
Esta entrada es la primera de una serie sobre [la evolución del software de red en Fastly](https://vimeo.com/132842124). Dentro del sector, somos únicos en eso desde el principio, ya que siempre hemos visto las redes como una parte integral de nuestro producto en lugar de como un centro de costes. Sin embargo, rara vez comentamos lo que hacemos con la comunidad de redes en general, en parte porque nos basamos mucho más en la teoría de sistemas clásicos que en la práctica sobre redes de hoy en día.
### Crear abstracciones
Antes de seguir adelante, es importante aclarar que, aunque escribimos software para redes, no usamos el término «redes definidas por software» \(SDN\) para describir lo que hacemos.
Primero, porque el término SDN perpetúa la idea errónea de que las redes informáticas nunca han sido nada más que software \(«consenso aproximado y ejecución de código» ya era el lema del IETF mucho antes de que los proveedores de redes lo redujeran a una cuña publicitaria\). El propio término ha sido desde entonces adoptado y reinterpretado para legitimar enfoques específicos de gestión de redes. En el proceso, «SDN» ha acabado por convertirse en poco más que una palabra de moda, una voz compuesta tan desprovista de significado que nos lleva incluso a dudar de nuestra propia comprensión del problema.
Dada la magnitud de las redes modernas, es inevitable que el sector de las redes en general esté redescubriendo la importancia del software. Con las sucesivas oleadas de virtualización y, después, de contenedorización, no es raro que un solo bastidor de centro de datos contenga más puntos de conexión con una dirección única que los que tenía la totalidad de Internet hace solo tres décadas. Gestionar tantos dispositivos se ha vuelto muy complejo, por lo que es comprensible que la comunidad ahora esté más atenta a la necesidad de automatizar a fin de reducir la espiral de costes de la infraestructura operativa.
Aunque se trata de un avance importante, la automatización no es nuestro objetivo final. Nuestro principal objetivo es descubrir abstracciones eficaces para crear aplicaciones de red.
Si la línea de separación entre ambas parece sutil, conviene plantearse el reto de propagar la asignación entre nombres de host y direcciones a todos los nodos de una red. Hay muchas formas posibles de automatizar este proceso: desde usar algo tan sencillo como un proceso de cron hasta enviar nodos por correo electrónico con actualizaciones1. En cambio, la solución adoptada por los pioneros en Internet fue el sistema de nombres de dominio \(DNS\), un sistema de nomenclatura jerárquico descentralizado. Con el tiempo, la capa de direccionamiento indirecto que ofrece DNS ha sido crucial para desarrollar una serie de servicios de valor añadido, como las redes de distribución de contenido. La automatización ahorra tiempo, mientras que las abstracciones ponen el tiempo a tu servicio.
### Escalar horizontalmente
Nuestro equipo fundador era especialmente ducho en sistemas de alto rendimiento, que resultan esenciales para ofrecer un servicio de almacenamiento en caché distribuido y de baja latencia. Sin embargo, poner en marcha una red de distribución de contenido es complicado de por sí, dado que las principales empresas comienzan con una presencia geográfica más extensa. Por lo tanto, nuestra oferta inicial se centraba en lo que nuestro sector no había podido proporcionar: una visibilidad y un control sin precedentes sobre cómo se distribuye el contenido en el edge.
Durante los primeros años, nuestra falta de experiencia en redes no tenía demasiada importancia, ya que nuestros puntos de presencia \(POP\) solían constar de dos hosts conectados directamente a los proveedores a través del protocolo de puerta de enlace de borde \(BGP\). A principios de 2013 habíamos crecido tanto que este número de hosts ya no era suficiente. Escalar nuestra topología conectando más cachés directamente a nuestros proveedores, como se muestra en la figura 1a, no era la solución. Los proveedores son reacios a respaldar esta estructura debido al coste de los puertos y a lo complejo que resulta configurar sesiones de BGP adicionales.
