



Desde Fastly, solemos destacar nuestros potentes POP</u> y la arquitectura moderna</u> para explicar qué nos hace diferentes y mejores que la competencia. Hoy tenemos muchas ganas de enseñarte otro ejemplo tras bambalinas de lo que podemos innovar con una red moderna totalmente definida por software.
El pasado febrero, Fastly distribuyó una cifra récord de 81,9 Tbit/s de tráfico durante la Super Bowl</u> sin ninguna intervención humana en las políticas de tráfico de salida, y todo fue gracias a Autopilot. Autopilot es nuestro nuevo sistema de automatización de la ingeniería de tráfico de salida. Al tenerla en marcha, no hizo falta ninguna intervención manual ni siquiera durante un día en el que batimos el récord de distribución. Dicho de otro modo, fue la primera vez que Fastly estableció un nuevo récord de tráfico en su red y, al mismo tiempo, redujo el número de personas que debían estar gestionándola a nada menos que cero. Hizo falta el trabajo sin descanso de mucha gente de distintos equipos de Fastly para mejorar las capacidades de autogestión de la red. El resultado es una red totalmente automatizada que puede reaccionar con rapidez y frecuencia a fallos, congestión y deterioro del rendimiento sin ningún tipo de intervención manual.
Autopilot aporta muchas ventajas a Fastly, pero es todavía mejor para nuestros clientes, que ahora pueden confiar aún más en nuestra capacidad de gestionar incidentes como errores de proveedores de red o ataques de DDoS y picos inesperados de tráfico, todo ello mientras los usuarios finales disfrutan de una experiencia fluida y sin trabas. Veamos cómo llegamos a este punto y cómo Autopilot puede funcionar tan bien. Ah, y si aún no trabajas con Fastly, contacta con nosotros</u> o empieza con nuestro paquete gratuito</u>. Te conviene estar en esta red.
Llegar hasta aquí ha supuesto varios años de mucho esfuerzo, y podríamos retroceder a hace tres años, cuando compartimos cómo habíamos gestionado el tráfico durante la Super Bowl de 2020</u>. En ese momento, contábamos con una generación anterior de nuestra automatización de ingeniería de tráfico que repartía el tráfico entre distintos cuellos de botella comunes, mientras había operadores a cargo de los casos más complejos. Esa estrategia nos bastaba para el tráfico y la superficie de red que teníamos por aquel entonces, pero limitaba nuestra escalabilidad porque, pese a haber reducido la intervención humana, aún necesitábamos personal que estuviera pendiente de la capacidad. A ese personal había que contratarlo y formarlo, lo cual se convertía en otro cuello de botella, puesto que el número de operadores de la red debía aumentar, como mínimo, al ritmo marcado por la propia red. Además, podemos prepararnos y rendir durante un evento planificado como es la Super Bowl, pero el ser humano no siempre tiene la máxima agudeza cuando se despierta en mitad de la noche para resolver incidentes inesperados en internet.
Una automatización completa con Autopilot y Precision Path
Para seguir creciendo, pues, era imperativo dejar de necesitar la intervención humana. Con solo esta mejora, hemos podido crecer fácilmente y a la vez mejorar la gestión de problemas de capacidad y rendimiento, y es que la intervención humana conlleva un coste: requiere que una persona reflexione acerca del problema en cuestión y tome una decisión, lo cual solo se puede hacer un número limitado de veces, por lo que es necesario preservar energía y actuar solamente cuando surja un problema que vaya a afectar directamente el rendimiento para el cliente. Además, si hay que tomar alguna medida, esta suele ser de gran alcance para asegurar que no hagan falta más intervenciones por el mismo problema y minimizar el número de intervenciones necesarias.
A modern CDN gives you huge improvements in caching, SEO, performance, conversions, & more.
Con una automatización total, el coste de cada acción es de prácticamente cero, de modo que se pueden efectuar optimizaciones mínimas con gran frecuencia para resolver pequeños problemas que ocurran o vayan a ocurrir. Gracias a la precisión y la reactividad añadidas que aporta la automatización completa, es posible ejecutar enlaces sin riesgo con un mayor rendimiento y desplazar tráfico hacia donde convenga rápidamente.

Figura: comparativa entre capacidad y demanda del tráfico de salida en la interfaz. Ante las múltiples interfaces que presentaban una demanda tres veces superior a la capacidad física disponible durante la Super Bowl, se derivó el tráfico automáticamente y se pudo seguir distribuyendo contenido de forma eficiente sin consecuencias negativas para la red.
