

これは「無駄のない脅威インテリジェンス」シリーズの第2部です。第1部と第3部はこちら。
「無駄のない脅威インテリジェンス」シリーズ第1部の計画編では、Fastly の Threat Intelligence チームがプロジェクトを計画するのに使用する一般的なワークフローについて説明しました。例として、Fastly のすべてのサービスからログをまとめて蓄積する一元的な Syslog アグリゲーターを取り上げました。今回はこのトポロジーを使用してシステム図の先に進み、次のステップであるテクノロジーの選択について解説します。
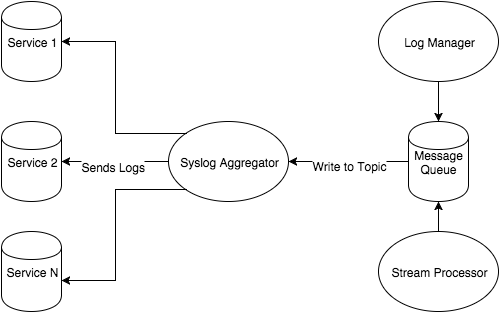
前回の記事では、この環境にすでに syslog アグリゲーターサーバーがあることを前提としていました。このケースでは rsyslog サーバーであり、さらに分析できるようにディスク上にログのコレクションがあります。さらに分析するというのは、「grep A.B.C.D. foo.log」の実行であってはなりません。人間がこのように大量のデータを直感的に確認できるようにする優れたテクノロジーを存分に活用すべきです。ここでログマネージャーの出番です。
「われら種を播かず」- Graylog 家の紹介
ログ管理テクノロジーを選択する際、ログをどのように管理するかについてインフラストラクチャの観点からいくつかの決定を行う必要があります。皆さんに代わってこのインフラストラクチャを管理する SaaS プロバイダーに加えて、ユーザーがインフラストラクチャを詳細にコントロールできるオープンソースのログマネージャーもあります。テクノロジーの選択は、予算、インフラストラクチャの管理に必要な人員、ポリシーを含むリソースの条件に基づいて行われます。SaaS プロバイダーに予算を費やすべきか検討し、そのようなサービスを利用せずオープンソーススタックを使用する場合、人員やインフラストラクチャの面でより多くのコストがかかる可能性を考慮しなければなりません。また、自社が所有していないインフラストラクチャに重要なログや監査データをホストすべきかという問題もあります。
Fastly でも同様の決定プロセスを経て、Graylog をログ管理テクノロジーとして採用することにしました。理由は以下のとおりです。
重要なログへのアクセスを制限し、それらのセキュリティを管理することで、攻撃対象となるリスクを軽減したい。
セキュリティチームと緊密に連携し、本番環境のインフラストラクチャを管理するチームが存在する。
Graylog は評判の高い Elasticsearch のテクノロジースタックを使用し、ログのインデックス作成と検索を容易にできる。
Graylog には Web サーバーのフロントエンドに Kibana の競合製品もあり、アカウント管理やメール/PagerDuty によるネイティブなアラート発信などの便利な機能が備わっている。
所属するチームに基づいて複数のユーザーがログのサブセクションを閲覧するためのアクセスコントロールメカニズムとして Graylog のストリーム機能を活用できる。これにより、セキュリティチームだけでなく、複数のチームがシステムを利用できるようになる。
Graylog にログを送信することで、前回の記事で触れたユーザーストーリーの1と2を解決できます。特に Graylog はよく管理され、関連する文書が豊富にあり、Fastly の制約を満たす魅力的な選択肢であるため、Graylog の採用は私たちチームにとって大きなメリットがありました。
Graylog を選択したところで、次はそれをデプロイし、アグリゲーターから Graylog に syslog メッセージを送信する必要があります。その方法は以下のとおりです。
船の人員配置 : Chef/Vagrant を使用して Graylog をデプロイする
幸いなことに Graylog サーバーはほぼすべてを内蔵し、外部依存関係として使用しているのは Elasticsearch と MongoDB のみです。Elasticsearch は Graylog によってインデックスされたすべてのデータが格納される Lucene インデックスで、MongoDB は Graylog 設定用のデータベースを提供し、MongoDB レプリケーションで複数の Graylog サーバーを実行する際に特に重要です。
Graylog ウェブフロントエンドには外部依存関係が一切なく、Graylog Server API にのみ依存します。
シンプルにするため、ここでは Vagrant と Chef Solo を使用して Graylog サーバーを立ち上げます。これにより、Chef サーバーに頼ることなく「chef-client」機能セットを活用できます。また、公開されている Chef のレシピを利用し、使用する Graylog クラスターを迅速にブートストラップします。