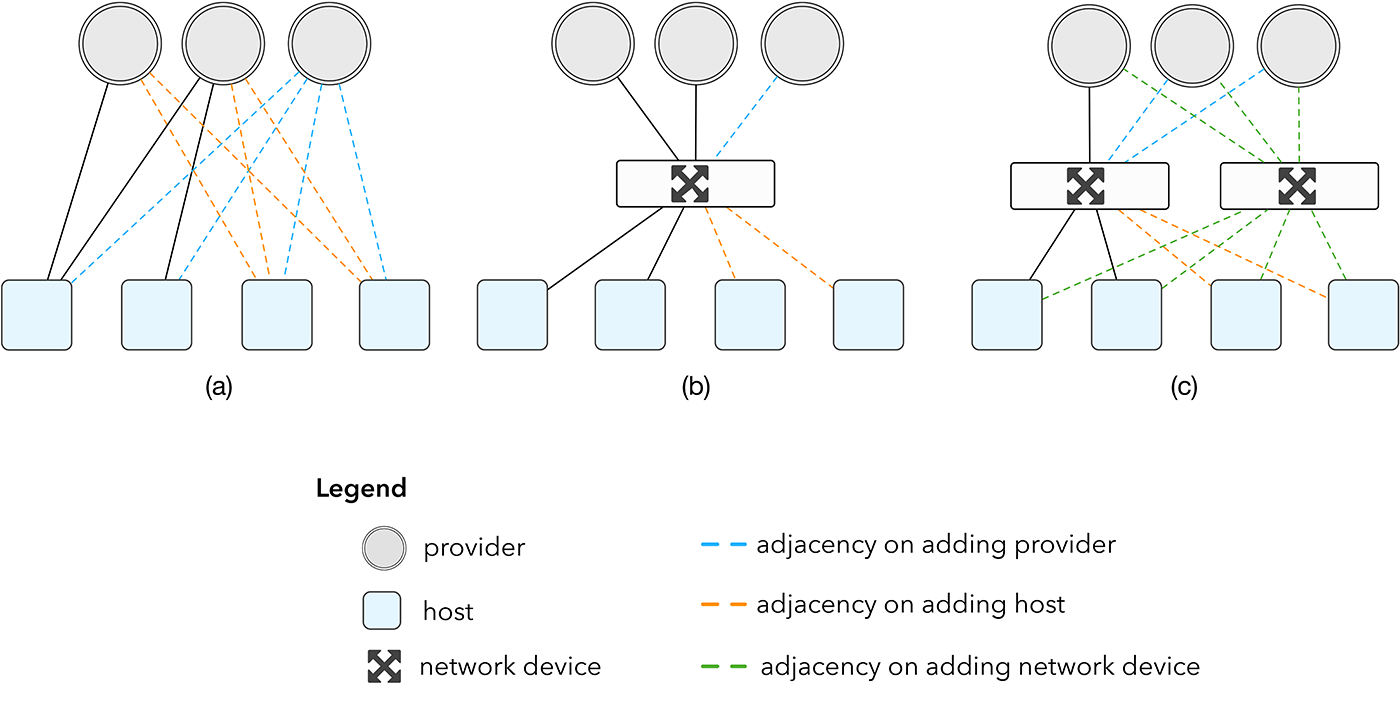
**Figura 1** : efectos de escalar la topología de red
Una solución obvia a este problema sería instalar un dispositivo de red, como se muestra en la figura 1b, que desvincule claramente el aumento del número de dispositivos del aumento del número de proveedores. Normalmente, este dispositivo de red sería un enrutador, que es un dispositivo muy especializado para el reenvío de tráfico, con un precio acorde. Esto sería una solución aceptable con un volumen total de dispositivos bajo, pero una red de distribución de contenido, por naturaleza, se amplía constantemente tanto geográficamente como en volumen de tráfico. Hoy en día, nuestro POP más pequeño cuenta con dos dispositivos de red como mínimo, como se muestra en la figura 1c.
En la figura 2 se ofrece una visión general de cómo funcionaría esa red con un enrutador. Un enrutador recibe las rutas directamente de los proveedores a través del BGP, y las inserta en la base de información de reenvío \(FIB\), la tabla de búsqueda implementada en el hardware utilizado para seleccionar rutas. A continuación, los hosts reenvían el tráfico al enrutador, que, a su vez, reenvía los paquetes al próximo salto más adecuado a la búsqueda resultante en la FIB del dispositivo.