La gráfica anterior muestra un ejemplo en el que Autopilot detectó una demanda de tráfico superior a la capacidad física de los enlaces. Durante la Super Bowl, en algunos casos, esta demanda multiplicó por tres la capacidad disponible. Sin Autopilot, los picos en la demanda de tráfico habrían dado buena cuenta de esos enlaces y habrían obligado a intervenir manualmente no solo para evitar errores, sino también para gestionar todas las consecuencias en puntos posteriores de esas intervenciones, con tal de que la red volviera a funcionar a toda máquina. Con Autopilot, la red pasó tráfico a rutas secundarias de forma automática y pudimos atender la demanda extra sin que se deteriorara el rendimiento.
En este artículo nos centramos en los sistemas que creamos para gozar de escalabilidad ante eventos de mucho tráfico sin requerir la intervención de ningún operador.
Problema técnico

Figura: el POP de Fastly está interconectado con internet mediante varios pares y proveedores de tránsito.
La red de puntos de presencia</u> (POP) de Fastly está repartida por todo el mundo. Cada POP dispone de múltiples alojamientos; es decir, está interconectado con internet mediante varias redes que son pares o proveedores de tránsito, para garantizar su capacidad y fiabilidad. Ante el abanico de rutas posibles, lo difícil e importante es saber elegir la que ofrece mejor rendimiento en cada momento para alejar el tráfico de otras rutas que presenten errores o estén saturadas.
Los proveedores de redes utilizan el protocolo de puerta de enlace de frontera (BGP)</u> para intercambiar información sobre la disponibilidad de destinos de internet. Fastly consume las actualizaciones del BGP de sus vecinos y detecta cuál se puede utilizar para distribuir tráfico a un destino determinado. No obstante, el BGP presenta varias limitaciones. En primer lugar, no sabe de capacidad ni rendimiento; es decir, solo se puede usar para comunicar si se puede alcanzar un destino de internet, pero no para discernir si hay suficiente capacidad para distribuir todo el tráfico deseado, o bien cuál sería el rendimiento o la latencia en ese caso. En segundo lugar, el BGP tarda en reaccionar ante errores remotos: si se produce un fallo en una ruta remota, suelen pasar varios minutos antes de que se propaguen las actualizaciones, lo cual da tiempo a que surjan bucles y agujeros negros.
Es difícil resolver estos problemas sin crear otros nuevos, sobre todo cuando se están manejando decenas de terabits por segundo (Tbit/s) de tráfico. De hecho, por muy deseable que parezca eludir rápidamente estos fallos, debemos ir con cuidado a la hora de redirigir grandes cantidades de tráfico sin la debida consideración, puesto que ello podría pasar tráfico de una ruta eficiente a otra que no lo sea tanto, lo cual, a su vez, podría crear congestión más adelante y afectar a la experiencia de uso. Dicho de otro modo, si tomamos decisiones a la ligera, podemos terminar aumentando la congestión en lugar de reducirla.
La solución que propone Fastly es usar dos sistemas de control distintos que funcionen en diferentes escalas temporales para evitar los fallos en ruta y garantizar que el tráfico permanezca en las rutas de mayor rendimiento.
El primer sistema, que opera en una escala temporal de decenas de milisegundos (para realizar varios trayectos de ida y vuelta), supervisa el rendimiento de cada conexión de TCP entre Fastly y los usuarios finales. Si la conexión no logra avanzar tras varios trayectos de ida y vuelta, esta se redirige a otras rutas alternativas hasta que vuelve a hacerlo. Este es el sistema en el que se basa nuestro producto Precision Path</u>, que protege las conexiones entre Fastly y los usuarios finales y garantiza una rápida reacción ante fallos de la red al redirigir, con precisión de cirujano, flujos individuales que tienen problemas en estas escalas temporales más pequeñas.
El segundo sistema, al que llamamos Autopilot, funciona en una escala temporal más larga y estima, minuto a minuto, la capacidad residual de nuestros enlaces y el rendimiento de las rutas de la red mediante los análisis correspondientes. Con esa información, asegura el reparto del tráfico entre los enlaces para optimizar el rendimiento y evitar que estos queden congestionados. Este sistema tarda algo más en reaccionar, pero toma decisiones mejor fundamentadas a partir de los datos de telemetría a alta resolución de varios minutos de la red. Así, Autopilot garantiza que se puedan mover grandes cantidades de tráfico sin que ello afecte negativamente a posteriori.
