messages」をクリックすると、Kafka のメッセージが入ってくるのを確認できます。メッセージの本文を確認し、トランスフォーマーを適用してフィールドを検索できるように設定できます。
Kafka と脅威インテリジェンスにおけるその用途
このタイプのメッセージキューは、SIEM とさまざまなログ収集エンドポイントの間の仲介役として使用できるため、脅威インテリジェンスプログラムにメリットをもたらします。ログコレクターは Kafka トピックに対してデータを生成し、SIEM はこれらの個別のトピックからデータを取得します。これにより、1種類のログで表される Kafka のトピックに検索結果を絞り込むことができるため、SIEM でのデータ検索がシンプルになります。
また、Kafka 内でのプロデューサーとコンシューマーの関係性は1対1である必要はありません。多数のコンシューマーが同じトピックを読み取ることが可能です。たとえば、セキュリティ部門と IT 部門によって取得される「ssh-logins」という Kafka トピックを設定できます。これにより IT 部門とセキュリティ部門は個別のコンシューマを使用してキューで独自のオフセットを追跡し、取得したデータで自由に好きなことができます。
最後に、データをエンリッチ化するパイプラインとして Kafka を使用できます。上記のポイントを踏まえて、SIEM 内に配置される前にデータをエンリッチ化するトピック、コンシューマー、プロデューサーのパイプラインをセットアップできます。データのエンリッチ化には、無料または商用のデータフィードに基づいて事前に収集された IP レピュテーションデータ、パッシブ DNS、ファイルハッシュ情報の追加が含まれる場合があります。さらに Kafka のコンシューマーはメッセージを読み取り、処理し、統計的な動作やクロスデバイスメッセージを確認しながら独自のアラートを生成できます。Fastly は、Graylog とその他のエンリッチ化サービスの間を仲介するメッセージキューとして Kafka を使用しています。上記のシステム図では、Kafka は「ストリーム処理」サービスと Graylog ログマネージャーの間に配置されています。
トピックを使用して、パイプラインの最後に到達するまで継続的に Kafka のデータをエンリッチ化する処理パイプラインを作成できます。これは、Graylog が取得する Kafka のトピックの1つに過ぎません。このパイプラインの一例をみてみましょう。
WAF のログ -> Syslog -> Kafka に送信 -> IP アドレスを抽出 -> 脅威インテリジェンスデータベースによるエンリッチ化 -> Kafka に戻す -> Graylog に送信
WAF のログ (ブロックされたユーザーエージェントの文字列のログなど) からの syslog メッセージは、Kafka のトピック「waf-logs」に送信できます。コンシューマーは「waf-logs」にサブスクライブし、正規表現を使用してそのブロックされたログから IP アドレスを取り出すことができます。その同じコンシューマーは、データベースに対してクエリを実行し、ユーザーエージェント/IP の組み合わせを取り巻くレピュテーションコンテキストを使用して、WAF のログをエンリッチ化できます。コンシューマーはエンリッチ化されたログを別のトピック「enriched-waf-log」に送信し、Graylog はそのログを取得し、インデックスに追加できます。最後に、「enriched-waf-log」から取得されたメッセージに対してアラートを発信するように Graylog を設定できます。これで Graylog のレコードがそのイベントを取り巻く関連性の高い豊富な情報を有するようになり、運用チームのメンバーがそのイベントにより簡単に対応できるようになります。
次のステップ : Kafka へのログの送信
Kafka レシピを Berksfile に読み込み、Kafka ボックスの Vagrant の定義も設定されているので、Graylog のインスタンスで Kafka の入力を有効にできるほか、Graylog 内のデータを検査し、変換を適用してメッセージを抽出することで、それらを Graylog で簡単に検索できるようすることができます。
次の記事では、syslog ホストから Kafka にログを簡単に送信する方法についてご説明します。Kafka にログを送る方法を決めることは、それ自体が冒険となる可能性があります。トピックにデータを書き込む syslog プラグインやコードライブラリは存在しますが、転送中のログのセキュリティについても考慮する必要があります。Fastly はログを Kafka に送信し、表示可能な形式に変換するのに Filebeat と Logstash を活用しています。これにより、下流の Kafka コンシューマーがログから関連するデータを抽出してエンリッチ化を実行し、Graylog での検索が容易になります。ご期待ください !
参照リンク
1 https://www.cloudamqp.com/blog/2014-12-03-what-is-message-queuing.html
2 https://www.ibm.com/support/knowledgecenter/SSFKSJ_8.0.0/com.ibm.mq.pro.doc/q002620_.htm
3 https://cwiki.apache.org/confluence/display/KAFKA/Powered+By
4 http://kafka.apache.org/documentation.html#intro_topics
5 http://kafka.apache.org/documentation.html#uses_logs
7 https://www.datadoghq.com/blog/monitoring-kafka-performance-metrics/
8 http://kafka.apache.org/081/quickstart.html
9 http://kafka.apache.org/documentation.html#intro_distribution