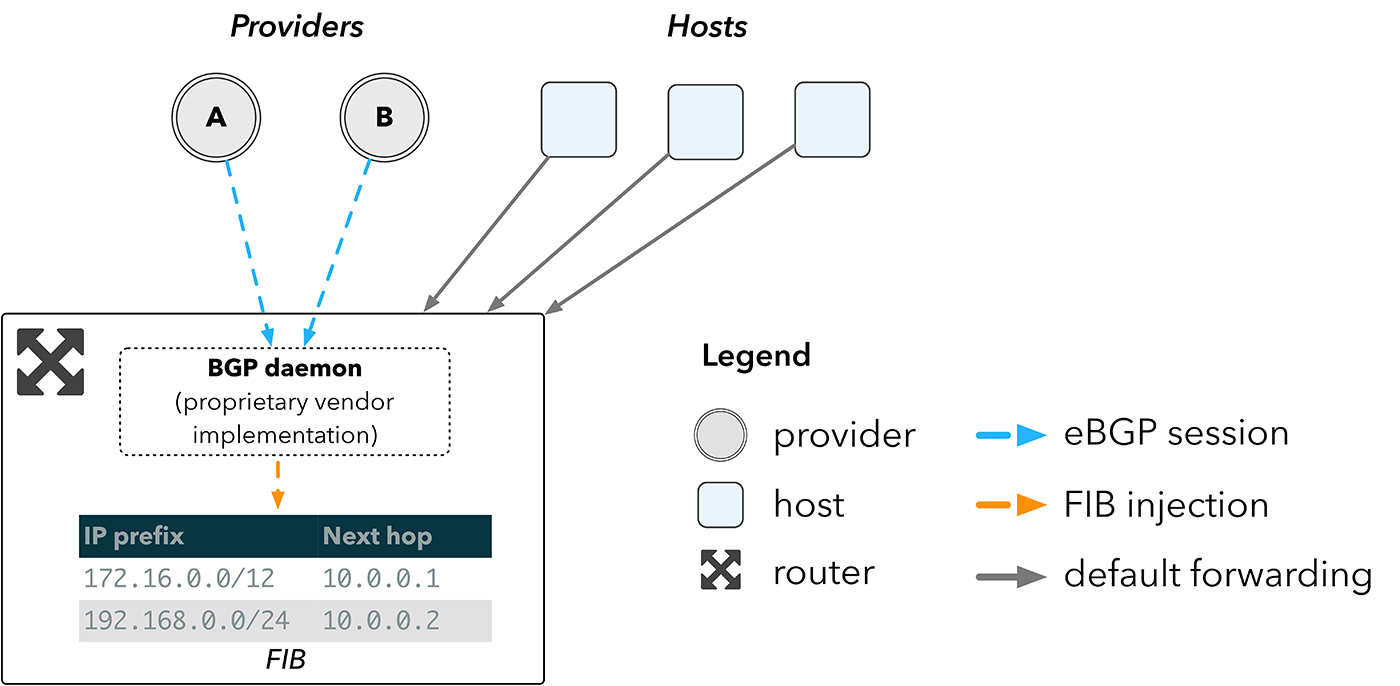
**Figura 2:** topología de la red con un enrutador
Cuanto mayor sea la FIB, más rutas admitirá un dispositivo. Lo malo es que la relación entre el tamaño de la FIB y el coste no es lineal. Los enrutadores de borde deben poder contener la tabla de enrutamiento de Internet completa, que actualmente tiene más las 600 000 entradas2. El hardware necesario para contener este espacio es el coste principal asociado a los enrutadores.
### Enrutar sin enrutadores
En los entornos tradicionales de informática en la nube, el coste de los enrutadores de borde se ve eclipsado rápidamente por el ingente volumen de servidores y conmutadores a los que deben prestar servicio. Sin embargo, en el caso de las CDN, el coste es mucho más que un mero inconveniente. Para acercar el contenido a los usuarios finales, las CDN deben tener un gran número de puntos estratégicos desde los que distribuir el contenido. Como resultado, los dispositivos de red pueden suponer una cantidad significativa del coste total de la infraestructura.
