

Esta es la segunda parte de la serie dedicada a los ataques de denegación de servicio (DDoS). Consulta la primera parte aquí.
El pasado otoño, echamos un vistazo al panorama cambiante de los ataques de denegación de servicio para ofrecer una idea de la situación en términos de dimensiones y tipología de los ataques y ayudarte a tomar decisiones mejor informadas cuando se trata de proteger tu infraestructura. En Fastly, combinamos la investigación de la seguridad con las buenas prácticas en ingeniería de redes para ofrecerte información única sobre las tendencias de los ataques y de las tácticas de mitigación más eficaces.
En esta entrada, vamos a ofrecer:
Nuestra visión interna sobre cómo protegemos a nuestros clientes de los ataques
Lecciones aprendidas a partir de ataques de denegación de servicio reales
Nuestra lista de verificación recomendada para mitigar y evitar ataques DDoS
Vigilancia de los DDoS: investigación y red
En Fastly, hacemos un seguimiento de la actividad y la metodología en materia de DDoS, tanto observando los patrones de tráfico en nuestra red como a través de la investigación. Este método de doble vertiente nos mantiene al día en cuanto a los nuevos métodos que van surgiendo, lo que nos ayuda a contribuir a la mayor comunidad sobre seguridad en la red, además de proteger a nuestros clientes.
Investigación: la anatomía de un ataque
Nuestro equipo de investigación de seguridad utiliza el mecanismo honeypots, una configuración que permite detectar, desviar o contrarrestar los intentos de uso no autorizado de los sistemas de información y, específicamente en este caso, una versión modificada de nuestra herramienta de código abierto Cowrie para hacer un seguimiento de quién está sondeando nuestros sistemas, y lo que están tratando de hacer. Hemos probado cómo funcionarían una serie de dispositivos IoT no seguros en la web abierta y hemos obtenido resultados alarmantes:
Por término medio, se infectaba con código malicioso un dispositivo IoT y lanzaba ataque a los 6 minutos de haber sido expuesto en internet.
A lo largo de un día, se sondearon vulnerabilidades en los dispositivos IoT hasta 800 veces cada hora de atacantes de todo el planeta.
En un día, asistimos a un promedio de más de 400 intentos de inicio de sesión por dispositivo, una media de un intento cada 5 minutos; el 66 % de ellos con éxito.
Estos ataques a dispositivos IoT no son sofisticados, pero sí son efectivos cuando el usuario tiene 20.000 robots diferentes a su disposición, intentando abrirse paso por la fuerza. A menos que el usuario cambie las contraseñas de los dispositivos y los saque de la red, los atacantes los utilizarán para entrar y tomar el control. Es como si hubiéramos regresado a los años noventa, este es un gran retroceso en términos de asegurar internet.
El uso de honeypots para identificar botnets no es ninguna novedad y sigue siendo un método valioso para identificar las capacidades de ataque utilizadas en la realidad. Estudiando los programas maliciosos utilizados en las herramientas de estos ataques, las defensas pueden identificar las características del tráfico del ataque y aplicarlas para evitarlos. Así, por ejemplo, conocer las cadenas de consultas aleatorias que un robot podría utilizar durante una inundación de HTTP puede resultar útil para filtrar selectivamente esos robots de ataque en el tráfico legítimo.
A 665 Gbps, el mencionado ataque Mirai en Brian Krebs fue uno de los DDoS más conocidos en aquel momento (más tarde, en la misma semana, fue superado por el ataque de denegación de servicio de 1 Tbps en el OVH de la empresa de hosting). Krebs, un antiguo periodista del Washington Post creó su blog “Krebs on Security” para profundizar en los relatos de ciberdelincuencia. Comenzó cubriendo los ataques Mirai, que en la época se encontraban bajo el radar: su investigación periodística desenmascaró quién estaba detrás de los ataques y como represalia atacaron su propio blog, que finalmente desapareció de la red. Unos días después escribió sobre la democratización de la censura: no es la primera vez que se utilizan ataques de denegación de servicio para intentar silenciar una voz con la que no se está de acuerdo. La gran dimensión del ataque dio lugar a un debate que no se había suscitado antes y que incluyó preguntas como “¿Nos estamos planteando estos problemas de la forma correcta?” Los ataques de Krebs forzaron un debate.
