
Una de las claves para una experiencia de streaming en vivo positiva es la gestión adecuada de la congestión de red. Nuestra plataforma realiza esta acción, casi de forma automática, las 24 horas del día y con una intervención humana mínima. Como parte del equipo de streaming de eventos en vivo de Fox Sports para la Super Bowl LIV, fuimos testigos de lo bien que funcionó esta automatización durante uno de los días más importantes en internet del año. A continuación, encontrarás el paso a paso de cómo la automatización de red, un pequeño equipo de ingenieros y las enseñanzas clave de momentos de tráfico extremo del pasado nos permiten atender el rendimiento a escala de nuestros clientes.
Automatización + expertos = el equipo ideal
Nuestro proceso de streaming en vivo comienza con la conectividad directa con numerosos proveedores de servicios de internet (ISP) en todo el país. Hacemos todo lo que podemos y más para mantener el tráfico de vídeo en vivo en estas rutas directas mediante la interconexión de partners y así ofrecer transmisiones de vídeo lo más cerca posible de los usuarios finales. Pero en algún momento, conforme aumenta la demanda de tráfico, estos puntos de interconexión se suelen congestionar, lo que afecta a la calidad del servicio. Los espectadores de streaming en vivo pueden experimentar problemas de rendimiento, como el almacenamiento en búfer lento o una baja calidad de la transmisión de vídeo, a consecuencia de la pérdida de paquetes. Cabe destacar que más de la mitad de los espectadores abandonan una mala experiencia de transmisión de vídeo online como estas en 90 segundos, o incluso menos.
En este momento se activa nuestra automatización de red integrada, conocida internamente como Auto Peer Slasher o APS, y StackStorm realiza la orquestación. Esperamos poder compartir más detalles sobre estas integraciones en una próxima publicación.
Al reconocer que la utilización del enlace se acerca a su capacidad máxima, nuestro equipo envía una alerta para activar APS al tiempo que desvía automáticamente una pequeña parte del tráfico para mantener el enlace por debajo de los umbrales de congestión. Acto seguido, este tráfico se redirige automáticamente al ISP asignado a través de las mejores rutas, en general mediante tránsito IP. En momentos de tráfico masivo de streaming en vivo, esto puede suceder varias veces en cuestión de minutos, lo que provoca que la plataforma desvíe tráfico de interconexión de partners al tránsito IP una y otra vez. En la mayoría de los casos, se mantiene el estado de conexión, lo que evita que el reproductor reinicie la sesión desde cero.
A continuación encontrarás un ejemplo de este proceso. Una vez que recibe la alerta, APS ejecuta un flujo de trabajo específico y realiza múltiples acciones en enlaces a un ISP en el área metropolitana de Washington D. C., al tiempo que envía informes a nuestro equipo a través de Slack.

En el siguiente gráfico podemos observar que cada vez que estos enlaces alcanzan el 90 % de utilización, APS reduce el tráfico suficiente para mantener los enlaces fuera del umbral de congestión.
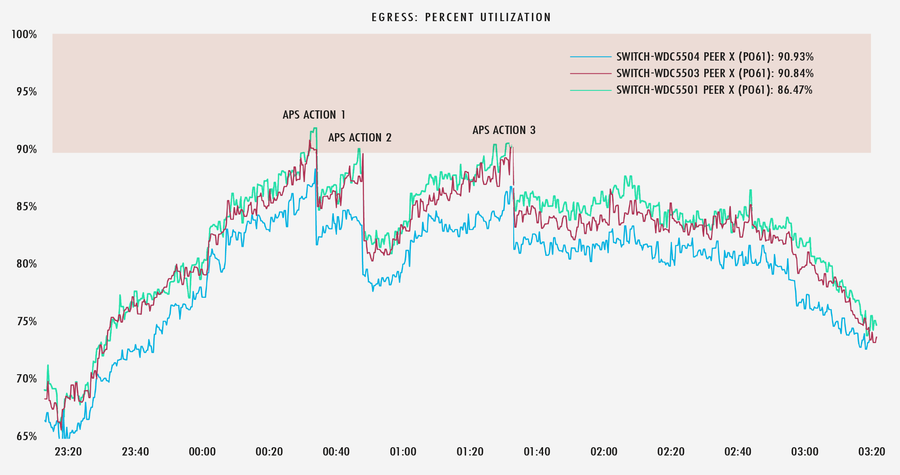
Hacia el final de un evento en vivo, conforme disminuye el tráfico pico, APS sabe cómo deshacer aquellas acciones y volver al estado inicial, por así decirlo.