La idea de gastar varios millones de dólares en hardware de redes demasiado caro no era especialmente atractiva. Como ingenieros de sistemas, preferimos invertir el dinero en hardware de servidores básicos, lo que afecta directamente a la eficiencia con la que podemos distribuir contenido.
Lo primero que observamos fue que no necesitábamos la mayoría de las funciones que ofrecen los enrutadores, porque a corto plazo no nos planteábamos convertirnos en una empresa de telecomunicaciones. Los conmutadores parecían una propuesta mucho más interesante, pero carecían de la función que hacía que los enrutadores fueran útiles para nosotros: el espacio de FIB. Por entonces, los conmutadores solo podían contener decenas de miles de rutas en la FIB, lo que estaba a años luz de lo que realmente necesitábamos. En 2013, proveedores de hardware como Arista empezaron a proporcionar una función que podía superar esta limitación física: nos permitirían ejecutar nuestro propio software en los conmutadores.
Ahora que ya no estábamos obligados a cumplir el estricto protocolo del diseño de redes, nuestra solución empezó a cobrar forma relativamente rápido. En lugar de depender del espacio de FIB en un dispositivo de red, podríamos dirigir las rutas hacia los propios hosts. Las sesiones del BGP de nuestros proveedores seguirían terminando en el conmutador, pero desde allí las rutas se reflejaban en los hosts.
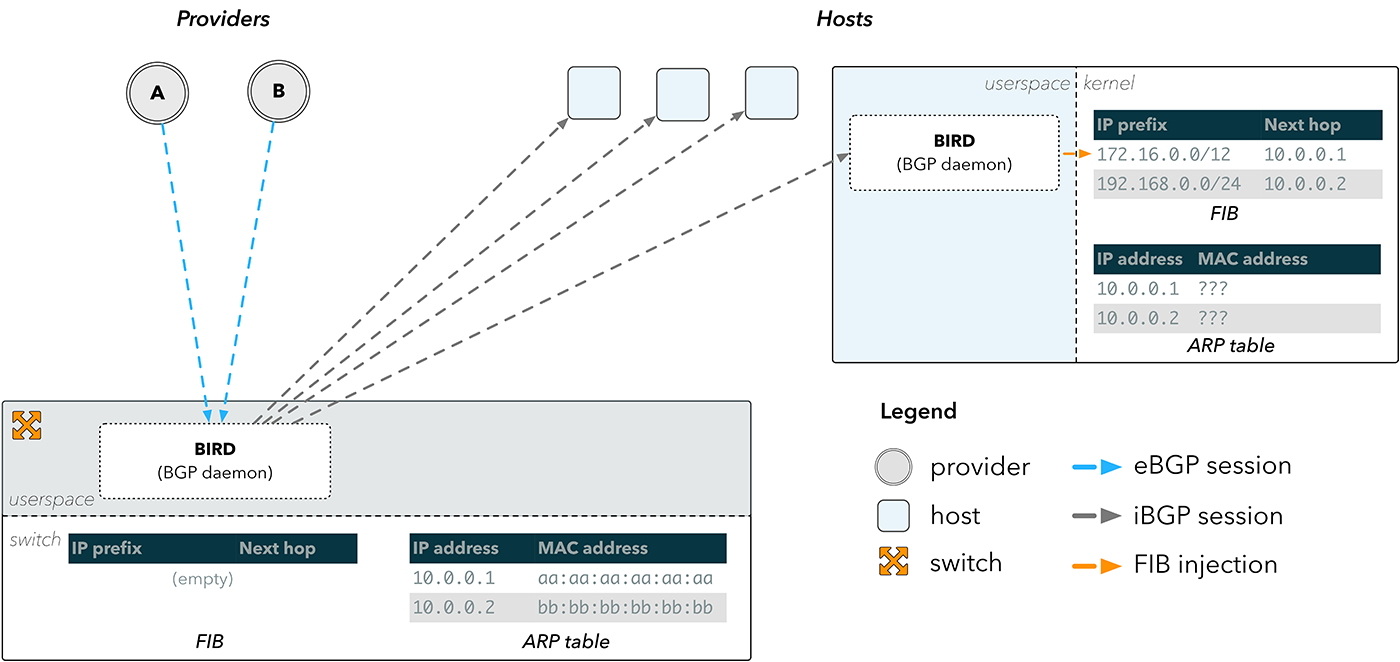
**Figura 3:** reflejo de rutas de BGP
Este planteamiento se presenta en la figura 3\. Una sesión de BGP externa \(eBGP\) se termina en un daemon BGP de espacio de usuario, como BIRD, que se ejecuta en nuestro conmutador. A continuación, las rutas recibidas se envían a través de sesiones de BGP internas \(iBGP\) hasta una instancia de BIRD que se ejecuta en los hosts y que luego inyecta rutas directamente en el kernel del host.
