



Wenn wir gefragt werden, was uns vom Wettbewerb abhebt, betonen wir häufig unsere leistungsstarken POPs</u> und unsere moderne Architektur</u>. Heute möchten wir Ihnen einen weiteren Blick hinter die Kulissen bieten und Ihnen zeigen, welche Innovationen sich in einem modernen, vollständig softwaredefinierten Netzwerk erzielen lassen.
Im Februar dieses Jahres stellte Fastly während des Super Bowl einen neuen Traffic-Rekord von 81,9 Tbit/s</u> auf, und dank Autopilot waren keinerlei Anpassungen der Egress-Richtlinien nötig, um den Traffic während des Events problemlos zu bewältigen. Autopilot ist unser neues Automatisierungssystem für ausgehenden Traffic, mit dem selbst an diesem rekordverdächtigen Tag kein menschliches Eingreifen erforderlich war. So konnte innerhalb des Fastly Netzwerks bei gleichzeitiger Reduzierung des Personalaufwands für die Verwaltung zum allerersten Mal ein neuer Traffic-Rekord aufgestellt werden. (Tatsächlich kamen wir hier sogar ganz ohne Personal aus.) Viele Mitarbeiter aus verschiedenen Fastly Teams haben unglaublich hart daran gearbeitet, die Selbstverwaltungsfähigkeiten unseres Netzwerks zu verbessern. Das Ergebnis: ein vollständig automatisiertes Netzwerk, das schneller und häufiger auf Ausfälle, Engpässe und Performance-Einbußen reagieren kann, ohne dass manuelle Eingriffe erforderlich sind.
Autopilot hat zahlreiche Vorteile für Fastly, noch besser ist diese Funktion aber für unsere Kunden. Sie können sich nämlich jetzt mehr als je zuvor darauf verlassen, dass wir Ereignisse wie Ausfälle von Netzwerkanbietern oder DDoS-Angriffe und unerwartete Traffic-Spitzen im Griff haben, ohne dabei das Erlebnis ihrer Endnutzer zu beeinträchtigen. Sehen wir uns also an, wie wir es so weit gebracht haben und wie zuverlässig Autopilot funktioniert. (Wenn Sie noch kein Fastly Kunde sind, setzen Sie sich gerne mit uns in Verbindung</u> oder starten Sie mit unserer kostenlosen Testversion</u>.)
Vor genau drei Jahren haben wir darüber berichtet, wie wir den Traffic während des Super Bowl 2020 gemanagt haben</u>. Damals kümmerte sich eine ältere Version unserer Traffic-Automatisierung um das häufige Kapazitätsengpässe manövrierende Routing. Die Bediener der Software mussten bloß bei komplexen Fällen Hand anlegen. Dieser Ansatz war für das Traffic-Aufkommen und die Netzwerkauslastung von vor drei Jahren gut geeignet, führte aber zu Einschränkungen bei der Skalierung der entsprechenden Infrastruktur, da zwar ein geringerer Personalaufwand erforderlich war, unsere Teams aber trotzdem auf Kapazitätsengpässe reagieren mussten. Dies bedeutete wiederum Engpässe bei der Personalbeschaffung und beim Onboarding, da wir beim Ausbau der Anzahl der Netzbetreiber mindestens mit dem Wachstum unseres Netzwerks Schritt halten mussten. Hinzu kam, dass wir uns zwar auf ein geplantes Event wie den Super Bowl vorbereiten und effektiv arbeiten konnten, der Mensch aber nicht immer zu Höchstleistungen fähig ist, wenn er mitten in der Nacht geweckt wird, um sich mit unerwarteten Internetproblemen auseinanderzusetzen.