Ingeniería de red: protección de la red
Para una visión realista de los DDoS, tomaremos como ejemplo un ataque contra nuestra red en marzo de 2016. Con 150 millones de paquetes por segundo (PPS) y más de 200 Gbps, fue un ataque cambiante de forma que mezcló inundaciones UDP, TCP ACK y TCP SYN y afectó toda la internet. Asistimos a una congestión de la red troncal del proveedor inmediato además de un elevado número de retransmisiones TCP a clientes en el extremo lejano. Cuando ves algo así saliendo de tu red sin saturar las interconexiones de tus proveedores, son varias las posibles causas: el proveedor de la red troncal podría estar teniendo problemas o la fuente de la congestión podría estar más arriba todavía, hacia la fuente del ataque. Durante el ataque fuimos testigos de considerables retransmisiones y nuestra red no estaba congestionada, lo que sugería que el enlace inmediato sí lo estaba y no todo el tráfico del ataque nos estaba llegando. Así, con toda probabilidad, el ataque superaba los 200 Gbps.
Unos minutos después de que comenzara el ataque, pusimos en juego nuestro proceso de comando de incidentes, así como a nuestro equipo de respuesta de seguridad en la red para que observara las características del ataque que hemos descrito. La comunicación es esencial, tanto la interna como la externa: nuestro paso siguiente fue publicar un estado de la situación destinado a los clientes y lo estuvimos actualizando durante el incidente. Este particular ataque tuvo una duración inusitada, ya que siguió ampliándose hacia nuestros POPs asiáticos al día siguiente. Nuestro equipo de Comando de Incidentes (IC, por sus siglas en inglés) utilizó técnicas de bifurcación y de aislamiento para amortiguar el ataque. Seguimos aplicando mitigaciones y finalmente los atacantes se retiraron.
En nuestro esfuerzo constante de supervisión de las tendencias y los patrones de los ataques, extraemos datos de Arbor Networks para hacer el seguimiento de las puntas máximas de los ataques mensualmente. Como puedes observar, el ataque de marzo de 2016 —con un gran salto de unos 600 Gbps— no siguió precisamente la tendencia:
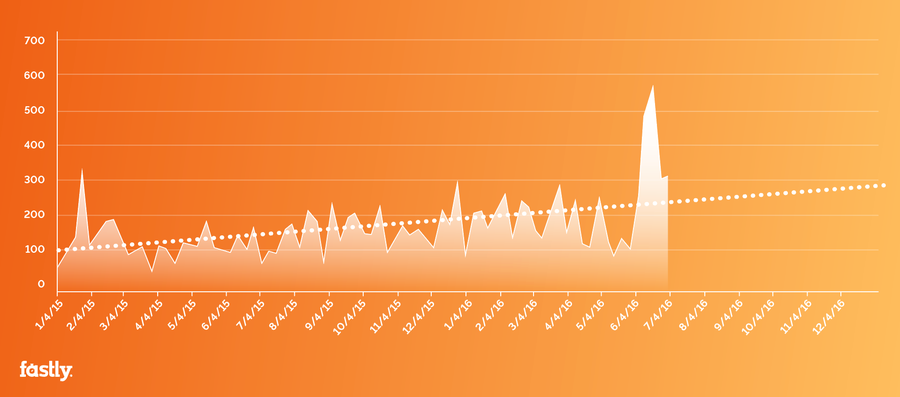
Fuente: Informe de seguridad sobre infraestructura mundial de Arbor Networks (Arbor Networks’ Worldwide Infrastructure Security Report)
La tendencia de la línea de puntos es la que se espera y para la que nos preparamos. Puesto que el ataque fue mucho mayor de lo esperado, forzó el rastreo de botnets y llevó a la comunidad de contramedidas de los DDoS a comenzar a hablar en términos distintos: teníamos que reevaluar la capacidad de ancho de banda de la mitigación y pensar en ataques múltiples, simultáneos y a gran escala (más de 500 Gbps). La conversación se globalizó e implicó a proveedores, CERT y a otros miembros de la comunidad de ciberdefensa de todo el mundo.
