
Entity tags, or ETags, are a really useful part of HTTP that can make sites run faster through more efficient caching of resources. ETags help by differentiating between multiple representations of the same resource; however, they are often misused or implemented incorrectly, which means the potential performance benefits they could be delivering gets lost. Optimizing your ETag implementation is a way to speed up your site and reduce calls to your origin without requiring a huge code refactoring or content overhaul.
As a member of the Solutions Engineering team at Fastly (we’re hiring!), I create solutions for customers using Fastly’s flexible edge compute cloud, and sometimes in that process I realise that I don’t quite understand a small part of the HyperText Transfer Protocol. Most recently, this occurred with ETags, and I wanted to share what I learned. You can find the spec here: RFC 9110 defines the syntax and semantics of the ETag response header field – but keep reading, because this post will help you learn about entity tags, understand how to best use them, and recognize the differences between how they are often used and misused in the wild.
What is an entity tag?
ETag is an HTTP response header field that helps with caching behavior by making it easy to check whether a resource has changed, without having to re-download it – a process known as "revalidation". It provides the entity tag of a resource – a representation of the resource but in a much shorter form. It's normally the result of a hashing function such as MD5 or SHA-1.
The best type of caching is when no request happens, such as when a response can be explicitly cached in the browser using the Cache-Control header field. We have a great blog post on Cache-Control in the wild.
The second best type of caching is when a request happens, but no response body is necessary as the target resource has not changed since the browser last fetched it. This is where an ETag can help.
The actual value of an entity tag isn’t defined by the specification, and is left up to the server. From Fastly’s perspective, it's an opaque value that we store but we don't try to parse or interpret in any way. The origin server determines if what we say we have has changed – and, if not, the origin responds to tell us we can keep using it.
ETags aren't always the best way to revalidate resources. If you know when the resource was last modified and one-second resolution is sufficient, you should use the Last-Modified response header field instead. This means that the browser can ask “send me the content, but only if it has changed since this date, when I last fetched it.” Keeping track of the last modified date might be easier than generating an entity tag.
A modern CDN gives you huge improvements in caching, SEO, performance, conversions, & more.
A practical example
We could read the specification, but that sounds tedious. Instead, let’s run through a practical example. I’m going to omit a number of header fields for clarity.
Here’s a example request from a browser that fetches the Fastly homepage:
> GET / HTTP/2
> Host: www.fastly.com
...And here’s the response from the Fastly server, which also includes the body:
< HTTP/2 200
< Cache-Control: max-age=0, must-revalidate
< Content-Length: 524653
< ETag: "ebeb4dbc1362d124452335a71286c21d"
...The response signifies that the browser must revalidate the page before using it again. To revalidate, a request is made with an If-None-Match request header field using the ETag value from the previous response. If-None-Match isn’t really great English (it’s more like Only-Send-The-Body-If-The-ETag-Is-Different-From-This-One), but maybe that’s a bit verbose. So the next time the end user wants the Fastly homepage, their browser will send a slightly different request:
> GET / HTTP/2
> Host: www.fastly.com
> If-None-Match: "ebeb4dbc1362d124452335a71286c21d".
...If the Fastly server decides that the homepage still has the same ETag as the one cited in the If-None-Match tag, it sends a 304 Not modified response, with no body and the browser uses the body in its cache that it had fetched originally:
< HTTP/2 304
...The benefit is that the second time around, the body does not have to be sent across the network. Fewer bytes transferred leads to improved web performance.
How are entity tags used?
Let’s discover how entity tags are used in the wild on the whole web. The HTTP Archive periodically crawls the top sites on the web and records all sorts of information that we can analyse. We’ll look at the 2023-02-01 HTTP Archive mobile crawl, which crawled 1,019,846,153 resources in total. The ETag response header field is used on around a quarter of responses:

Let’s have a look at the top 20 entity tags, with size representing popularity. They seem to be mostly hexadecimal numbers, generally surrounded by double quotes, sometimes with a W/ prefix or +gzip postfix:

The most common ETags are objects which are loaded on many websites. Mostly these are advertising platforms, as well as React 16.4.0, React DOM 16.14.0 and Font Awesome 4.7.0. These might not be the latest versions of these libraries, but they are the most popular by ETag in this crawl.