So gelang uns die vollständige Automatisierung mit Autopilot und Precision Path
Die einzige Lösung war, die Gleichung ganz ohne die menschliche Komponente aufzustellen. Dank einer einzigen Verbesserung können wir jetzt mühelos skalieren und gleichzeitig Kapazitäts- und Performance-Problemen viel besser entgegenwirken. Menschliches Eingreifen ist immer mit Kosten verbunden. Es erfordert eine Person, die über das jeweilige Problem nachdenkt und eine Entscheidung trifft. Um diese Person nicht zu überlasten, soll sie erst dann eingreifen, wenn das Problem bereits so groß ist, dass es die Performance unserer Kunden beeinträchtigt. Außerdem bedeuten von Menschenhand durchgeführte Maßnahmen in der Regel, dass mehr Traffic umgeleitet wird. Auf diese Weise soll vermieden werden, dass das gleiche Problem zweimal auftritt, und die Anzahl der erforderlichen menschlichen Eingriffe minimiert werden.
A modern CDN gives you huge improvements in caching, SEO, performance, conversions, & more.
Bei vollständiger Automatisierung liegen die Kosten für die Durchführung von Maßnahmen praktisch bei 0, sodass häufige Mikrooptimierungen bei kleinen Problemen möglich sind. Die zusätzliche Präzision und Reaktionsfähigkeit, die die Vollautomatisierung bietet, ermöglicht sichere Verbindungen mit höherer Auslastung und bei Bedarf ein schnelles Routing von Traffic.
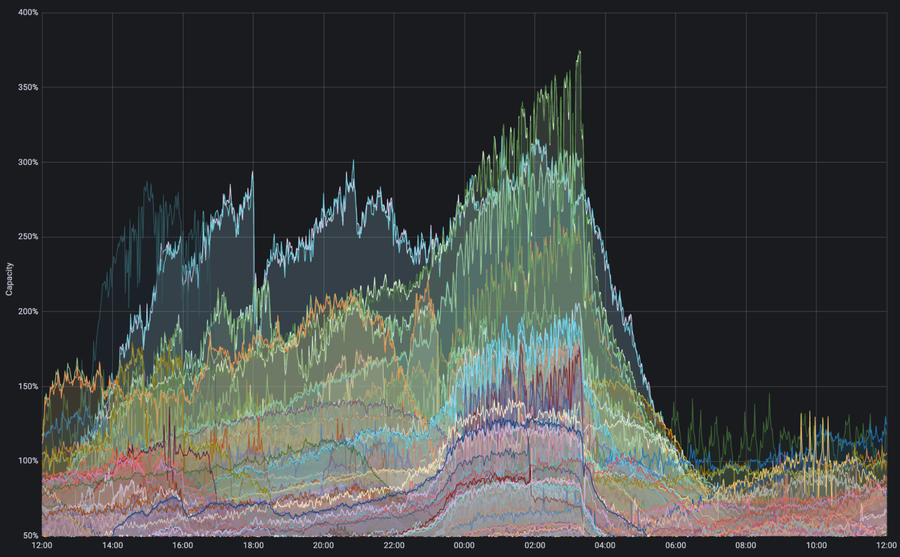
Abbildung – Die Traffic-Nachfrage auf der Egress-Schnittstelle übersteigt die Kapazität. Mehrere Schnittstellen waren während des Super Bowl von einer Nachfrage betroffen, die die verfügbare physische Kapazität um das Dreifache überstieg. Dies löste eine automatische technische Umgehung der Traffic-Steuerung aus, wodurch das Netzwerk auch weiterhin in der Lage war, Inhalte effizient und ohne negative Folgen für das Netzwerk auszuliefern.
Die obige Grafik zeigt ein Beispiel für einen Fall, in dem Autopilot ein Traffic-Volumen feststellte, das die verfügbare Kapazität der physischen Verbindung überstieg – während des Super Bowl in einigen Fällen sogar um das Dreifache. Ohne Autopilot hätten die Nachfragespitzen zu einer Überlastung der Verbindungen geführt, sodass ein umfangreiches menschliches Eingreifen erforderlich gewesen wäre, um Ausfälle zu verhindern. Dies hätte allerdings zu der Notwendigkeit geführt, alle nachgelagerten Auswirkungen dieses menschlichen Eingreifens zu managen, damit das Netzwerk wieder mit höchster Effizienz arbeiten würde. Dank Autopilot leitete das Netzwerk den Traffic automatisch auf sekundäre Pfade um. So konnte die zusätzliche Nachfrage ohne Performance-Einbußen bewältigt werden.