De este modo, se resuelve nuestro problema inmediato de evitar por completo la FIB del conmutador, pero no resuelve del todo el problema de cómo devolver los paquetes a Internet. Una entrada de FIB se compone de un prefijo de destino \(a dónde va un paquete\) y una dirección de próximo salto \(por dónde pasa\). Para reenviar un paquete a un próximo salto, un dispositivo debe conocer la dirección física del próximo salto en la red. Esta asignación se almacena en la tabla del protocolo de resolución de direcciones \(ARP\).
La figura 3 muestra que el conmutador tiene la información del ARP apropiada para nuestros proveedores, ya que está directamente conectado a ellos. Sin embargo, no ocurre lo mismo con los hosts, por lo que no pueden resolver ninguno de los próximos saltos que les llegan a través de BGP.
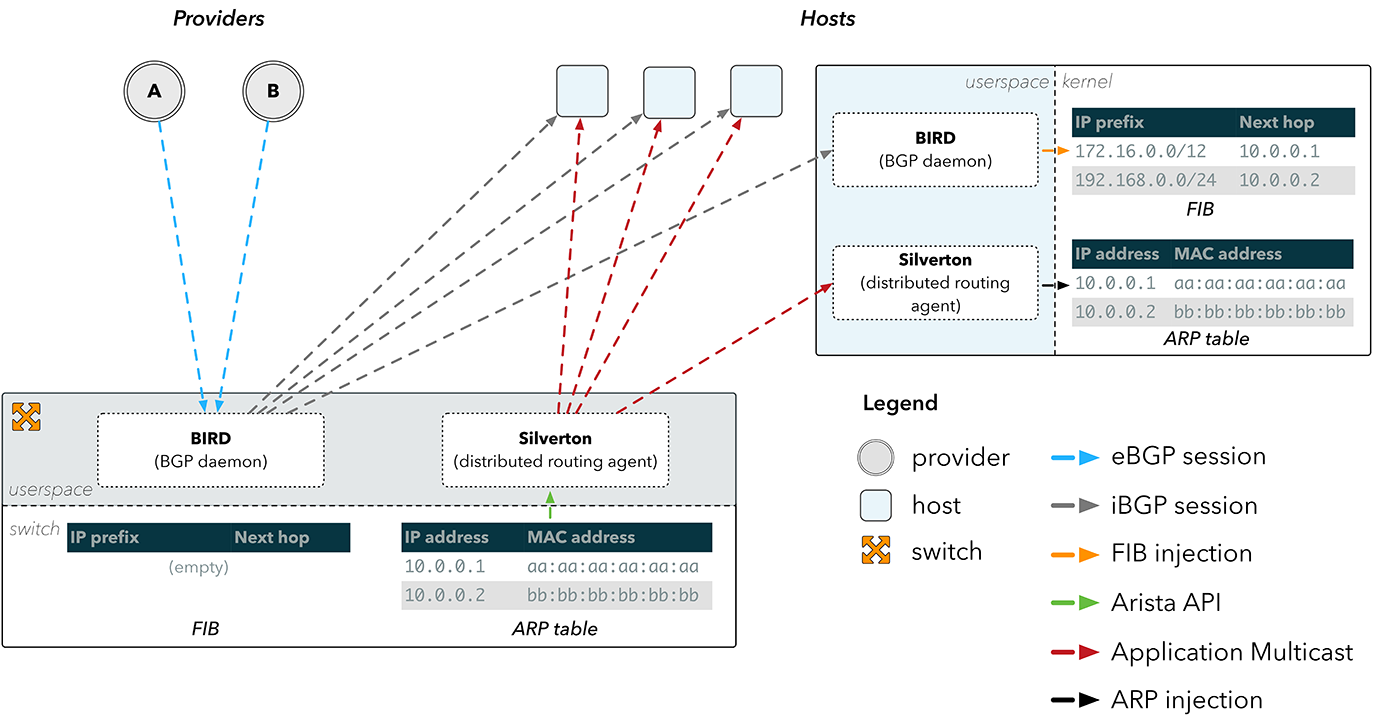
**Figura 4:** propagación de ARP mediante Silverton
### Silverton: un agente de enrutamiento distribuido
Y ese fue el punto de partida de Silverton, nuestro controlador de red personalizado que organiza la configuración de rutas dentro de nuestros POP. Nos dimos cuenta de que podíamos simplemente ejecutar un daemon en el conmutador que se suscribiera a los cambios en la tabla de ARP a través de la API proporcionada en los dispositivos Arista. Al detectar un cambio en la dirección MAC física de un proveedor, Silverton podría entonces diseminar esta información a través de la red, y los clientes en los hosts reconfigurarían nuestros servidores con datos sobre cómo llegar directamente a nuestros proveedores.