Los DDoS en perspectiva y lecciones aprendidas
Nuestros procesos durante el ataque de marzo de 2016 fueron dobles:
El Comando de Incidentes veló por la continuidad del negocio —fiabilidad y disponibilidad constante de la CDN.
Entretanto, nuestro equipo de respuesta de seguridad obtuvo la adhesión de la comunidad dedicada a la seguridad en la red para identificar las fuentes del flujo, los actores malintencionados, los programas maliciosos y los métodos y capacidades de ataque que podríamos recibir en el futuro.
Aprendimos algunas lecciones valiosas, tanto en términos de lo que funcionó como en términos de futuras áreas en las que trabajar. Las conclusiones siguientes del ataque de marzo de 2016 forman parte actualmente de una lista de validación para prepararnos ante futuros ataques:
Disponer de técnicas de bifurcación planeadas previamente. Demostraron ser inestimables en un momento tan delicado como el de mitigar un ataque DDoS y nos permitieron reaccionar rápidamente, lo que nos dotó de agilidad para dividir el tráfico y nos dejó espacio de maniobra, además de capacitar a nuestros equipos para saber cuándo recorrer a tales técnicas (y cuáles son sus consecuencias).
Mejora de las opciones de mitigación con una arquitectura de direcciones IP bien diseñada.
Infraestructura separada y direcciones IP de clientes, así como dependencias basadas en DNS. Esta es una buena práctica para cualquier proveedor: debes ser capaz de mantener tu infraestructura separada de las direcciones de los clientes y poder acceder a tu propio equipo si necesitas efectuar cambios.
Recopilación de información continuada sobre amenazas para comprender futuros vectores TTP.
Énfasis en la salud del equipo para resistir eventos de larga duración: ante la duración del incidente de marzo de 2016, resultaron cruciales los cambios de turno y las provisiones de alimentos. Nadie puede trabajar 24 horas seguidas.
Se debe tener en cuenta que un DDoS a menudo puede enmascarar otros eventos de disponibilidad del sistema. Como son tan ruidosos y acaparadores, su equipo podría centrarse completamente en los ataques DDoS y, entretanto, podrían ocurrir otras cosas.
Mantener la calma y mitigar
Como se ha comentado en la primera parte, la motivación de un ataque de denegación de servicio puede ser ideológica o económica. En ocasiones puede que alguien tenga interés en demostrar que puede desconectarte de la red. En realidad nunca podemos saberlo; uno no tiene ninguna idea de por qué recibe ataques DDoS. Así que no te rompas la cabeza; no tiene sentido. De un modo parecido, no puedes permitirte tomarte el tiempo necesario para hacer una autopsia del ataque más allá de un estadio rudimentario. Requiere de mucho tiempo, algo precioso durante un ataque de disponibilidad. También deberías buscar a un proveedor que pueda actuar rápidamente durante el tiempo en que lo necesites. En Fastly, nuestra filosofía consiste en prestar ayuda cuando nuestros clientes la necesitan, sin manipular los precios ni malgastar tiempo valioso negociando contratos. Por último, como director ejecutivo de Fastly, Artur Bergman aconseja con gran acierto: que no cunda el pánico. La solución está a tu alcance. Diseña un plan y síguelo. Con los sistemas adecuados, con listas de validación y con los socios adecuados, puedes hacer frente a los ataques DDoS.
Mantente al día: en nuestra siguiente entrada veremos cómo se defienden nuestros clientes de los ataques de denegación de servicio y de otras actividades delictivas. Y, para más información sobre cómo mitigar un ataque DDoS, puedes ver este vídeo de la charla del año pasado en Altitude NYC a continuación.