La combinación de estos dos sistemas permite redirigir flujos con rapidez a rutas más fluidas, así como ajustar periódicamente la configuración general de enrutamiento con los datos necesarios en la mano. Los dos sistemas funcionan las 24 horas, pero tuvieron un papel especialmente destacado durante la Super Bowl, cuando redirigieron, respectivamente, 300 Gbit/s y 9 Tbit/s de tráfico que, de otro modo, se habrían distribuido por rutas saturadas, ineficientes o con errores.
Según la información de la que disponemos, no existe ninguna otra estrategia de ingeniería del tráfico de salida que utilice sistemas funcionando a distintas escalas temporales para equilibrar la reactividad, la precisión y la seguridad de las decisiones de enrutamiento. En lo que resta de artículo repasaremos cómo funcionan ambos sistemas, pero antes debemos desviarnos algo del tema para explicar cómo dirigimos el tráfico a la salida de nuestros POP, otra estrategia poco común en la que somos líderes del sector.
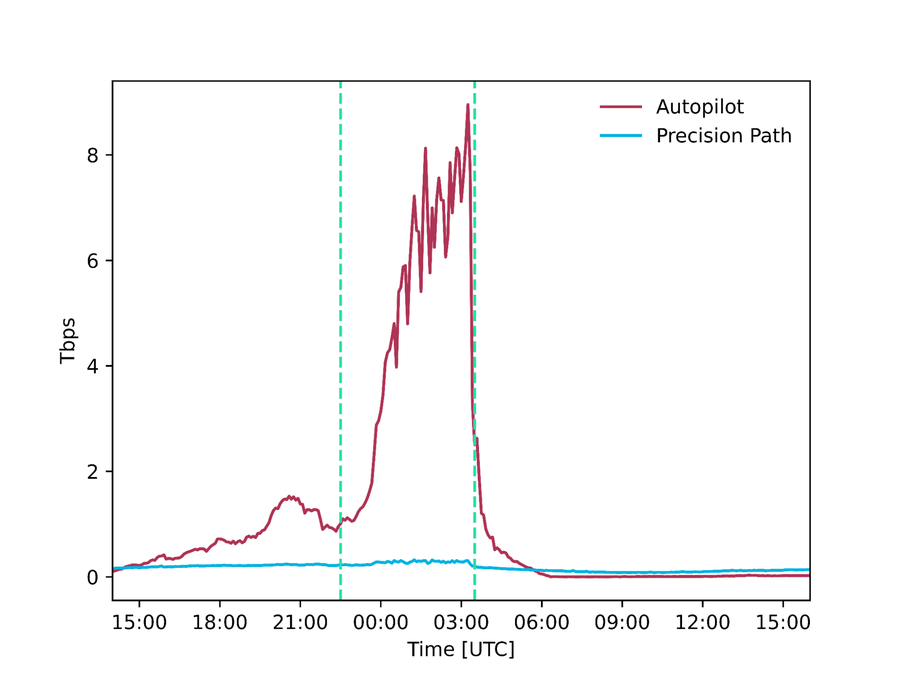
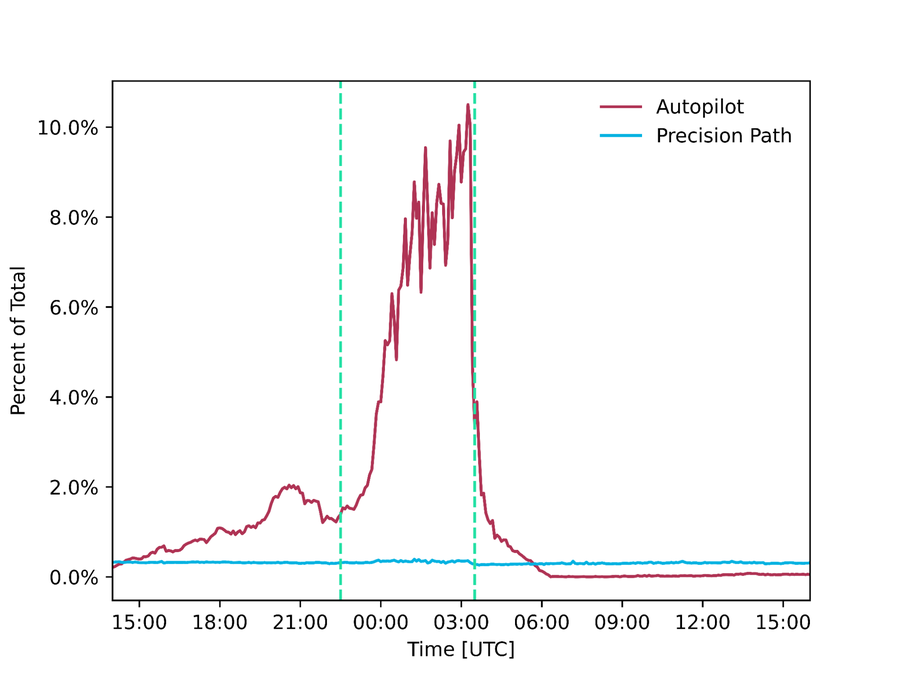
Figura: cantidad de tráfico (tráfico absoluto y porcentaje del total) distribuido por Precision Path y Autopilot respectivamente durante la Super Bowl.