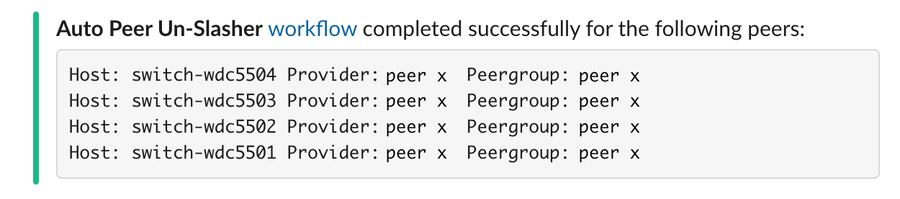
No obstante, la utilización de enlaces es solo una medida y no tiene por qué ser la solución a cualquier congestión potencial dentro de determinadas redes troncales o redes de ISP. Las tasas de pérdida y retransmisiones brindan información de gran utilidad, lo que nos permite observar y actuar en tiempo real mediante otra técnica que llamamos recuperación rápida de fallos en rutas (FPF). Nuestras cachés del edge supervisan el avance de los flujos de protocolo de control de transmisión (TCP) de usuarios finales individuales. Si el flujo parece detenerse en una ruta determinada, la caché provocará un intento automático de redirigir el flujo a una ruta alternativa con el objetivo de mantener una calidad de conexión y estado estables.
Cuando la cantidad de tráfico redirigido automáticamente supera la capacidad disponible de las rutas alternativas, o si la FPF es incapaz de encontrar rutas alternativas que no estén congestionadas, tenemos que decidir cómo continuar redirigiendo el tráfico. Este es el momento en que nuestro equipo entra en acción.
En grandes eventos pasados, hemos aprendido que poner a todo el mundo a trabajar en esta tarea añade complejidad a la ingeniería de tráfico. Si bien el equipo de ingenieros de red expertos de Fastly ya es un grupo efectivo y eficiente, hemos reducido aún más el número de ingenieros en los controles para eventos masivos en vivo, alrededor de 12 miembros. Dividimos la geografía en cuadrantes y asignamos un ingeniero principal a cada uno. Cada ingeniero principal se asocia con un ingeniero auxiliar que supervisa las alertas y los umbrales, va dando información según sea necesario y aporta verificación y validación secundarias de los cambios realizados por el responsable. Cuando nuestro cambio automático de tráfico de los enlaces directos del ISP comienza a alcanzar niveles superiores a la capacidad disponible del punto de presencia (POP), los dos ingenieros trabajan juntos para decidir cómo y hacia dónde migrar el tráfico a partir de ese momento. Para ello, suelen alterar los anuncios de difusión por proximidad del protocolo de puerta de enlace fronteriza (BGP) o influir en la selección del POP de los usuarios finales mediante nuestra plataforma de gestión del sistema de nombres de dominio (DNS). Así es cómo manejamos el proceso, que sucede tras bambalinas para garantizar una distribución sin trabas en tiempo real de cualquier evento en vivo.
Poner el proceso en práctica
La automatización y los sistemas descritos anteriormente se ejecutan a diario las 24 horas, lo cual representa una mejora que beneficia a todos nuestros clientes cuando se producen picos de tráfico. No obstante, siempre nos entusiasma ver cómo funciona durante subidas repentinas de tráfico y durante la preparación para grandes eventos de streaming en vivo.