An entity tag is used to differentiate between multiple representations of the same resource. There are a number of ways we might approach this. The simplest might be, if the resource is versioned, then a version number would make a good entity tag.
What are the top version-like tags? It looks most versioned resources don’t change – but if they do, they change a lot, as version 3 is rare:
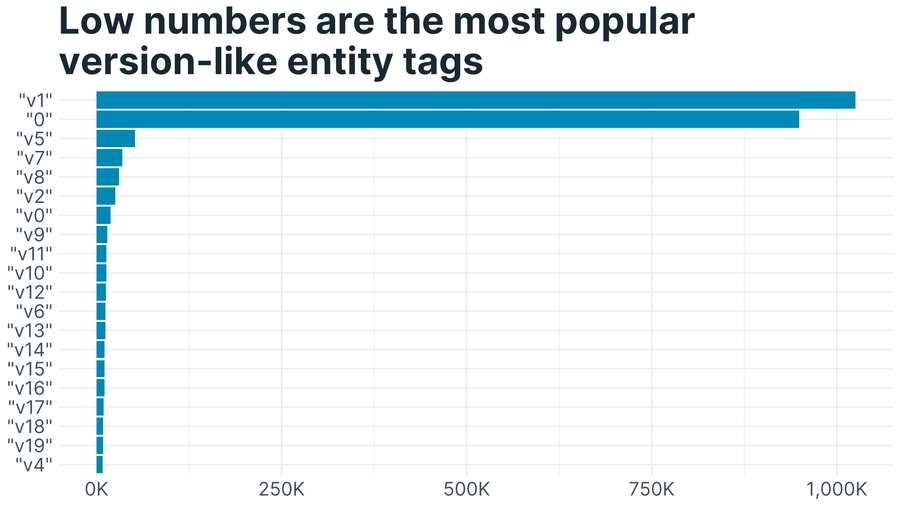
How was I able to detect that a common entity tag value corresponds to a specific version of a font library? A hash of a resource’s contents is another way to identify a representation. It turns out that an MD5 representation in hexadecimal (128 bits as 32 characters) of version 4.7.0 of the fontawesome-webfont.woff2 file is af7ae505a9eed503f8b8e6982036873e. This MD5 method is used by enough web servers and included on enough websites that it just squeezes into the top 20.
What are the most popular hashes used as entity tags? If we look at the length of entity tags, removing the double quotes, we can see that MD5 and SHA-1 are the most common:
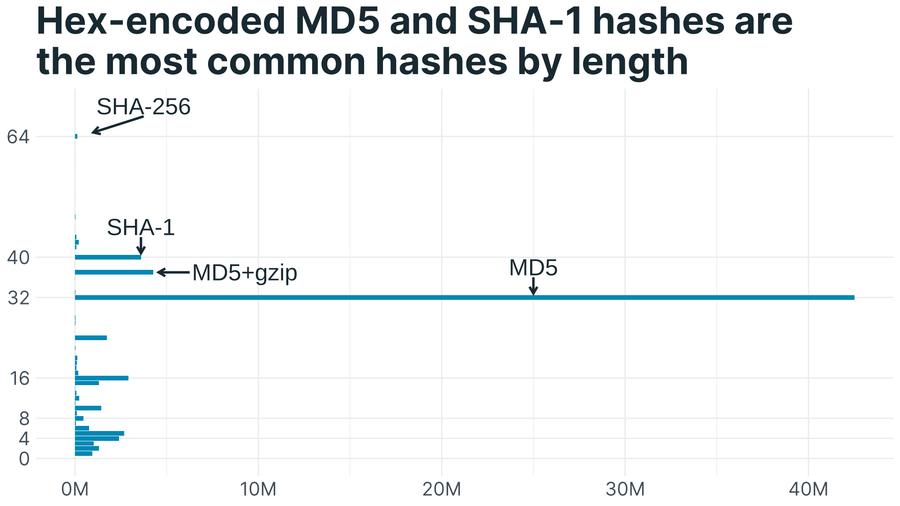
For cryptographic purposes, MD5 and SHA-1 are considered insecure, but for checking whether a resource has changed, they are probably fine.
Popular hashes have lengths of powers of two. Why is a hash length of 37 popular? It’s a MD5 hash with a +gzip postfix. More on this later.