Para un proveedor de IP y una dirección MAC determinados, el primer paso del agente del lado del cliente de Silverton es engañar al host para que crea que la IP es accesible directamente a través de una interfaz, o enlace local. Esto se consigue configurando la IP del proveedor como un par en la interfaz, y se puede replicar fácilmente en Linux utilizando iproute:
$ ip addr add peer 10.0.0.1 dev eth0
Si el host cree que la IP del proveedor es el enlace local, se verá obligado a buscar la dirección MAC para esa IP en su tabla de ARP. Eso también podemos manipularlo:
$ ip neigh replace 10.0.0.1 lladdr aa:aa:aa:aa:aa:aa nud permanent dev eth0
Ahora, cada vez que una búsqueda de ruta para un destino devuelva el próximo salto `10.0.0.1`, terminará enviando el tráfico a `aa:aa:aa:aa:aa:aa:aa` directamente. El conmutador recibe *marcos* de datos desde el host hacia una dirección MAC física que se sabe que está directamente conectada. Puede inspeccionar la interfaz a través de la cual se reenvía el marco inspeccionando su tabla de direcciones MAC locales, que mantiene una asignación entre una dirección MAC de destino y la interfaz de salida.
Aunque todo este proceso puede parecer demasiado enrevesado para reenviar simplemente paquetes de un POP, nuestra primera iteración de Silverton contenía menos de 200 líneas de código y, aun así, nos ahorró inmediatamente cientos de miles de dólares por cada POP que desplegamos. Es importante destacar que, a diferencia del hardware, el software se puede ir mejorando gradualmente. Con el tiempo, Silverton ha llegado a abarcar toda nuestra configuración de red dinámica, y nos permite etiquetar campos de descripción, manipular anuncios de enrutamiento y purgar sesiones de BGP, entre otras cosas.