Arquitectura de red de Fastly
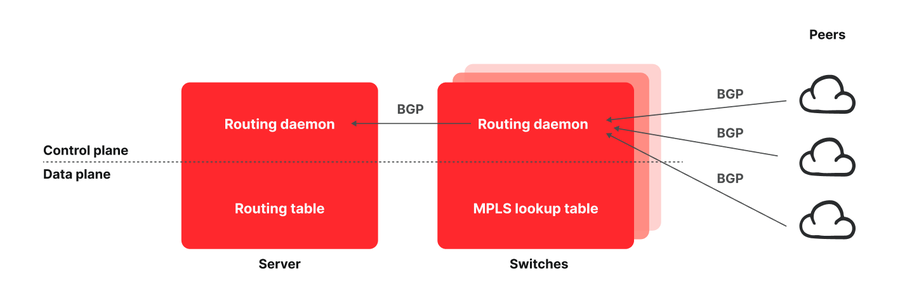
Figura: arquitectura de los POP de Fastly.
Un POP típico de Fastly se compone de una capa de servidores que están interconectados con todos los pares y proveedores de tránsito mediante una capa de conmutadores de red. El modus operandi a la hora de crear un POP de la edge cloud consiste en utilizar enrutadores de red, que cuentan con suficiente memoria como para almacenar toda la tabla de enrutamiento de internet. En cambio, Fastly empezó a diseñar una arquitectura de enrutamiento que trasladaba todas las rutas a hosts finales</u> con el objetivo de crear una red más rentable, pero pronto nos dimos cuenta de las grandes posibilidades que abría esta arquitectura. Así, los puntos de conexión que tienen visibilidad del rendimiento de los flujos también pueden influir en su ruta, por lo que no es de extrañar que la capacidad de red y de programación, la flexibilidad y la facilidad de uso de Fastly sigan dejando atrás a la competencia.
Así es como funciona nuestra arquitectura de enrutamiento: tanto los conmutadores como los servidores ejecutan demonios de enrutamiento, que son instancias del BIRD Internet Routing Daemon con algunas revisiones propias. Los demonios ejecutados en los conmutadores conocen todas las rutas que anuncian los pares y puntos de tránsito pero, en vez de insertar esas rutas en la tabla de enrutamiento de los conmutadores, las propagan a los servidores, que son los que las insertan en las tablas de enrutamiento. Para que luego los servidores puedan enrutar el tráfico al par o al punto de tránsito deseado, usamos la conmutación de etiquetas multiprotocolo (MPLS). Rellenamos cada conmutador con una entrada de su tabla de búsqueda de la MPLS (base de información de reenvío de etiquetas, o LFIB) por cada puerto de salida y etiquetamos todos los anuncios de rutas del BGP que se propagan a los servidores con una comunidad que codifica la etiqueta de la MPLS usada para enrutar ese tráfico. A su vez, los servidores usan esa información para rellenar su tabla de enrutamiento y se sirven de la etiqueta correspondiente para enrutar el tráfico de salida del POP. Tratamos esta cuestión más a fondo en un artículo científico</u> que publicamos en el NSDI ‘21 de USENIX.
Eludir rutas con fallos de la mano de Precision Path
Al enviar todas las rutas a los servidores, permitimos a los puntos de conexión redirigir basándose en métricas de la capa de la aplicación y el transporte, y así fue como se creó Precision Path</u>. En un intervalo de decenas de milisegundos, Precision Path redirige flujos individuales cuando se producen errores en la ruta o hay mucha congestión. Funciona a las mil maravillas para alejar el tráfico de los errores que pasan al momento, pero no se le puede pedir que elija la mejor ruta de forma proactiva. En otras palabras, Precision Path evita el peligro, pero no es capaz de analizar el contexto y seleccionar una nueva ruta óptima. Ya hablamos de la tecnología que hay detrás de nuestro producto Precision Path en esta entrada del blog</u> y, en más detalle, en este artículo científico contrastado</u>, pero a continuación lo explicaremos brevemente.
