

Si tu aplicación está disponible en internet, es probable que haya sufrido ataques de automatización abusiva, como la extracción de contenidos, el relleno de credenciales, la DDoS de aplicaciones, el abuso de formularios web o la adivinación de tokens. Los programas que automatizan estas actividades se consideran bots, y el uso malicioso de herramientas automatizadas entra dentro de la categoría de amenazas automatizadas. En cuanto a los agentes involucrados, suelen ser organizaciones del cibercrimen, pero en ocasiones también puede tratarse de particulares que buscan sacar un beneficio personal, como en el caso de las pujas a última hora en eBay.
Para entender y mitigar la automatización abusiva antes de que afecte a tu negocio, es básico conocer las técnicas y tácticas empleadas. Si puedes emular ataques automatizados de distinta complejidad, conseguirás información valiosa y podrás comprobar que tus controles de seguridad funcionan como es debido.
En este artículo repasaremos varios tipos de bots, métodos y herramientas que tu equipo rojo puede usar para realizar pruebas. Asimismo, veremos cuáles elegir y cómo aprovechar su funcionalidad inicial para aumentar su sofisticación. Finalmente, enumeraremos medidas defensivas de seguridad que incrementan la dificultad y el coste de los ataques.
Clientes no basados en navegadores
En su forma más habitual, la automatización se sirve de clientes no basados en navegadores, como Python, Go o cURL. Estos tipos de bots pueden ser desde herramientas comerciales listas para usar hasta proyectos de código abierto, y sirven para extraer datos, realizar pruebas de penetración y mucho más. Basta con buscar #pentest en GitHub para obtener resultados de lo más interesantes.
La captura siguiente muestra un ejemplo de un bot desarrollado en Python que se aprovecha de las peticiones y las bibliotecas de BeautifulSoup para extraer y analizar datos de un sitio web:
import requests
from bs4 import BeautifulSoup
page = requests.get(url='https://example.com')
content = BeautifulSoup(page.content, 'html.parser')Al contrario que los clientes de navegadores, los clientes no basados en navegadores no ejecutan código de JavaScript. Las soluciones avanzadas contra bots utilizan JavaScript para recopilar e informar automáticamente de atributos relacionados con la configuración del navegador y el sistema, lo que se denomina detección del lado del cliente. Si estos datos no se devuelven en las peticiones del cliente, es un buen indicio de que se trata de un bot.
Marcos de trabajo de la automatización en navegadores
Por muy útiles que puedan ser las herramientas no basadas en navegadores a la hora de lanzar ataques, también resultan muy fáciles de detectar. Una de las principales dificultades a las que se enfrentan los desarrolladores de bots son las soluciones de seguridad que se dedican a reconocerlos y bloquearlos, pero pueden burlarlas haciéndose pasar por tráfico humano.
Los marcos de automatización en navegadores, como Puppeteer y Playwright, gozan de gran popularidad para crear bots cuasihumanos. Al operar con navegadores reales, permiten ejecutar código JavaScript y pueden automatizar una serie entera de tareas que imite a un usuario real, como cargar una página, mover el ratón o escribir texto.
Estos marcos de automatización se pueden utilizar para instrumentar navegadores, cuenten o no con una interfaz gráfica de usuario (GUI). Los navegadores sin GUI, denominados «headless», ofrecen la misma funcionalidad que los navegadores reales, pero requieren mucho menos de la CPU y la RAM, ya que no tienen que manipular gráficos ni otros componentes de la interfaz de usuario. El navegador headless más popular es Headless Chrome.
El fragmento siguiente es un ejemplo de script de Puppeteer que lleva a https://example.com/ y guarda una captura de pantalla como example.png en modo headless:
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://example.com/');
await page.screenshot({ path: example.png' });
await browser.close();
})();Por muy divertido que pueda resultar escribir código, para desarrollar estos scripts hacen falta tiempo y pericia, pero hay herramientas que pueden ser de ayuda. Por ejemplo, Google introdujo Recorder, disponible en Chrome Developer Tools (a partir de la versión 97 de Chrome), que permite grabar y reproducir movimientos del usuario dentro del panel de grabación, así como exportarlos a un script de Puppeteer sin tener que escribir una sola línea de código.