In diesem Blogpost möchten wir Ihnen genauere Einblicke in die Systeme bieten, die wir entwickelt haben, um ein hohes Traffic-Aufkommen ohne menschliches Eingreifen zu bewältigen.
Technische Hintergründe
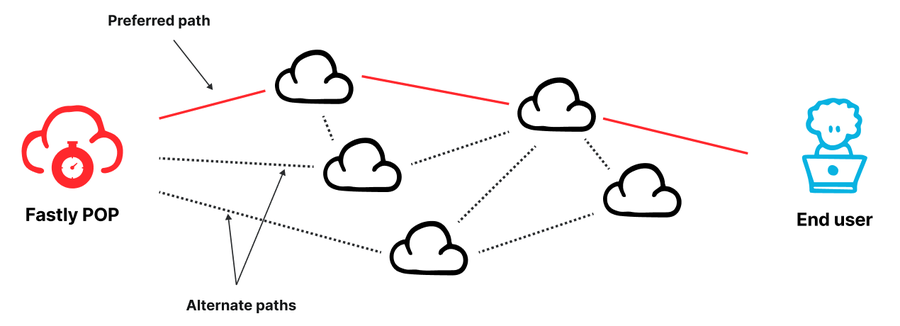
Abbildung – Unsere Fastly POPs sind über mehrere Peering-Netzwerke und Transit-Anbieter mit dem Internet verbunden.
Fastly betreibt ein weltweit verteiltes Netzwerk an Points of Presence</u> (POPs). Jeder POP ist aus Kapazitäts- und Zuverlässigkeitsgründen über verschiedene Netzwerke mit dem Internet verbunden. Dabei handelt es sich entweder um Peers oder Transit-Anbieter. Bei mehreren verfügbaren Routing-Optionen besteht die Herausforderung darin, den besten verfügbaren Pfad zu bestimmen. Wir müssen sicherstellen, dass wir die (zu einem bestimmten Zeitpunkt) leistungsfähigste Verbindung wählen und den Traffic rasch von Pfaden wegleiten, bei denen es zu Ausfällen oder Engpässen kommt.
Netzwerkanbieter verwenden ein Protokoll namens Border Gateway Protocol (BGP)</u>, um Informationen über die Erreichbarkeit von Internetzielen auszutauschen. Fastly erhält BGP-Updates von benachbarten Netzwerken und erfährt, welches Netzwerk für die Auslieferung von Daten an ein bestimmtes Ziel verwendet werden kann. Beim BGP gibt es allerdings einige Einschränkungen. Zunächst einmal ist es nicht kapazitäts- oder performanceorientiert. Es kann lediglich Auskunft darüber geben, ob ein Internetziel erreicht werden kann oder nicht, nicht aber, ob genügend Kapazität vorhanden ist, um die gewünschte Menge an Traffic zu übertragen, oder wie hoch der Durchsatz oder die Latenz für diese Übertragung wäre. Zweitens reagiert das BGP nur langsam auf Remote-Ausfälle. Bei einem Ausfall auf einem Remote-Pfad dauert es in der Regel mehrere Minuten, bis die Aktualisierungen übertragen werden. In dieser Zeit können Black Holes und Schleifen entstehen.