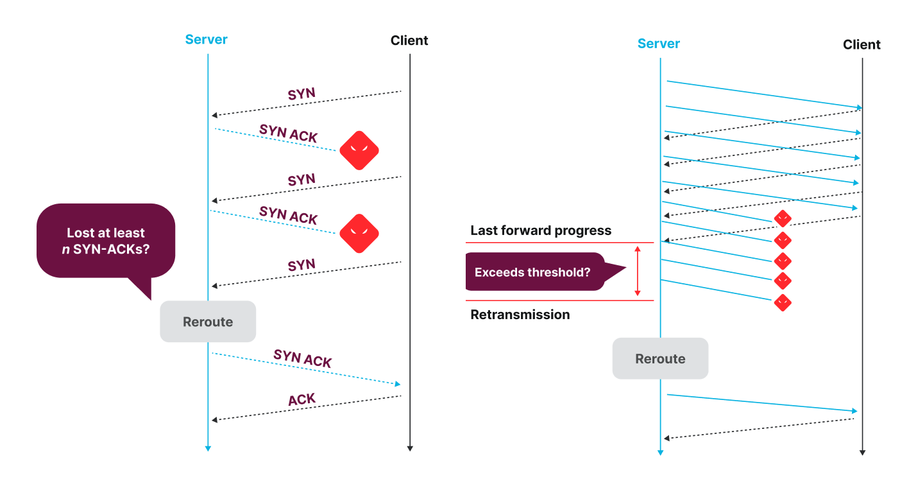
Figura: lógica de decisión de reenrutamiento de Precision Path para conexiones al establecerse (izquierda) y conexiones ya establecidas (derecha).
Este sistema es una revisión del kernel de Linux que supervisa el estado de conexiones TCP individuales. Cuando una conexión no logra avanzar durante un tiempo de ida y vuelta (RTT), lo cual indica un error potencial en la ruta, se redirige a otra ruta aleatoria hasta que retoma su avance. Si puede tomar decisiones de reenrutamiento para flujos individuales, es gracias a nuestra arquitectura de enrutamiento basada en el host, con la que los servidores seleccionan las rutas del tráfico de salida aplicándoles etiquetas de MPLS. Los hosts finales pueden mover tráfico rápidamente de forma individualizada porque cuentan con visibilidad del progreso de las conexiones y tienen los medios para cambiar la selección de la ruta de red. Este sistema destaca por su efectividad a la hora de resolver deterioros del rendimiento y fallos breves que, en manos de operadores u otros sistemas de ingeniería de tráfico basada en telemetría, tardarían demasiado en arreglarse. La desventaja, no obstante, es que este sistema solo reacciona ante deterioros graves del rendimiento que ya son visibles en el plano de datos y traslada el tráfico a otras rutas aleatorias que, por mucho que no sufran errores, pueden no ser las óptimas.
Decisiones de enrutamiento a largo plazo mejor fundamentadas con Autopilot
Autopilot compensa las limitaciones de Precision Path porque, a pesar de no actuar con tanta rapidez, toma decisiones con mayor fundamento al conocer las rutas que pueden ofrecer mejores prestaciones o una menor congestión. En vez de limitarse a sacar el tráfico de una ruta con errores, como Precision Path, traslada mayores volúmenes de tráfico hacia mejores partes de una red. Hasta hoy no habíamos hablado de Autopilot, y estamos encantados de presentarlo por todo lo alto en esta entrada del blog.
Autopilot es un controlador que recibe señales de telemetría de nuestra red, como muestras de paquetes, capacidad de enlaces, RTT, medidas de pérdida de paquetes y disponibilidad de rutas por cada destino particular. Cada minuto, el controlador de Autopilot recaba telemetría de la red, la utiliza para prever la demanda de tráfico por cada interfaz de salida sin rutas de reemplazo, y redirige el tráfico hacia rutas alternativas si hay uno o varios enlaces a punto de saturarse o si la ruta actual de un destino concreto no rinde como lo harían sus alternativas.
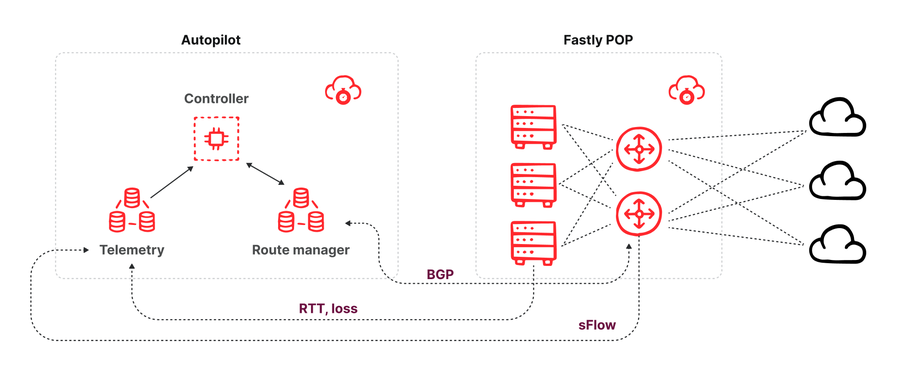
Figura: gráfico de la arquitectura de Autopilot.