Bots a la venta
Cuando nos imaginamos un atacante, es fácil caer en el estereotipo de un genio malvado capaz de penetrar sistemas en cuestión de minutos con unas pocas líneas de código. Si bien este cliché puede reflejar parte de la verdad, en la mayoría de ocasiones es poco más que una exageración fantasiosa. En realidad, los cibercriminales suelen buscar la ruta que presente menos resistencia, y se sabe que es difícil crear y ejecutar bots. Dado que la mayoría de ciberdelincuentes prefiere alcanzar sus objetivos lo más rápido posible, no es de extrañar que exista, pues, un mercado de compraventa de bots.
Este es el caso, en especial, del sector minorista y los bots de zapatillas: cuando salen al mercado zapatillas en unidades limitadas, suele producirse una carrera entre coleccionistas para comprarlas antes de que se agoten. Los bots de zapatillas están pensados para hacer que este proceso sea instantáneo y adelantarse a los compradores que realizan la operación de forma manual. No obstante, el uso de este tipo de bots compradores va más allá de las zapatillas y abarca cualquier artículo con disponibilidad limitada.
En general, estos servicios de bots no suelen ser ilegales, y sus autores acostumbran a anunciar el lanzamiento de sus productos en Twitter. Sin embargo, sí que violan las condiciones establecidas en muchos sitios web y perjudican la reputación y la fidelidad de las marcas, ya que afectan de forma artificial la capacidad de comprar un producto. Por si esto fuera poco, aumentan los costes de infraestructura y sobrecargan el sitio, lo que deteriora su rendimiento.
Otro tipo de bots que suelen estar a la venta son las botnets, un grupo de máquinas infectadas con malware. RaidForums, un foro de cibercrimen que fue embargado hace poco, y otros foros parecidos han recibido denuncias por la compraventa de botnets. Estas pueden crecer hasta incluir cantidades enormes de bots. Una botnet grande que cuente con millones de equipos se puede utilizar para lanzar un ataque de denegación de servicio distribuido (DDoS), mientras que una botnet pequeña puede llegar a realizar una intrusión dirigida a un sistema valioso, como datos gubernamentales o financieros.
Imitación de la automatización malintencionada
Hasta ahora hemos presentado varios tipos de bots, como los clientes no basados en navegadores (que se sirven de navegadores headless) y bots que se pueden comprar. En este apartado repasaremos los métodos y las herramientas que pueden utilizar los equipos rojos, cómo elegirlos y cómo aprovechar su funcionalidad inicial para aumentar su sofisticación.
Primera fase
Empecemos con nuestro primer ejemplo de un bot desarrollado en Python, que se sirve de las peticiones y las bibliotecas de BeautifulSoup para extraer y analizar datos de sitios web:
import requests
from bs4 import BeautifulSoup
page = requests.get(url='https://example.com/')
content = BeautifulSoup(page.content, 'html.parser')Se trata de un script muy básico que realiza una petición GET y devuelve un objeto BeautifulSoup. Ejecutemos este script y veamos la petición HTTP que se envió:
GET / HTTP/2
Host: example.com
User-Agent: python-requests/2.28.0
Accept-Encoding: gzip, deflate
Accept: */*
Connection: keep-aliveHay varios aspectos que es importante señalar en esta petición. Si miramos el encabezado User-Agent, veremos que anuncia python-requests/2.28.0. Además, el encabezado Accept tiene el valor */*. La utilidad del encabezado Accept radica en que comunica al servidor el tipo de contenido que puede manejar el cliente. La directiva */* acepta cualquier tipo.
Ahora, realicemos la misma petición en un navegador Chrome:
GET / HTTP/2
Host: example.com
Sec-Ch-Ua: "-Not.A/Brand";v="8", "Chromium";v="102"
Sec-Ch-Ua-Mobile: ?0
Sec-Ch-Ua-Platform: "macOS"
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.61 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Sec-Fetch-Site: none
Sec-Fetch-Mode: navigate
Sec-Fetch-User: ?1
Sec-Fetch-Dest: document
Accept-Encoding: gzip, deflate
Accept-Language: en-US,en;q=0.9Las diferencias entre las dos peticiones son claras. Los encabezados User-Agent y Accept son distintos, pero además la petición del navegador incluye nueve encabezados adicionales que no están en la del bot desarrollado en Python. Estos elementos se usan para distinguir a los usuarios humanos de los bots, de modo que, para defenderse de ellos, se puede bloquear su tráfico con base en esa información.