Diese Probleme zu lösen, ohne neue Probleme zu schaffen, ist eine Herausforderung, vor allem, wenn es sich um ein Traffic-Volumen von mehreren Dutzend Terabit pro Sekunde (Tbit/s) handelt. Auch wenn es wünschenswert ist, Ausfälle schnell zu umgehen, müssen wir auch bei diesen Prozessen vorsichtig sein. Denn wenn wir ein großes Traffic-Volumen fälschlicherweise umleiten, kann dies dazu führen, dass der Traffic von einem gut funktionierenden auf einen weniger gut funktionierenden Pfad umgeleitet wird und es zu Engpässen in nachgelagerten Systemen kommt. Diese können wiederum das Nutzererlebnis beeinträchtigen. Mit anderen Worten: Wenn Entscheidungen nicht sorgfältig getroffen werden, können einige Maßnahmen, die zur Verringerung des zu hohen Traffic-Aufkommens ergriffen werden, die Überlastung weiter verstärken – manchmal sogar erheblich.
Die Lösung von Fastly besteht im Einsatz von zwei verschiedenen Kontrollsystemen, die unterschiedlich getaktet sind, um sicherzustellen, dass wir Ausfälle schnell umgehen und Traffic so effizient wie möglich umleiten können.
Das erste System, das auf zehn Millisekunden getaktet ist (um mehrere Round Trips zu ermöglichen), überwacht die Performance der einzelnen TCP-Verbindungen zwischen Fastly und den Endnutzern. Wenn eine Verbindung selbst nach mehreren Round-Trip-Versuchen nicht durchgeht, wird diese Verbindung auf alternative Pfade umgeleitet, bis sie das wieder tut. Dieses System bildet die Grundlage für unser Precision Path</u> Produkt zum Schutz der Verbindungen zwischen Fastly und den Endnutzern. Es sorgt dafür, dass wir schnell auf Netzwerkausfälle reagieren können, indem wir einzelne Traffic Flows, bei denen Probleme auftreten, innerhalb eines kürzeren Zeitfensters gezielt umleiten.
Das zweite System, das wir intern als Autopilot bezeichnen, besitzt eine längere Taktung. Es berechnet minütlich die Restkapazität unserer Verbindungen und die Performance der Netzwerkpfade, die über Messungen im Netzwerk erfasst werden. Mithilfe dieser Informationen sorgt es dafür, dass der entsprechende Traffic auf verschiedene Verbindungen verteilt wird, um die Performance zu optimieren und zu verhindern, dass es zu Überlastungen kommt. Dieses System besitzt eine langsamere Reaktionszeit, trifft aber fundiertere Entscheidungen anhand von hochauflösenden Netzwerk-Telemetriedaten, die über einen Zeitraum von mehreren Minuten erfasst werden. Autopilot sorgt dafür, dass große Traffic-Volumina sicher und ohne nachteilige Auswirkungen übertragen werden können.
Durch das Zusammenspiel dieser beiden Systeme lassen sich problematische Traffic Flows schnell auf funktionierende Pfade umleiten. Außerdem können wir unsere gesamte Routing-Konfiguration regelmäßig anpassen und verfügen über genügend Daten, um sichere Entscheidungen zu treffen. Unsere Systeme sind rund um die Uhr im Einsatz, spielten aber während des Super Bowl eine besonders wichtige Rolle, als sie 300 Gbit/s bzw. 9 Tbit/s an Traffic umleiteten, der andernfalls über fehlerhafte, überlastete oder nicht ausreichend performante Pfade ausgeliefert worden wäre.
Dieser Ansatz für die Steuerung von Egress-Traffic, bei dem unterschiedlich getaktete Systeme zum Einsatz kommen, um ein Gleichgewicht zwischen Reaktionsfähigkeit, Genauigkeit und der Sicherheit von Routing-Entscheidungen herzustellen, ist unseres Wissens nach bislang einzigartig in unserer Branche. Im weiteren Verlauf dieses Blogposts gehen wir auf die Funktionsweise beider Systeme ein. Zunächst aber ein kleiner Exkurs, um zu erklären, wie wir den Traffic anhand eines weiteren ungewöhnlichen Ansatzes, bei dem wir ebenfalls Branchenführer sind, von unseren POPs wegleiten.