クラスターは一から構築します。Java、Elasticsearch、MongoDB から始め、最後に Graylog サーバーと Graylog Web です。
では、Elasticsearch をインストールしましょう。
Berksfile は Chef のクックブックの依存関係を管理し、Vagrant にレシピの場所を知らせます。このケースでは、Java に固有の要素を定義しないので、Java クックブック用の supermarket.chef.io が検索されます。
次に Vagrantfile で、Vagrant とそれに続いて Chef に、ノードをデプロイしてプロビジョニングする方法を伝えます。この例では、「chef.add_recipe」を使用して Java と Elasticsearch のラッパーレシピを Chef の実行に追加します。さらに、そのレシピの基本設定のいくつかを「chef.json」ブロックで指定します。Java セクションでインストールする Java のバージョン (この例では Oracle 8) を指定し、ダウンロード条件を受け入れるようにします。残念ながら、Vagrant によってプライマリインターフェイスがホストのみのネットワークに設定されるため、セカンダリインターフェイスでリッスンするよう Elasticsearch を設定する必要があります。幸いなことに、これは Vagrantfile に数行を追加するだけで済みます。
Berksfile
source "https://supermarket.chef.io"
cookbook 'java'
cookbook 'elasticsearch', git: 'https://github.com/elastic/cookbook-elasticsearch.git'
cookbook 'blog_elasticsearch', path: '~/cookbooks/blog_elasticsearch'ここでは https://supermarket.chef.io にソーシングし、Chef にローカルパスで見つからないクックブックを取得するよう伝えます。java は supermarket から、elasticsearch は git から、blog_elasticsearch はローカルでプルされます。blog_elasticsearch のパスについては気にしないでください。次のステップでクックブックの例を作成します。
Vagrantfile
es_servers = { :elasticsearch1 => '192.168.33.30',
:elasticsearch2 => '192.168.33.31',
:elasticsearch3 => '192.168.33.32'
}
es_servers.each do |es_server_name, es_server_ip|
config.vm.define es_server_name do |es_config|
es_config.vm.box = "ubuntu/trusty64"
es_config.vm.network "private_network", ip: es_server_ip.to_s
es_config.vm.provider "virtualbox" do |v|
v.memory = 1024
v.cpus = 2
end
es_config.vm.hostname = es_server_name.to_s
es_config.vm.provision :chef_solo do |chef|
chef.add_recipe "java"
chef.add_recipe "blog_elasticsearch"
chef.json = {
:java => {
:oracle => {
:accept_oracle_download_terms => true
},
:install_flavor => "oracle",
:jdk_version => "8"
},
:elasticsearch => {
:configuration => {
:network_host => es_server_ip.to_s,
}
}
}
end
end
end次は、Elasticsearch ラッパーを作成します。クックブックのディレクトリで次のコマンドを実行します。
chef generate cookbook blog_elasticsearchこれによりスケルトンクックブックが作成され、変更を加えることができます。クックブックを機能させるには、「metadata.rb」と「recipes/default.rb」を変更する必要があります。
metadata.rb
depends 'java'
depends 'elasticsearch'recipes/default.rb