Teniendo esto en cuenta, podemos modificar nuestro bot de Python para que se parezca a la petición realizada a través del navegador:
import requests
from bs4 import BeautifulSoup
headers = {
'Sec-Ch-Ua': '"-Not.A/Brand";v="8", "Chromium";v="102"',
'Sec-Ch-Ua-Mobile': '?0',
'Sec-Ch-Ua-Platform': 'macOS',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.61 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Sec-Fetch-Site': 'none',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-User': '?1',
'Sec-Fetch-Dest': 'document',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'en-US,en;q=0.9',
}
page = requests.get(url='https://example.com/')
content = BeautifulSoup(page.content, 'html.parser')Ejecutemos este script y veamos la petición HTTP que se envió:
GET / HTTP/2
Host: example.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.63 Safari/537.36
Accept-Encoding: gzip, deflate
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Connection: keep-alive
Sec-Ch-Ua: "-Not.A/Brand";v="8", "Chromium";v="102"
Sec-Ch-Ua-Mobile: ?0
Sec-Ch-Ua-Platform: macOS
Upgrade-Insecure-Requests: 1
Sec-Fetch-Site: none
Sec-Fetch-Mode: navigate
Sec-Fetch-User: ?1
Sec-Fetch-Dest: document
Accept-Language: en-US,en;q=0.9A primera vista, parece que la petición ya incluye todos los encabezados, pero si nos fijamos, resulta que el script de Python no mantuvo el orden de los encabezados de las peticiones. La mayoría de las bibliotecas usa un orden sin definir, dado que, según la especificación de las RFC, no tiene importancia. Sin embargo, la mayoría de los navegadores envían los encabezados HTTP en un orden concreto, y esta sutil diferencia es una técnica más que se puede usar para reconocer tráfico automatizado. Por suerte, la biblioteca de peticiones de Python permite mantener el orden de los encabezados en el script.
Segunda fase
Estamos aumentando la sofisticación para evitar que nos detecten, pero hay que tener en cuenta que las soluciones de seguridad se basan en métodos de comportamiento para distinguir a los bots de los humanos, puesto que actúan de forma distinta a los usuarios legítimos. Para realizar el seguimiento de la conducta de un usuario durante su sesión, estos métodos suelen asociar dicho comportamiento a una dirección IP (reputación de IP).
Hay varios tipos de patrones de comportamiento que se pueden asociar a una dirección IP, como por ejemplo:
número total de peticiones;
número total de páginas visitadas;
tiempo entre visitas a páginas;
secuencia de páginas visitadas;
tipos de recursos cargados en las páginas.
Basándonos en nuestro script de ejemplo, si nos pusiéramos a extraer grandes cantidades de datos, quedaríamos expuestos o bloqueados mediante uno de estos patrones, de modo que intentaremos rotar la dirección IP cada ciertos intentos para evitar que nos limiten el volumen o nos bloqueen. Para ello, podemos utilizar un servidor proxy. Un proxy actúa de intermediario entre un cliente y el resto de la web. Cuando se envía una petición a través de un proxy, se expone la dirección IP del proxy y, por tanto, se oculta la IP del cliente real (o bot).
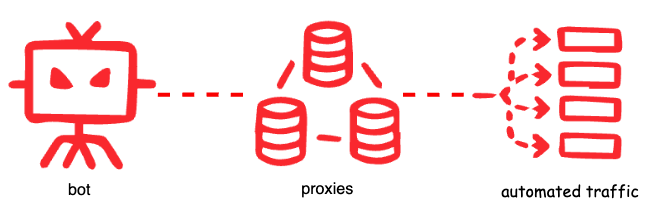
El tipo de proxy que necesites depende de las restricciones que intentes burlar. Si usas IP de centros de datos, VPN, servidores proxy conocidos o redes de Tor, es mucho más probable que llames la atención durante el análisis, o que ya hayas levantado sospechas. Así pues, todo bot sofisticado suele servirse de proxis residenciales menos conocidos. Dado que las IP residenciales las usan usuarios legítimos, estas gozan de mejor reputación que los otros tipos.
No obstante, antes de enfrascarte en configurar los servicios del proxy, asegúrate de que la aplicación que quieres atacar confía en la dirección IP remota del cliente indicada en encabezados de peticiones como X-Forwarded-For, True-Client-IP o X-Real-IP. Los atacantes pueden aprovecharse de ello proporcionando una dirección IP suplantada. De hecho, el equipo de Security Research de Fastly realizó una contribución a Nuclei que permite inyectar una dirección IP arbitraria en cualquier encabezado de una petición HTTP para intentar aprovecharse de esta vulnerabilidad y emular el comportamiento de un proxy.