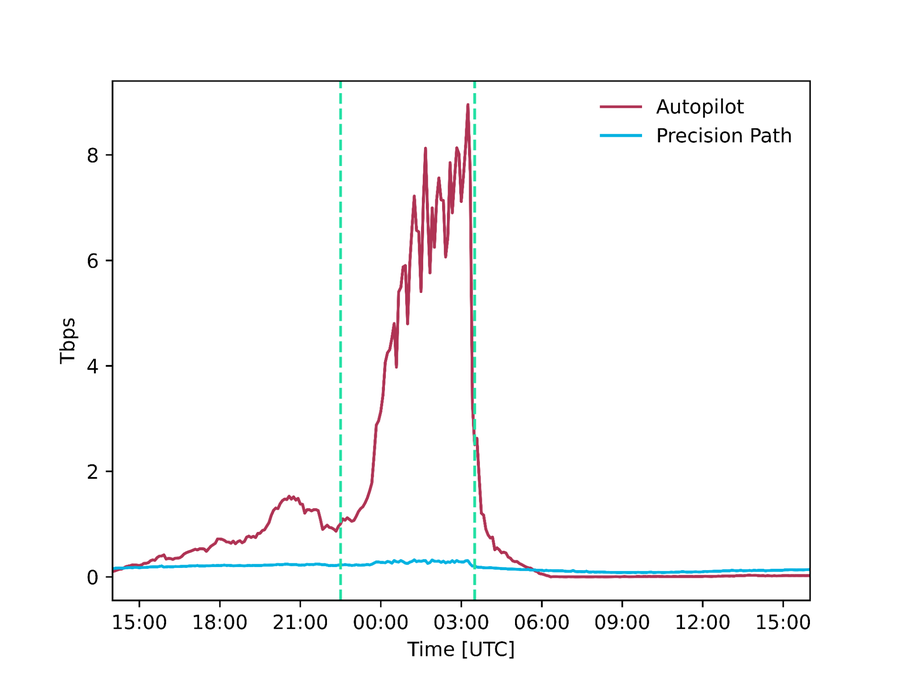

Abbildung – Mithilfe von Precision Path bzw. Autopilot ausgeliefertes Traffic-Volumen während des Super Bowl (absolut und als Prozentsatz des gesamten Traffics)
Fastly Netzwerkarchitektur
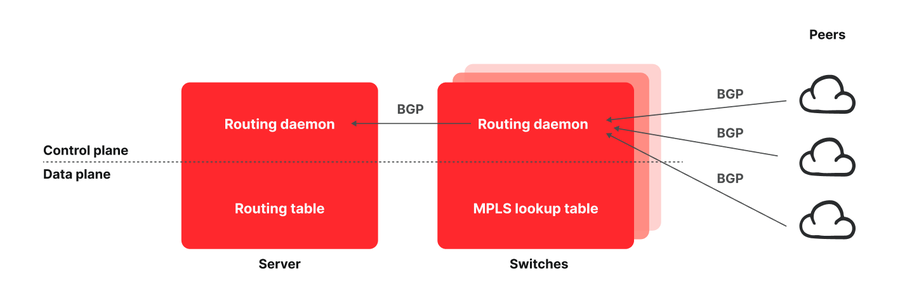
Abbildung – Die Architektur der Fastly POPs
Ein typischer Fastly POP besteht aus verschiedenen Servern, die über eine Reihe von Netzwerk-Switches mit allen Peer-Netzwerken und Transit-Anbietern verbunden sind. Üblicherweise besteht ein Edge Cloud POP aus Netzwerk-Routern, die über einen ausreichend großen Speicher verfügen, um die gesamte Internet-Routing-Tabelle zu speichern. Bei der Routing-Architektur von Fastly hingegen werden alle Verbindungen an die Endhosts weitergeleitet</u>, um die Kosten zu senken. Wir haben aber auch schnell erkannt, dass diese Architektur sehr leistungsstarke Funktionen ermöglicht. Endpoints, die Einsicht in die Performance von Traffic Flows haben, können nun auch deren Routing beeinflussen. Dies ist einer der Hauptgründe, warum Fastly in Sachen Netzwerkfunktionen, Programmierbarkeit, Flexibilität und Nutzerfreundlichkeit weiterhin die Nase vorn hat.