elasticsearch_user 'elasticsearch'
elasticsearch_install 'my_es_installation' do
type :package # type of install
version '1.7.3'
action :install # could be :remove as well
end
elasticsearch_configure 'elasticsearch' do
configuration ({
'cluster.name'=> 'graylog2',
'network.host'=> node[:elasticsearch][:configuration][:network_host] || node['ipaddress'],
'discovery.zen.ping.multicast.enabled'=> true,
'discovery.zen.minimum_master_nodes'=> 1
})
end
elasticsearch_service 'elasticsearch' do
action :start
endこのクックブックにより java と elasticsearch のレシピが上流からプルされるので、独自のデフォルトのレシピを作成して基本的な設定オプションを設定します。Graylog は接続先のクラスター名を必要とするため、このクラスターを graylog2 と名付けます。次に、elasticsearch のネットワークホストを、このクックブックを使用している誰かによって設定された IP アドレス、またはそれが提供されていない場合は、そのノードの IP アドレスに設定します。最後に、このクラスターを起動させるために、1つのマスターノードのみを決めます。
Elasticsearch の準備が整ったので、これで Graylog のインストールを開始できます。Graylog サーバーから始めましょう。既存の Berksfile に「cookbook ‘graylog2'」を追加します。
Berksfile
source "https://supermarket.chef.io"
cookbook 'java'
cookbook 'elasticsearch', git: 'https://github.com/elastic/cookbook-elasticsearch.git'
cookbook 'blog_elasticsearch', path: '~/cookbooks/blog_elasticsearch'
cookbook 'graylog2'次に、elasticsearch ブロックの後に以下のコードを追加します。
Vagrantfile
config.vm.define "graylog-server" do |graylogserver|
graylogserver.vm.box = "ubuntu/trusty64"
graylogserver.vm.network "private_network", ip: "192.168.33.20"
graylogserver.vm.network "forwarded_port", guest: 1514, host: 1514, protocol: "tcp"
graylogserver.vm.network "forwarded_port", guest: 1514, host: 1514, protocol: "udp"
graylogserver.vm.provider "virtualbox" do |v|
v.memory = 1024
v.cpus = 2
end
graylogserver.vm.hostname = "graylog-server"
graylogserver.vm.provision :chef_solo do |chef|
chef.add_recipe "java"
chef.add_recipe "blog_elasticsearch"
chef.add_recipe "mongodb"
chef.add_recipe "graylog2"
chef.add_recipe "graylog2::server"
chef.json = {
:java => {
:oracle => {
:accept_oracle_download_terms => true
},
:install_flavor => "oracle",
:jdk_version => "8",
},
:graylog2 => {
:password_secret => "", # pwgen -s 96 1
:root_password_sha2 => "", # echo -n yourpassword | shasum -a 256 | awk '{print $1}'