La arquitectura de Autopilot consta de tres componentes (ver figura anterior):
Un administrador de ruta que se empareja con cada conmutador del POP y recibe todas las novedades de la ruta que llegan de los vecinos del conmutador mediante una sesión de emparejamiento BGP. El administrador de ruta proporciona una API que permite a los consumidores conocer las rutas disponibles para un prefijo de destino concreto. Asimismo, ofrece la capacidad de insertar reemplazos de rutas mediante su API, lo cual se efectúa anunciando una actualización de ruta BGP en el conmutador con un valor de preferencia local mayor que las rutas que comunican otros pares y proveedores de tránsito. Esta nueva ruta anunciada gana el mecanismo de desempate del BGP y se puede insertar en las tablas de enrutamiento de los servidores para redirigir tráfico.
Un recopilador de telemetría que recibe muestras de paquetes sFlow de todos los conmutadores de un POP para que se estime el volumen del tráfico, desglosado por interfaz de destino y prefijo de destino, así como medidas de latencia y pérdida de paquetes de todo el tráfico intercambiado entre los POP de Fastly de todos los proveedores disponibles de los servidores.
Un controlador que consume (cada minuto) los últimos datos de telemetría (volúmenes de tráfico y rendimiento) y todas las rutas disponibles de los prefijos para los que distribuye el POP, para luego calcular si conviene insertar un reemplazo de ruta del BGP para pasar el tráfico por rutas alternativas.
Combinación de Precision Path y Autopilot
Un reto que plantea el hecho de tener distintos sistemas de control funcionando en las mismas entradas y salidas es que se coordinen para seleccionar la mejor opción, en vez de competir entre sí, puesto que, si cada proceso de optimización intentase elegir la mejor opción por sí solo, con una visión limitada, podría provocar más interrupciones y conseguir el efecto contrario al deseado. Hasta donde sabemos, somos los primeros del sector que utilizamos varias escalas temporales en nuestra ingeniería de tráfico.
En este caso, no obstante, la dificultad principal es que, una vez que se empieza a redirigir el flujo mediante Precision Path, este ya no responde a los cambios de ruta del BGP, incluidos aquellos que activa Autopilot. Así pues, a la hora de tomar decisiones, Autopilot necesita saber la cantidad de tráfico que controla Precision Path en cada momento. Resolvimos este problema de dos maneras: en primer lugar, ajustamos Precision Path para que redirigiera lo mínimo necesario e hicimos que Autopilot pudiera observar ese tráfico y lo tuviera en cuenta en sus decisiones.
La primera vez que desplegamos Precision Path, ajustamos su configuración para minimizar los falsos positivos, que provocaban que se alejara el tráfico de una ruta óptima que tuviera una mínima dificultad temporal y se pasara a rutas más largas y de peor rendimiento. Esto, a su vez, podía terminar empeorando la situación y reducir el rendimiento de las conexiones de TCP afectadas. Documentamos al detalle nuestros experimentos con los ajustes en este artículo científico</u>. Sin embargo, eso no basta, porque aunque tomemos la decisión correcta cuando redirigimos una conexión, la ruta elegida en primera instancia puede recuperarse al cabo de pocos minutos, lo cual suele ocurrir cuando el BGP se da cuenta del error y retira tráfico de la ruta en cuestión. Para asegurarnos de que redirigimos las conexiones otra vez a la ruta de preferencia cuando esta se recupera, Precision Path examina la ruta cada cinco minutos después del primer enrutamiento y, si está operativa, vuelve a pasar la conexión a dicha ruta. Este mecanismo resulta de especial utilidad para evitar que conexiones largas, como transmisiones de vídeo, se queden en una ruta alternativa durante toda su duración, y también reduce el volumen de tráfico que Autopilot no puede controlar para darle más margen de maniobra.