So funktioniert unsere Routing-Architektur: Sowohl auf den Switches als auch auf den Servern laufen Instanzen des BIRD Internet Routing Daemon, auf den einige eigens von uns entwickelte Patches angewendet wurden. Die Daemons, die auf den Switches laufen, erfassen sämtliche bekannte Verbindungen von unseren Transits und Peers. Anstatt diese Verbindungen jedoch in die Routing-Tabelle der Switches aufzunehmen, werden sie an die Server weitergegeben, die sie anschließend in ihre Routing-Tabellen aufnehmen. Damit die Server den Traffic dann an den gewünschten Transit oder Peer weiterleiten können, verwenden wir das Multiprotocol Label Switching (MPLS)-Protokoll. Wir versehen jeden Switch mit einem Eintrag in der MPLS-Lookup-Tabelle (Label Forwarding Information Base [LFIB]) für jede Egress-Schnittstelle und kennzeichnen alle BGP-Pfadankündigungen, die an die Server weitergegeben werden, mit einer Codierung für das MPLS-Label, das für die Weiterleitung des Traffics verwendet wird. Die Server nutzen diese Informationen, um ihre Routing-Tabelle zu befüllen, und verwenden das entsprechende Label, um Traffic vom POP wegzuleiten. Ausführlichere Informationen zu diesem Thema finden Sie in einem wissenschaftlichen Artikel</u>, den wir auf der USENIX NSDI 2021 veröffentlicht haben.
Schnelle Umleitung bei Ausfällen mit Precision Path
Unser Ansatz, bei dem wir alle Verbindungen auf die Server verlagern und den Endpoints die Möglichkeit geben, Umleitungen anhand von Metriken auf dem Transport- und Anwendungs-Layer vorzunehmen, ermöglichte die Umsetzung von Precision Path</u>. Um einzelne Traffic Flows bei Pfadausfällen und schweren Überlastungen umleiten zu können, ist Precision Path auf eine Genauigkeit im Bereich von 10 Millisekunden getaktet. Precision Path eignet sich gut, um Traffic schnell von Ausfällen wegzuleiten und Engpässe zu umgehen, ist aber nicht in der Lage, proaktiv den besten Pfad zu wählen. Es fehlt am Gesamtüberblick und der zur Auswahl eines optimierten neuen Pfads nötigen Transparenz. Genaueres über die Technologie hinter Precision Path erfahren Sie in diesem Blogpost</u> und in diesem wissenschaftlichen Artikel</u>. Hier aber eine kurze Erläuterung.
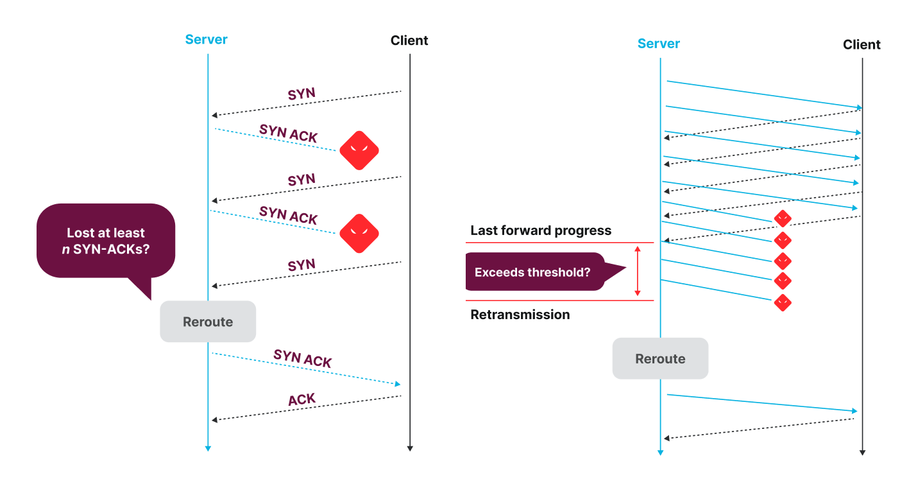
Abbildung – Precision Path Entscheidungslogik für die Umleitung von Verbindungen, die gerade aufgebaut werden (links), und für bereits bestehende Verbindungen (rechts)
