
At Fastly, we’re always working to make our systems faster and more reliable. One of the more difficult problems we’ve faced is efficient cache invalidation across our global network, or as we call it: Instant Purging™. When content changes, our customers issue a purge request, which we then need to deliver to each of our cache servers. The system that handles these purge requests is codenamed Powderhorn.
We recently deployed a new version of this system which delivers purges faster and more reliably, even during major network problems. In this post, we'll take a deep dive into the design, implementation, and real-world behavior of Powderhorn version 2.
Designing a Purging System
When designing the next version of Powderhorn, we did what any good engineer would do: rolled up our sleeves, put on a pot of coffee, and sat down to read some papers and think about the problem. At first, there were two obvious ways to build it: a centralized system or a decentralized system. Each seemed to have tradeoffs.
Since a centralized system would be easier to build, we considered it first. For example, if the API received a purge, it would be sent to a central queue. A worker would then take the purge off the queue and send a message to all servers to remove the content. Although straightforward, this system would be a single point of failure. During network outages, it might be unable to communicate with some cache servers for an extended period of time.
A decentralized system, one where cache servers are responsible for distributing purges themselves, would be more reliable. The system would be available as long as a customer could reach any Fastly server. Purges would even be faster, because customers could send a purge to the nearest server, and from there it would be sent directly to all other cache servers.
Unfortunately, a decentralized system is harder to build. Issuing purges from cache servers adds complexity to the system. Servers may be temporarily unable to talk to each other, or the network could lose or delay messages. We see these sorts of problems regularly, so we needed a system robust enough to handle them.
Bimodal Multicast: the theory behind Powderhorn
After researching multiple reliable broadcast protocols, we eventually settled on Bimodal Multicast (Birman et. al. 1999). This protocol is fast, understandable, guarantees that messages will be eventually delivered, and has been thoroughly tested. In later sections, we’ll show examples of this behavior. Before we do that, we’ll go into some of the theory behind Bimodal Multicast.
Bimodal Multicast solves the problem of reliable message distribution with two separate strategies. When a message first arrives at some server, the receiving server broadcasts the message to all its peers. While this phase is unreliable, it is highly efficient. In order to handle the possibility of messages being lost, servers periodically share information about received messages in a process commonly known as a gossip protocol. At regular intervals, a server will send a summary of messages it has received so far to a randomly selected peer. This peer then checks the summary and requests any messages they may have missed.
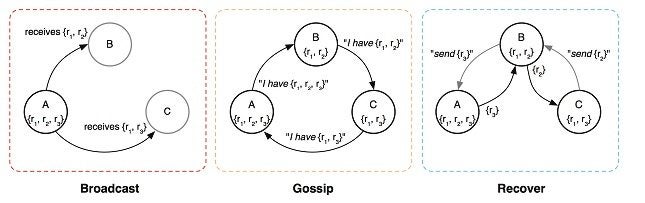
The mechanics of Bimodal Multicast are illustrated in the figure above. Server A receives three new messages. It initially broadcasts the messages to B and C, which only receive two messages each due to packet loss.
The gossip protocol, however, can recover these dropped messages. In the example, A chooses to send a summary of its current state to B, B chooses C, and C chooses A. Both B and C notice they are missing a message, which they recover by sending a request to their gossip peers. Upon receiving these messages, all servers have received all messages.
Under normal operation, these two methods confer a bimodal latency distribution to the overall system. We define latency as the time it takes for a message to be delivered from the ingress point to each server. The overwhelming majority of messages will be delivered directly, but a small percentage of messages may be lost due to packet loss. These messages will have higher latency but they will be eventually recovered by the gossip protocol. Over time, the probability of a message not being successfully recovered drops dramatically.
Powderhorn in the Wild
The theory behind Powderhorn is great, but to ensure that the protocol actually worked, we extensively tested the system in its natural habitat: the Internet. During development, we used the excellent Jepsen to simulate network partitions, packet loss, and high latency. We then performed larger scale testing on virtual servers to see how the system performed when scaling to hundreds of servers. However, the real test of any distributed system is its behavior in production, and we are happy to report that Powderhorn has behaved admirably.
Powderhorn is extremely fast. Upon receiving a purge request, a cache server broadcasts the message to all other servers using UDP. The packet loss rate when communicating between our Points of Presence (POPs) is typically low, rarely exceeding 0.1%. Purge latency is therefore often bounded purely by network delay. This is shown below in the distribution of purge latency by server location.