Sin embargo, más que ahorrarnos dinero, Silverton nos proporcionó una valiosa abstracción. Creaba la «ilusión» de que cada host está directamente conectado a cada proveedor, lo cual era nuestro punto de partida \(figura 1a\). Al mantener varias tablas de enrutamiento en el kernel y seleccionar en qué tabla había que buscar por paquete, pudimos crear herramientas y aplicaciones basadas en Silverton que pueden anular la selección de rutas. Ejemplo de ello es una utilidad interna llamada *st\-ping* , que comprueba la disponibilidad de un destino en todos los proveedores conectados:
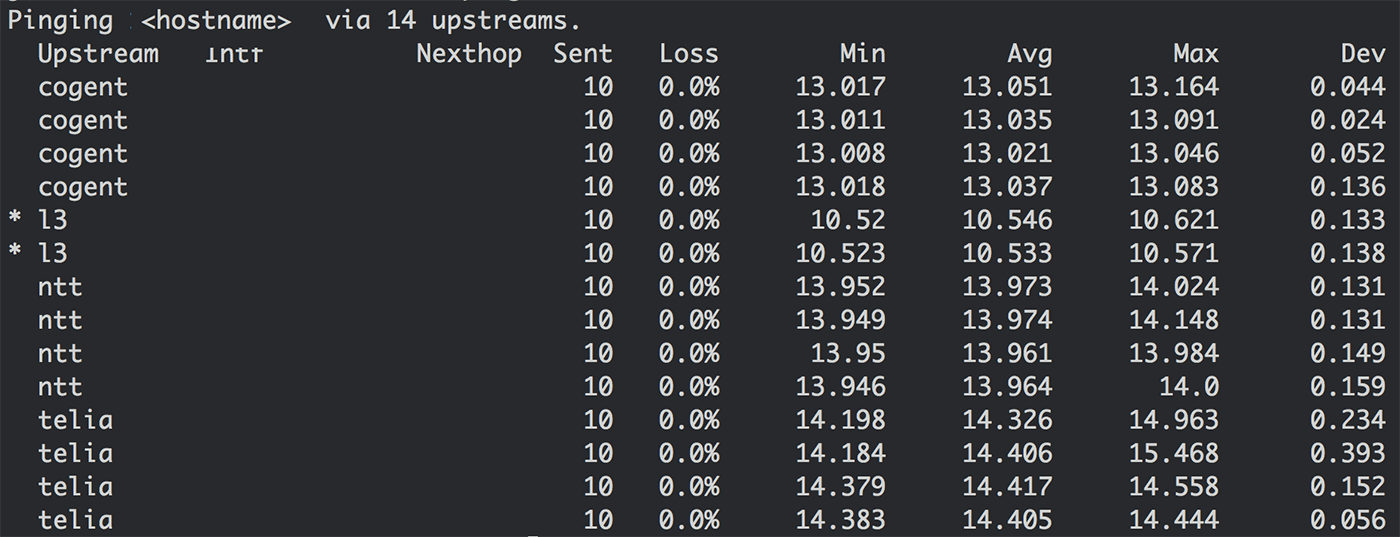
**Figura 5:** comprobación de disponibilidad de todos los proveedores de tránsito en un POP. El retraso se muestra en una sola IP de destino y, por lo tanto, no es representativo del rendimiento general del proveedor.
Insertar la selección de ruta directamente en la aplicación nos permitió examinar en mayor profundidad el comportamiento de la red, lo que nos ayudó a mejorar el rendimiento de la distribución de contenido en el edge.
### A continuación: ¿de qué más nos podemos librar?
Silverton nos recordó que cada cosa tiene su tiempo.
Si hubiéramos intentado implementar Silverton dos años antes, nos habríamos topado con un muro: ningún proveedor del mercado nos habría proporcionado acceso programático a los componentes de red básicos que necesitábamos. Por suerte, justo cuando estábamos buscando conmutadores, Arista empezaba a formalizar el acceso a las API internas en sus dispositivos.
Si hubiéramos intentado implementar Silverton en la actualidad, llevaríamos mucho tiempo creyendo el engaño colectivo de que se necesitan enrutadores para enrutar. Resulta que es tan caro deshacerse de los enrutadores como adquirirlos, ya que las personas que hay que contratar para configurarlos son tan especializadas como el hardware que mantienen. Al prescindir por completo de los enrutadores pudimos crear un equipo de redes con una mentalidad diferente sobre cómo debe funcionar una red, y hemos estado cosechando los frutos desde entonces.
Mientras validábamos la primera prueba de concepto de Silverton a principios de 2013, se nos planteó una pregunta lógica: *¿de qué más nos podemos librar?* En la siguiente entrada de esta serie veremos cómo aplicamos los mismos principios de engaño para manejar el tráfico entrante y realizar un equilibrio de carga perfecto.
*** ** * ** ***
1 RFC849: Suggestions for improved host table distribution \(https://tools.ietf.org/html/rfc849\)
2 Growth of the BGP Table http://bgp.potaroo.net/
Sólo disponible en inglés
Por el momento, esta página solo está disponible en inglés. Lamentamos las molestias. Vuelva a visitar esta página más tarde.