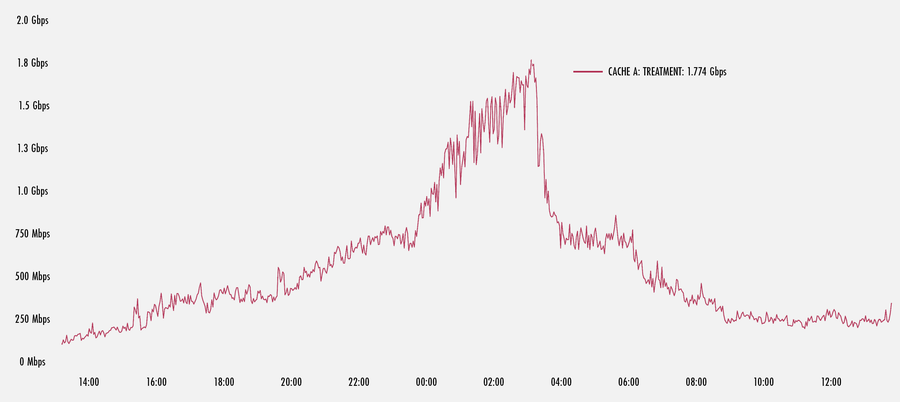
Como puedes ver en el siguiente gráfico, una subida repentina de tráfico en uno de nuestros POP de Estados Unidos provocó la activación de la FPF. Aquí vemos que una caché en el POP impulsa flujos de FPF a un pico de alrededor de 1,8 Gbps hasta que la subida repentina llega a su fin. Este es solo un pequeño porcentaje del tráfico total que recibió cobertura de esta máquina. No obstante, si se extrapola a muchas máquinas en un POP, el tráfico total que se atiende puede ser bastante alto.
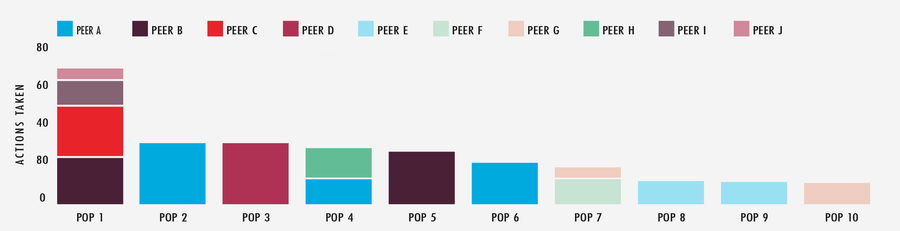
Si analizamos otro gran evento de varios días de duración, podemos ver el impacto significativo que tiene nuestro sistema APS. Observando un periodo de 48 horas en los 10 POP e interconexiones de partners más activos, vemos que APS realizó un total de 349 acciones contra la red. Gracias a que APS efectúa gran parte del esfuerzo, el equipo dedica su energía a ajustar algunas de las elecciones del sistema, al tiempo que centra su atención en otros elementos del rendimiento de la plataforma de edge cloud.
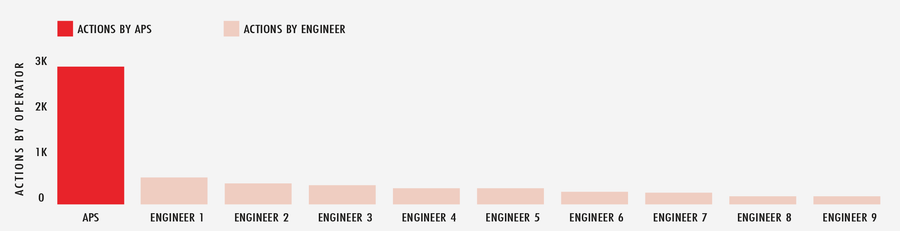
Si examinamos el mes de febrero de 2020 de forma más exhaustiva, APS ejecutó más de 2900 acciones automatizadas en toda la red global ante las condiciones cambiantes de internet, mientras que el ingeniero de turno más cercano apenas superó las 500. Dicho de otro modo: APS es como tener muchos jugadores adicionales en el campo.
Un streaming en vivo de éxito al alcance de la mano
Transmitir eventos de mucho tráfico en vivo es un enorme desafío. Sin embargo, nuestra plataforma está diseñada para afrontarlos sin más dificultades gracias a la automatización integrada, un grupo de ingenieros expertos y una red potente. Entendemos que la capacidad, tecnología y preparación son necesarias para que nuestros clientes puedan embarcarse en cada momento importante con entusiasmo, y con la seguridad de que su nombre, reputación y calidad de la experiencia están en buenas manos.