Más complejo es, por otro lado, el problema que plantea el hecho de que el tráfico dirigido por Precision Path sea visible para Autopilot. Como ya hemos mencionado, Autopilot conoce el volumen de tráfico que se envía a cada interfaz a partir de muestras de paquetes sFlow emitidas por los conmutadores. Entre otros elementos, estas muestras informan de la interfaz a la que se enviaron los paquetes y de la etiqueta de MPLS que llevaba consigo, pero no así de cómo se aplicó la etiqueta de MPLS. Nuestra solución fue crear un nuevo conjunto de etiquetas de MPLS alternativas para nuestros puertos de tráfico de salida y asignarlas para su uso exclusivo por parte de Precision Path. Así, si buscamos una etiqueta MPLS en nuestra base de datos de gestión de direcciones IP, podemos averiguar rápidamente qué paquete se envió según la ruta de BGP elegida o el reenrutamiento de Precision Path. Exponemos esta información al controlador de Autopilot, que trata a Precision Path como «incontrolable»; es decir, el tráfico que no se desviará de su ruta actual aun cuando se actualiza la ruta de preferencia de su prefijo de destino.
Una automatización segura
Los clientes nos confían su negocio para que ejerzamos el papel de intermediarios entre sus servicios y los usuarios, y nos tomamos muy en serio esta responsabilidad. La automatización de las operaciones de red nos permite ofrecer una experiencia más fluida a nuestros clientes, pero también queremos garantizar la fiabilidad, de ahí que la seguridad y la facilidad de uso sean prioritarias cuando diseñamos toda automatización. Nuestros sistemas son fáciles de arreglar cuando presentan errores y están diseñados para que los operadores de red puedan entrar y anular comportamientos mediante los ajustes de políticas de enrutamiento. Este último aspecto es fundamental, porque permite que los operadores utilicen técnicas y herramientas que han aprendido en entornos sin automatización y los apliquen en el nuestro. Si logramos automatizar una parte cada vez mayor del problema, podemos reducir la carga cognitiva y, con ello, el tiempo necesario para resolver problemas cuando ya se nos echan encima. Estas son algunas de las estrategias que aplicamos para que nuestra automatización sea segura y funcional:
Herramientas de funcionamiento habituales: tanto Precision Path como Autopilot se pueden controlar mediante técnicas y herramientas de redes estándares.
Precision Path se puede deshabilitar en rutas individuales con la inserción de una comunidad de BGP concreta en un anuncio de la ruta en cuestión, tarea a la que los ingenieros de redes están sumamente acostumbrados por su uso en todo tipo de contextos. Precision Path también se puede deshabilitar en una sesión individual del TCP configurando una marca de reenvío concreta en el socket que permite ejecutar mediciones activas sin que Precision Path intervenga y contamine los resultados.
La reselección de ruta de Autopilot se basa en la mejor selección de ruta del BGP; es decir, intentará redirigir el tráfico hacia la segunda mejor ruta según la selección de la mejor ruta del BGP. Así pues, los operadores pueden influir en la ruta alternativa que propondrá Autopilot aplicando cambios en las políticas de BGP, como modificando valores de preferencia locales o del MED, que también es una técnica muy común.
Por último, nuestros sistemas de telemetría de redes recaban datos sobre si las conexiones se dirigieron a rutas seleccionadas por Precision Path o Autopilot, lo cual nos permite deducir qué ocurre.
Auditorías de la calidad de los datos: revisamos la calidad de los datos que llegan a nuestra automatización, y hemos configurado nuestros sistemas para que eviten ejecutar cualquier cambio si los datos de entrada no encajan. En el caso de Autopilot, por ejemplo, comparamos la estimación del flujo de salida obtenido mediante muestras de paquetes con una estimación proveniente de contadores de la interfaz, y si difieren más allá de un cierto umbral, deducimos que una o las dos mediciones son incorrectas y, por tanto, no aplicamos ningún cambio. La siguiente gráfica muestra la diferencia entre esas dos estimaciones durante la Super Bowl en un POP de Norteamérica.
