
In this series, we're taking a deep dive into learning about edge computing. Check out Part 1: An easy intro to edge computing.
This time we're asking where this edge is, and what it's the edge of? 🔍
The short answer is that it’s somewhere between the user and wherever a site or application is hosted. It might be a CDN server near the user's location. It might be an IoT device in a house or workplace. It's the edge of the network the user is connecting to. Read on for the longer answer!
Client and server
In the olden days, you could make a website just by putting some content in HTML files on a web server. You could then share the location of the server with people and they could open the site in their web browser. Typically you would use a domain to point at the server location and include links to the site in other web pages so that people could click to visit.
This way of making websites still works! You can slap the content below in a file with an .html extension, put it on a web server, and visit it in a browser. That’s a website.
The client was the user’s browser on their device, and the server was the machine where the file was stored. The server was connected to the network known as the internet, and people could request the content hosted there by browsing the web and navigating to the site address. Client / Server architecture was the model we used to build and reason about websites for a long time.
As the web became a bigger part of human life, the technologies became more complex. But the edge is part of this same network – it just refers to places on the network that are closer to the user than the server hosting the content.
Let’s use an example. I’m in Glasgow, and when I visit my portfolio site that I built on Glitch and have my domain routing traffic through Fastly CDN, this is what happens:
My request goes through my nearest PoP (Point of Presence) on the Fastly network of servers, which will be in the UK.
If the Fastly server has the site content stored in cache, I get a response from there and that’s that.
If it doesn’t have the content in cache, the Fastly server makes the request to where my Glitch site is hosted (on an AWS service in America) and returns the response to me.
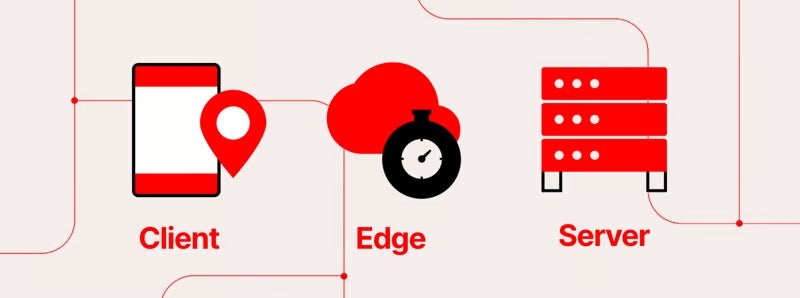
📱 The client is my browser.
🪩 The edge is the Fastly PoP near me.
🏭 The server (or origin host) is the Glitch site in an S3 bucket.
When we refer to the edge, we mean the network edge, a location on the network that's nearer the client than the origin server. If you’re using Fastly, the edge is any server on the Fastly network that’s involved in delivering your site.
Static and dynamic
Another shift that happened on the web was from static to dynamic content. In the beginning, we put our content in files and the visitor basically received those static assets and viewed them on their device. As websites started to incorporate more data, web pages were constructed dynamically. If someone visited a site, the server built up-to-date data from the database into a page and returned that to the user. And so websites became more like software applications, written in coding languages that ran on web servers.
Frameworks and APIs
These web applications became more and more complex, and we started to build them using modular components – dependencies someone else built and that you plugged into your project like Lego blocks. APIs became a standard way to access data sources between applications. Developers started using frameworks to generate the HTML in website user interfaces, which also included interactivity coded in JavaScript that ran in the browser.
We called the server part backend development, and the client part was frontend development. The selection of technologies used to build a website was its stack.
Serverless and the cloud
As web audiences became more globally distributed, the need arose for sites to scale, to perform reliably for large numbers of people accessing them from many different places around the world. The cloud gave us the ability to access server resources on demand, and serverless platforms allowed us to build applications that could scale up and down using infrastructure also managed by cloud services.
The complexity of building and scaling websites created a need for process around what happened when you deployed an application, to put it on the network in a way that would help it perform reliably.
On the edge

🎏 Sneak preview of the Glitch app we'll be using to learn to code for the edge.
You can build serverless applications that run at the network edge. When you code an edge application for the web, it will run between your client and server code – between what happens in the user's browser and what happens on your host server. This means that your edge code can manipulate the request and response, changing the UX with logic that runs close to the user.
Later in this series, we'll learn how to use edge computing to customize the user experience with geolocation information. OK, enough history. Next time we’ll find out how you code these edge apps. ⏳