:elasticsearch => {
:discovery_zen_ping_unicast_hosts => '192.168.33.20:9300',
:network_host => '192.168.33.20'
},
:rest => {
:transport_uri => 'http://192.168.33.20:12900/',
:listen_uri => 'http://192.168.33.20:12900/'
},
:server => {
:java_opts => "-Djava.net.preferIPv4Stack=true"
}
},
:elasticsearch => {
:configuration => {
:network_host => "192.168.33.20",
}
}
}
end
endVagrantfile の Graylog の部分は複雑に見えますが、graylog2-cookbook により、変数をより柔軟に定義できます。Graylog は Elasticsearch と Java に依存しているため、Vagrantfile の大部分は同じように見えます。Graylog のオプションの残りは、Graylog を適切なインターフェイスにバインドし、Elasticsearch クラスターと通信できるようにします。「chef.json」のブロック内を順番に見ていくと、このクラスターに固有の変数を設定していることがわかります。「graylog2」の2つのパスワードはすぐに生成される必要がありますが、後で変更できます。次に、ES ノードを検出できるように、Graylog のユニキャストホストをセットアップします。最後に REST API を設定し、Graylog の Web サーバーがそれに通信できるようにします。
最後に Graylog Web をインストールします。
config.vm.define "graylog-web" do |graylogweb|
graylogweb.vm.box = "ubuntu/trusty64"
graylogweb.vm.network :private_network, ip: "192.168.33.10"
graylogweb.vm.network "forwarded_port", guest: 9000, host: 9000, proto: "tcp"
graylogweb.vm.provider "virtualbox" do |v|
v.memory = 1024
v.cpus = 2
end
graylogweb.vm.hostname = "graylog-web"
graylogweb.vm.provision :chef_solo do |chef|
chef.add_recipe "java"
chef.add_recipe "graylog2"
chef.add_recipe "graylog2::web"
chef.json = {
:java => {
:oracle => {
"accept_oracle_download_terms" => true
},
:install_flavor => "oracle",
:jdk_version => "8",
},
"graylog2": {
"password_secret": "", # pwgen -s 96 1
"root_password_sha2": "", # echo -n yourpassword | shasum -a 256 | awk '{print $1}'
"web": {
"secret": "",
:server_backends => 'http://192.168.33.20:12900',
:timezone => "Etc/UTC"
}
}
}
end
endこれは Vagrantfile のセクションの中で最も小さいものです。Graylog Web サーバーは Graylog Server API 上のインターフェイスに過ぎないためです。管理者ユーザーのシークレットを指定し、Web ノードとサーバーノードが通信できるようにする必要があります。
Vagrantfile とラッパークックブックを作成したら、ターミナルで「vagrant up」を実行すると、クラスターが起動します。これには数分かかるので、しばらくお待ちください。
vagrant up が完了し、ポート9000の Web インターフェイスに移動すると (この例では http://192.168.33.10:9000)、次のログイン画面が表示されます。
ユーザー名は「admin」、パスワードは「echo -n yourpassword | shasum -a 256 | awk '{print $1}」コマンドで生成されたパスワードになります。