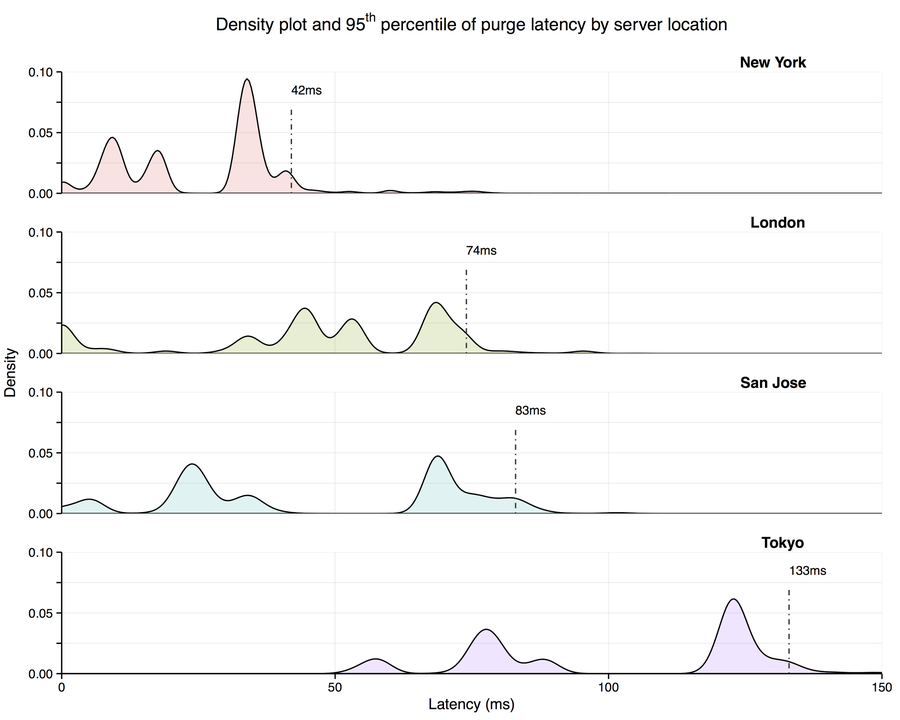
Most purges are issued from the United States or Europe. As a result, purge latency tends to be lowest on the east coast of the United States, which has low, one-way network latency to both the US and Europe. Latency is higher in Asia, as it takes time for packets to travel around the world. Purge latency within the same geographic region however, is much lower than the global latency distribution suggests. For example, Japanese websites issuing purge requests directly to our Tokyo POP will see low purge latency to the rest of Asia.
Powderhorn is also extremely reliable. During deployment, a firewall misconfiguration in one of our POPs resulted in a network partition: two servers in the POP were blocked from communicating with external Powderhorn peers. As a result, these servers could only receive purge requests from neighbors within the same POP. Despite this, purge throughput remained stable during the partition, with all servers within the POP receiving purge requests at a similar rate.

The adjacent semi-log plot shows how the 95th percentile purge latency changed as a result of the misconfiguration. While purge latency increased by two orders of magnitude, purges were still processed within approximately 10 seconds. This happened despite the vast majority of peers being unable to communicate with the affected servers.
Powderhorn's reliability was further tested during a denial-of-service attack on one of our private deployments. During the attack, the customer’s network was unreachable for approximately eight minutes. Nonetheless, Powderhorn was still able to recover all messages, as demonstrated by the below comparison with a nearby unaffected cache server.
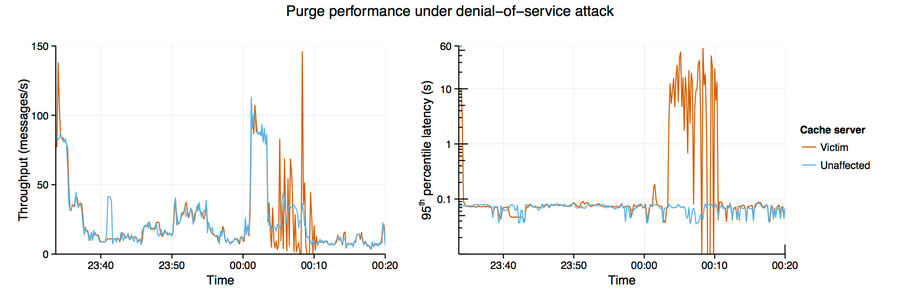
The severity of the packet loss visibly affected purge throughput, but all purges were recovered. While purges were significantly slower than normal, the 95th percentile latency never exceeded one minute, making it still an order of magnitude faster than CDNs focused primarily on delivering static content.
Snap it, work it, quick - erase it
In this post, we've examined the design, implementation, and behavior of Powderhorn. In production, we have seen it deliver purges quickly amidst severe network problems. This behavior justifies many of our design choices and shows that failures are part of any system running over a global network. Something, somewhere, at some point in time is bound to break.
Distributed systems provide the means to tolerate such failures, but getting them right is difficult. We considered, implemented, and tested multiple homebrew and published protocols before settling on Bimodal Multicast. Some couldn't handle our number of servers, while others couldn't deal with specific classes of failure. Without careful research and exhaustive validation, we could not have built a system that provides both high performance and strong reliability. Building Powderhorn on proven systems principles gives us confidence that, as we grow, our purging system will continue to perform consistently, reliably, and Fastly.
If you're interested in working on problems like this, we’re hiring.
Citations
Kenneth P. Birman, Mark Hayden, Oznur Ozkasap, Zhen Xiao, Mihai Budiu, and Yaron Minsky, "Bimodal Multicast," ACM Transactions on Computer Systems, 17, no. 2 (1999): 41–88.