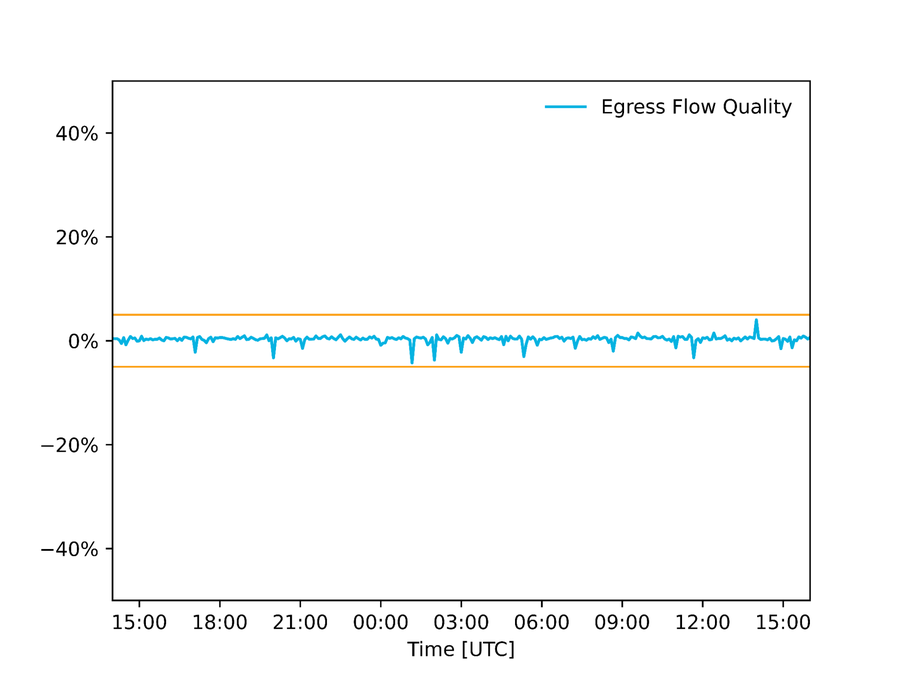
Figura: diferencia entre estimaciones de uso de enlaces obtenidas mediante contadores de la interfaz y muestras de paquetes. Los umbrales de +/- 5 % representan los márgenes de error aceptables.
Análisis de hipótesis y grupos de control: además de supervisar datos de entrada, también revisamos las decisiones que efectúan los sistemas y no dudamos en corregirlas si son erróneas. Para ello, Precision Path utiliza grupos de tratamiento y control: seleccionamos al azar un pequeño porcentaje de conexiones para que formen parte de un grupo de control en el que Precision Path está deshabilitado y, acto seguido, comparamos su rendimiento con las conexiones en las que Precision Path está habilitado. Si las conexiones de control ofrecen un mejor rendimiento que las conexiones de tratamiento, nuestro equipo de ingeniería recibe una alerta para investigar y corregir lo que haga falta. Igualmente, en Autopilot, antes de desplegar un cambio de configuración en nuestro algoritmo, lo ejecutamos «en la sombra», de modo que el nuevo algoritmo toma decisiones, pero estas no se aplican a la red. El nuevo algoritmo solo se despliega si presenta un rendimiento igual o superior al del algoritmo en ejecución.
Sin cambios en caso de error: cuando se produce un error en nuestros sistemas, sea en el componente que sea, no permanecen abiertos ni cerrados, sino sin cambios; es decir, dejan la red en la última configuración que funcionaba y avisan a nuestro equipo de ingeniería para que investigue el problema.
Conclusiones
Esta entrada da una visión de cómo Fastly automatiza la ingeniería de tráfico de salida para asegurarse de que el tráfico de los clientes llegue sin problemas a sus usuarios finales. Seguimos innovando y abriendo nuevos horizontes de posibilidades con el objetivo claro de ofrecer un rendimiento sin igual. Si quieres poner tu tráfico en manos de expertos que encajen con esta filosofía, no esperes más y ponte en contacto con nosotros</u>. Si, en cambio, te gustaría innovar en primera persona, echa un vistazo a nuestras ofertas de trabajo: /about/careers/current-openings</u>.
Software de código abierto
La automatización de nuestra red es posible gracias a la tecnología de código abierto. El código abierto forma parte de la esencia de Fastly: desde las contribuciones que realizamos y los productos en los que lo utilizamos, hasta los proyectos propios cuyo código abrimos en la medida de lo posible. Es más, nos hemos comprometido a donar 50 millones de dólares en servicios gratuitos a Fast Forward</u> para contribuir a los proyectos que hacen funcionar internet y nuestros propios productos. Para crear nuestra enorme automatización de red utilizamos:
Kafka</u>, una plataforma descentralizada de streaming de eventos
pmacct</u>, un recopilador de sFlow
goBGP</u>, una biblioteca de demonios de enrutamiento de BGP utilizada para crear el recopilador/insertador de rutas de Autopilot
BIRD</u>, un demonio de enrutamiento de BGP ejecutado en nuestros conmutadores y servidores
Hemos hecho todo lo posible para devolver algo a la comunidad, enviando a quienes se encargan del mantenimiento las mejoras y las correcciones de errores que implementamos en nuestro día a día. Estamos muy agradecidos a la gente que creó estos proyectos. Si te encargas de mantener o contribuir a algún proyecto de código abierto y estás pensando en apuntarte a Fast Forward, escríbenos aquí</u>.