Aparte de la dirección IP, también se ha extendido el uso de las huellas digitales de TLS para indicar el tipo de cliente que se comunica con un sitio. Dichas huellas identifican un dispositivo mediante conjuntos de cifrado TLS compatibles. Encontrarás más información sobre las huellas digitales de TLS en nuestro artículo del blog El estado del registro de huellas digitales de TLS. Este método de detección no está exento de riesgos, ya que el cliente tiene el control del paquete ClientHello y, por tanto, un bot podría cambiar la huella digital. Existen herramientas, como uTLS, que se pueden usar para imitar firmas TLS.
Tercera fase
Hasta ahora, hemos repasado métodos que utilizan elementos del lado del servidor, pero una solución antibots que solo ofrezca detección en esa área no es completa. Los bots avanzados, al contrario que los bots no basados en el navegador, utilizan marcos de automatización del navegador que aprovechan navegadores reales, de modo que pueden falsificar las huellas digitales HTTP y TLS de usuarios legítimos y ejecutar código JavaScript.
Para detectar bots avanzados, es clave contar con detección en el lado del cliente. Este tipo de detección da cuenta de eventos y atributos como movimientos del ratón, teclas pulsadas, resolución de la pantalla y propiedades del dispositivo que se recopilan mediante JavaScript. Estos scripts comprueban la presencia de atributos que se observan en navegadores headless o en marcos de instrumentación.
Por ejemplo, una técnica que se usa en este tipo de detección es comprobar si hay códecs de audio y vídeo. El siguiente fragmento de código analiza si hay tipos de archivos multimedia compatibles mediante la función canPlayType:
const audioElt = document.createElement('audio')
return audioElt.canPlayType('audio/aac')En caso de un navegador Chrome legítimo, tendría que devolver el valor «probably». Así, podemos modificar el script de Puppeteer que usamos en un ejemplo anterior para comprobar que devuelva el valor previsto:
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://example.com');
await page.screenshot({ path: example.png' });
const audioElt = await page.evaluate(() => {
let obj = document.createElement('audio');
return obj.canPlayType('audio/aac');
})
console.log(audioElt);
await browser.close();
})();Por desgracia, devuelve un valor vacío. Asimismo, reconocemos Headless Chrome en el lado del servidor por su agente de usuario:
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) HeadlessChrome/103.0.5058.0 Safari/537.36De forma predeterminada, Puppeteer no oculta elementos que son indicios evidentes de detección, sino que expone el hecho de que está automatizado. Puppeteer está pensado principalmente para automatizar pruebas en sitios web, no para crear bots cuasihumanos que burlen cualquier detección. Sin embargo, como cabría esperar, existe una biblioteca de código abierto llamada puppeteer-extra que ofrece un complemento sigiloso que permite a los desarrolladores de bots modificar esas funcionalidades predeterminadas y aplica varias técnicas para dificultar la detección de puppeteer headless.
La principal diferencia radica en que no puedes importar puppeteer, pero sí puppeteer-extra:
const puppeteer = require('puppeteer-extra');
puppeteer.use(require('puppeteer-extra-plugin-stealth')());Ahora deberías poder comprobar que los códecs y el agente de usuario de salida del bot encajan con un navegador Chrome legítimo:
const userAgent = await page.evaluate(() => {
return navigator.userAgent;
})
console.log(userAgent);
// Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5109.0 Safari/537.36
const audioElt = await page.evaluate(() => {
let obj = document.createElement('audio');
return obj.canPlayType('audio/aac');
})
console.log(audioElt);
// probablyHay muchas otras formas de detectar este comportamiento orquestado del navegador, lo cual subraya la importancia de entender las limitaciones actuales de las protecciones de tu aplicación y pensar en maneras de minimizar aún más ese riesgo.
Resumen
Para detectar y bloquear cualquier automatización abusiva, es necesario contar con análisis y sofisticación avanzados. Dado que hay tráfico de bots inocuo (como cuando una empresa ofrece bibliotecas de clientes en múltiples idiomas para facilitar el acceso a sus servicios), es clave entender el tipo de tráfico y los dispositivos que se prevén en tu infraestructura. Que el tráfico sea inocuo o dañino depende del contexto y de lo que aceptes como divergencia del comportamiento previsto mediante la automatización.
Si emulas la automatización abusiva contra tu propia infraestructura, tus equipos podrán entender mejor lo que se puede definir como aceptable. Al conocer los distintos tipos de bots y experimentar con técnicas de ataque, contarás con una mejor preparación para mitigar la automatización abusiva y proteger los activos más importantes de tu organización.