Bei diesem System handelt es sich um einen Linux Kernel-Patch, der den Systemstatus der einzelnen TCP-Verbindungen überwacht. Wenn eine Verbindung selbst nach mehreren Round-Trip-Versuchen nicht durchgeht (was auf einen möglichen Pfadausfall hinweist), wird sie auf einen zufällig ausgewählten alternativen Pfad umgeleitet, bis sie das wieder tut. Unsere hostbasierte Routing-Architektur, bei der die Server die Pfade für den Egress-Traffic anhand von MPLS-Labels auswählen, ermöglicht es, für jeden Traffic Flow eigene Umleitungsentscheidungen zu treffen. End Hosts können demnach jeden Traffic Flow schnell und gezielt umleiten, da sie sowohl Einsicht in die Performance von Verbindungen als auch die Möglichkeit haben, einen anderen Netzwerkpfad zu wählen. Dieses System ist bemerkenswert effektiv bei der schnellen Behebung kurzzeitiger Ausfälle und Performance-Einbrüche, die von den Netzwerkbetreibern oder anderen telemetriegesteuerten Traffic-Engineering-Methoden nur sehr langsam behoben werden können. Der Nachteil ist, dass dieses System lediglich auf schwerwiegende Performance-Einbußen reagiert, die bereits auf Datenebene erkennbar sind, und den Traffic auf zufällig ausgewählte alternative Pfade umleitet, die zwar funktionieren, aber möglicherweise nicht die besten und optimalsten Pfade sind.
Fundiertere, langfristige Routing-Entscheidungen mit Autopilot
Autopilot kompensiert die Einschränkungen von Precision Path durch eine nicht ganz so zügige, dafür aber fundiertere Entscheidungskompetenz bezüglich der am besten geeigneten oder am wenigsten überlasteten Pfade. Anstatt (wie Precision Path) Traffic lediglich von einem ausgefallenen Pfad wegzuleiten, werden größere Mengen an Traffic *in Richtung* besserer Netzwerkabschnitte weitergeleitet. Wir haben Autopilot bisher noch nicht vorgestellt und freuen uns, ihn in diesem Blogpost ausführlicher zu beschreiben.
Autopilot ist ein Controller, der Netzwerk-Telemetriesignale zu Aspekten wie Paket-Stichproben, Verbindungskapazität, Round-Trip-Zeit (Round Trip Time, RTT), Messungen von Paketverlusten und Verfügbarkeit von Pfaden für ein bestimmtes Ziel von unserem Netzwerk empfängt. Autopilot sammelt minütlich Netzwerk-Telemetriedaten, nutzt diese, um das Traffic-Aufkommen pro Schnittstelle ohne Override-Pfade zu prognostizieren, und trifft Entscheidungen, um den Traffic auf alternative Pfade umzuleiten, wenn eine oder mehrere Verbindungen kurz vor ihrer Kapazitätsgrenze stehen oder wenn der derzeit genutzte Pfad für ein bestimmtes Ziel nicht dieselbe Performance bieten würde.