Remember that some of the most popular entity tags start with a W/ prefix? An entity tag can be a weak or a strong validator, with strong being the default. If the data changes, then a strong validator changes. The W/ prefix indicates a weak validator. If the data changes, then a weak validator might change, or might not. Most entity tags are strong:

Another popular entity tag is "95e1b50b0c179aefb47b5b211bb347b5+gzip". Sure enough, all these responses are compressed with gzip. Compressing the body certainly results in a different representation of the same resource, so I would expect the entity tag to change.
The most common postfixes are -gzip and -br:

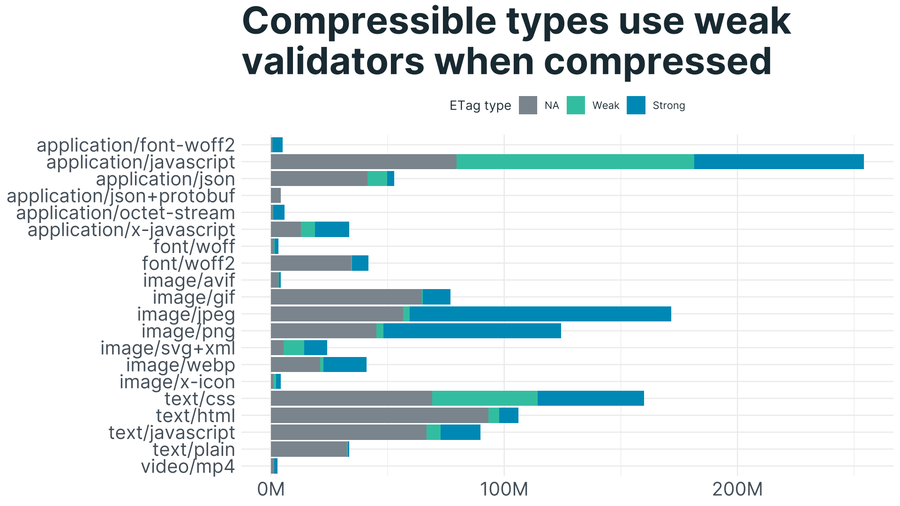
The Content-Type of the resource affects what percentage use weak validators. Compressed versions result in a different representation, so should either have a different strong validator with a postfix or have a weak validator.
Compressible types like CSS, JavaScript and SVG use weak validators more:
Another popular entity tag is "1637097310169751", which looks suspiciously like a number of microseconds since the Unix epoch. This represents 2021-11-16T21:15:10Z, which is presumably when that resource was last modified. Given the resource doesn’t appear to change very often, I would use the Last-Modified response header field instead.
Best practices for entity tags
Now we’ve examined how entity tags are used on the web, let’s describe how best to use them.
Resources should have a validator, such as a Last-Modified or ETag, so that browsers can revalidate them.
Entity tags should be valid: surrounded by double quotes, with an optional W/ prefix.
If the resource is strictly version controlled, then the entity tag should be strong and use the version number.
If the resource is not strictly version controlled, then the entity tag should be strong and use a hash of its content.
Different representations of the resource, such as different image formats for the same image or compressed content coding, should each have their own tag, which could be a strong entity tag or a weak entity tag depending on what is correct for that representation.
How are entity tags misused?
Sometimes entity tags are used incorrectly on the web. When entity tags are used incorrectly, it means that people might see stale content when they should see updated content.
In the word cloud earlier, one of the most popular entity tags was the invalid OPTOUT, with no double quotes. That’s a single misconfigured adserver.
There’s a number of invalid entity tags which are English words. Here are my favourites:
ETag: $etagFileETag: abcdefgETag: customETag: defaultETag: hashETag: himomETag: immutableETag: nullETag: SAMEORIGINETag: tagETag: undefinedETag: UnkownLess popular are the valid entity tags which look like a templating system has been used incorrectly, not substituting the correct entity tag:
ETag: "AssetsCalculatedEtagValue"ETag: "CalculatedEtagValue"ETag: "MyCalculatedEtagValue"At least one of these comes from sample code, so this is a good reminder to ensure that sample code is complete enough to ship in production.
I found some entity tags with spaces, such as "3/19/2017 6:35:34 PM". Spaces are not valid.
I found some “double-weak” entity tags, such as W/W/"49-FHKkWnYgBQtmkHTlg06OHZmoo5A”. This is not valid.
Summary
Now we all know about entity tags and how best to use them. Validate your representations!