ログイン後にデータをリッスンする入力を作成する必要があります。「System」>「Inputs」で、新しい Syslog UDP の入力を作成します。ここでは単一ノードの Graylog サーバーのみ存在するため、スポーンするノードは1つだけです。入力のタイトルを指定し、Graylog は特権ユーザーとして実行されていないため、ポートを1024より上に変更します。入力は以下のようになります。
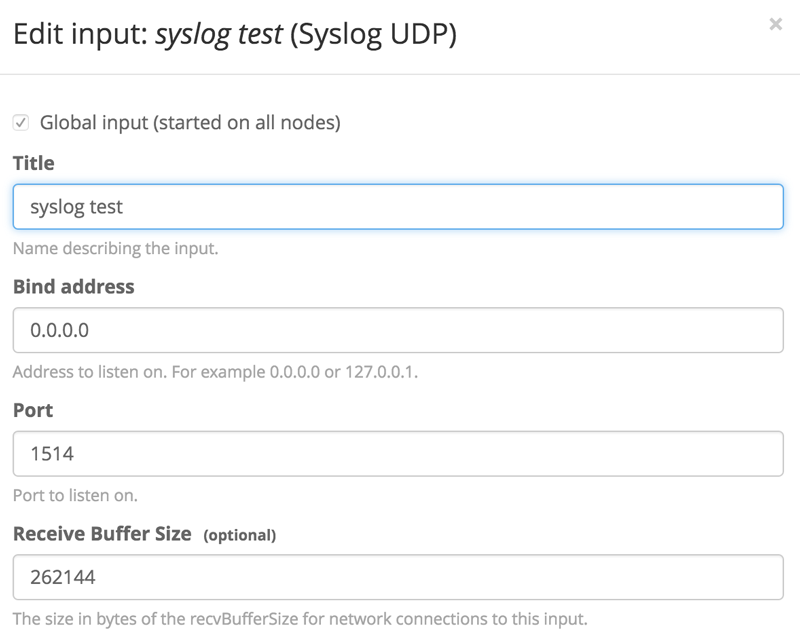
「launch」をクリックし、入力が正常に起動することを確認します。入力名の横に緑色の実行中のステータスが表示されます。
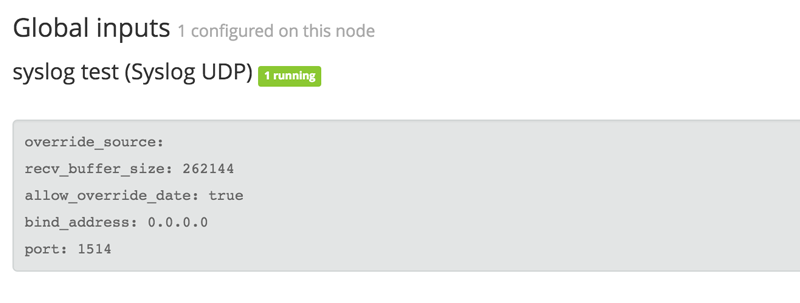
次に、デプロイをテストするため、Graylog に送信するテストデータをいくつか生成する必要があります。コマンドラインで、コマンド「nc -w0 -u 192.168.33.20 1514 <<< “Test Syslog Message”」を実行します。「search」をクリックすると、このデータがクラスターに入力されているのを確認できます。
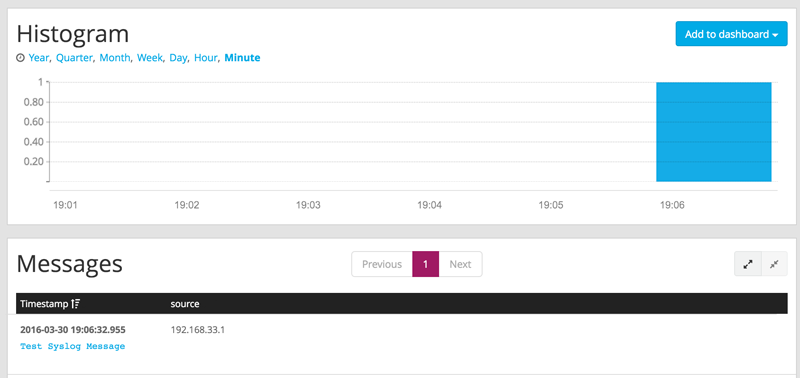
メッセージをクリックすると、Graylog から詳細情報を取得できます。
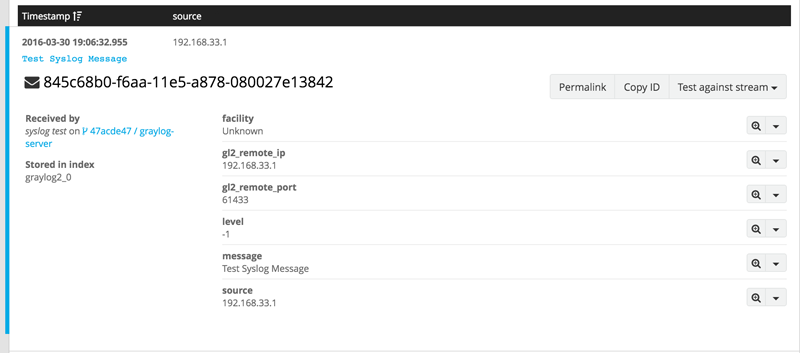
ご覧のとおり、Graylog によって syslog メッセージがインデックスされ、解析されます。Graylog はほとんどの入力でこれを実行し、Syslog に対して非常に優れたパフォーマンスを発揮します。この syslog メッセージの例にはあまり多くの情報は含まれていませんでしたが、rsyslog を Graylog の仮想ボックスマシンにポイントし、いくつかのテストメッセージを試して、Graylog の解析機能を活用できます。
Vagrantfile にはローカルの VirtualBox を介したセットアップが表示されていますが、運用環境のデプロイには適していません。幸いなことに、Vagrant には Google Compute Engine や EC2 などのクラウドサービスのためのプロバイダーが存在し、Docker や Hyper-V のサポートも組み込まれています。
Vagrantfile の全文は、このブログ記事の最後で確認できます。
基盤で構築 : メッセージキュー
この Vagrantfile とセットアップにより、システム図のログマネージャーの要件を完了しました。syslog メッセージに対して tail と grep を実行する代わりに、syslog アグリゲーターを使用してログを Graylog のデプロイに転送できます。その後、Graylog のアラートスキームを利用するか、Elasticsearch にフックして構造化データ形式を利用し、オフライン分析を実行できます。
このログマネージャーのセットアップは、サービスの停止やセキュリティインシデント発生後の事後検証など、ログの調査を必要とするプロセスを合理化するのに役立ちます。脅威インテリジェンスプログラムでは、インフラストラクチャやデータの可視性を犠牲にすることなく、手動のプロセスを可能な限り排除することが重要です。Graylog がネイティブで提供するダッシュボード、検索保存機能、アラート機能により、脅威インテリジェンスの合理化という目標に近づくことができます。
このセットアップにはいくつかの問題があります。まず第一に、検索に役立つエンリッチ化のメカニズムがありません。たとえばこのようなメカニズムによって、SSH でのログイン試行のログを記録し、その後 DNS および IP レピュテーションの逆引きを行い、失敗したログイン試行が悪意のある試行の場合により高いステータスに昇格させることができます。次に、syslog メッセージのノイズが多すぎて関連するシグナルを見失う可能性があります。ストリームプロセッサーのようなシグナルの抽出をサポートするものがないと、テレメトリの状態に関する重要な情報が失われるおそれがあります。
システム図のメッセージキューの部分での対処方法ついては、このシリーズの第3部をご覧ください。メッセージキューは、以下を行うことでこのセットアップに役立ちます。
個別のハイウェイとフロー上で複数のデータストリームを管理することで、それらのフロー上で抽出または検索を実行する Graylog の機能を強化できます。
ストリームを処理するアーキテクチャにデータをフィードする仲介者として機能し、データのエンリッチ化と分析に役立ちます。
アラートストリームを管理できます。特定のストリームを通じて入ってくるデータについて即座にアラートを発信するよう Graylog を設定することで、複雑なアラートシナリオを Graylog からオフロードできます。
ご期待ください !
付録
Berksfile
source "https://supermarket.chef.io"
cookbook 'elasticsearch', git: 'https://github.com/elastic/cookbook-elasticsearch.git'
cookbook 'java'
cookbook 'fst_elasticsearch', path: '~/cookbooks/fst_elasticsearch'
cookbook 'graylog2'Vagrantfile
Vagrant.configure(2) do |config|
config.vm.box = "ubuntu/trusty64"
config.berkshelf.enabled = true
if Vagrant.has_plugin?("vagrant-cachier")
config.cache.scope = :box
end
es_servers = { :elasticsearch1 => '192.168.33.30',
:elasticsearch2 => '192.168.33.31',
:elasticsearch3 => '192.168.33.32'
}
es_servers.each do |es_server_name, es_server_ip|
config.vm.define es_server_name do |es_config|
es_config.vm.box = "ubuntu/trusty64"
es_config.vm.network "private_network", ip: es_server_ip.to_s
es_config.vm.provider "virtualbox" do |v|
v.memory = 1024
v.cpus = 2
end
es_config.vm.hostname = es_server_name.to_s
es_config.vm.provision :chef_solo do |chef|
chef.add_recipe "java"
chef.add_recipe "blog_elasticsearch"
chef.json = {
:java => {
:oracle => {
:accept_oracle_download_terms => true
},
:install_flavor => "oracle",
:jdk_version => "8"
},
:elasticsearch => {
:configuration => {
:network_host => es_server_ip.to_s,
}
}
}
end
end
end
config.vm.define "graylog-server" do |graylogserver|
graylogserver.vm.box = "ubuntu/trusty64"
graylogserver.vm.network "private_network", ip: "192.168.33.20"
graylogserver.vm.network "forwarded_port", guest: 1514, host: 1514, protocol: "tcp"
graylogserver.vm.network "forwarded_port", guest: 1514, host: 1514, protocol: "udp"
graylogserver.vm.provider "virtualbox" do |v|
v.memory = 1024
v.cpus = 2
end
graylogserver.vm.hostname = "graylog-server"
graylogserver.vm.provision :chef_solo do |chef|
chef.add_recipe "java"
chef.add_recipe "blog_elasticsearch"
chef.add_recipe "mongodb"
chef.add_recipe "graylog2"
chef.add_recipe "graylog2::server"
chef.json = {
:java => {
:oracle => {
:accept_oracle_download_terms => true
},
:install_flavor => "oracle",
:jdk_version => "8",
},
:graylog2 => {
:password_secret => "", # pwgen -s 96 1
:root_password_sha2 => "", # echo -n yourpassword | shasum -a 256 | awk '{print $1}'
:elasticsearch => {
:discovery_zen_ping_unicast_hosts => '192.168.33.20:9300',
:network_host => '192.168.33.20'
},
:rest => {
:transport_uri => 'http://192.168.33.20:12900/',
:listen_uri => 'http://192.168.33.20:12900/'
},
:server => {
:java_opts => "-Djava.net.preferIPv4Stack=true"
}
},
:elasticsearch => {
:configuration => {
:network_host => "192.168.33.20",
}
}
}
end
end
config.vm.define "graylog-web" do |graylogweb|
graylogweb.vm.box = "ubuntu/trusty64"
graylogweb.vm.network :private_network, ip: "192.168.33.10"
graylogweb.vm.network "forwarded_port", guest: 9000, host: 9000, proto: "tcp"
graylogweb.vm.provider "virtualbox" do |v|
v.memory = 1024
v.cpus = 2
end
graylogweb.vm.hostname = "graylog-web"
graylogweb.vm.provision :chef_solo do |chef|
chef.add_recipe "java"
chef.add_recipe "graylog2"
chef.add_recipe "graylog2::web"
chef.json = {
:java => {
:oracle => {
"accept_oracle_download_terms" => true
},
:install_flavor => "oracle",
:jdk_version => "8",
},
"graylog2": {
"password_secret": "", # pwgen -s 96 1
"root_password_sha2": "", # echo -n yourpassword | shasum -a 256 | awk '{print $1}'
"web": {
"secret": "",
:server_backends => 'http://192.168.33.20:12900',
:timezone => "Etc/UTC"
}
}
}
end
end
end