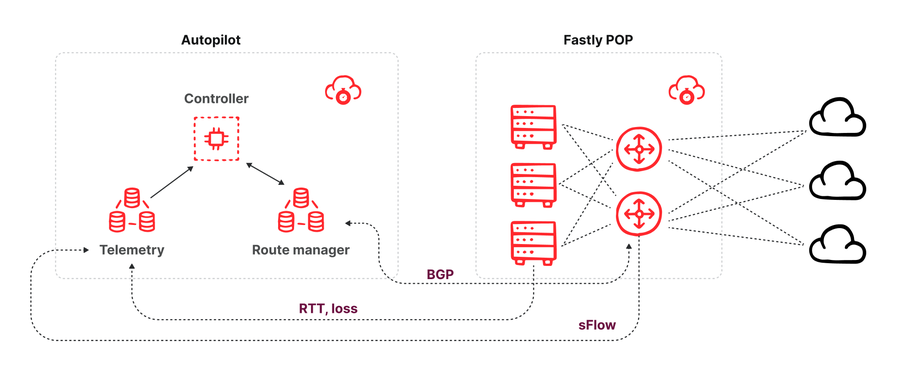
Abbildung – Diagramm der Autopilot Architektur
Die Architektur von Autopilot besteht aus drei Komponenten (siehe oben):
Einem Routing-Manager, der mit jedem Switch innerhalb eines POP eine Peer-Verbindung eingeht und alle Routing-Updates empfängt, die der Switch von seinen benachbarten Netzwerken über eine BGP-Peering-Sitzung erhalten hat. Der Routing-Manager bietet eine API, über die Verbraucher erfahren können, welche Pfade für ein bestimmtes Ziel-Präfix verfügbar sind. Der Routing-Manager bietet auch die Möglichkeit, Pfadänderungen über seine API vorzunehmen. Dies erfolgt über die Ankündigung einer BGP-Pfadaktualisierung an den Switch mit einem höheren Wert für die lokale Präferenz als Pfade, die von anderen Peers und Transit-Anbietern offengelegt wurden. Diese Ankündigung eines neuen Pfades sorgt dafür, dass der Bester-Pfad-Algorithmus von BGP bei gleicher Gewichtung verschiedener Pfade unseren Pfad auswählt, ihn in die Routing-Tabellen der Server einfügt und ihn nutzt, um Traffic zu routen.
Einem Telemetrie-Collector, der sFlow Paket-Stichproben von allen Switches eines POP erhält und eine Schätzung des Traffic-Volumens nach Ziel-Schnittstelle und Ziel-Präfix sowie die Messung von Latenzzeiten und Paketverlusten für den gesamten Traffic zwischen Fastlys POPs über alle verfügbaren Anbieter ermöglicht.
Einem Controller, der (minütlich) die neuesten Telemetriedaten (Traffic-Aufkommen und Performance) sowie alle verfügbaren Pfade für die Präfixe, die derzeit vom POP bedient werden, empfängt und anschließend berechnet, ob eine BGP-Pfadüberbrückung injiziert werden soll, um den Traffic über alternative Pfade zu leiten.
Das Zusammenspiel von Precision Path und Autopilot
Eine der Herausforderungen bei mehreren Kontrollsystemen, die mit denselben Inputs und Outputs arbeiten, besteht darin, dass sie die Wahl der insgesamt besten Optionen gemeinsam treffen müssen, anstatt miteinander zu konkurrieren. Der Versuch, die beste Option aus dem eingeschränkten Blickwinkel jedes einzelnen Optimierungsprozesses heraus auszuwählen, könnte sogar zu zusätzlichen Störungen führen und mehr Schaden anrichten als Nutzen bringen. Soweit uns bekannt ist, sind wir die ersten in der Branche, die unterschiedlich getaktete Systeme beim Traffic Engineering einsetzen.
Die größte Herausforderung besteht für uns darin, dass ein Traffic Flow nicht mehr auf BGP-Pfadänderungen reagiert, sobald er von Precision Path umgeleitet wird, auch nicht auf solche, die von Autopilot ausgelöst werden. Aus diesem Grund muss Autopilot bei seinen Entscheidungen den Umfang des derzeit von Precision Path kontrollierten Traffics berücksichtigen. Wir haben dieses Problem auf zweierlei Arten gelöst: Zunächst haben wir Precision Path so angepasst, dass so wenig Traffic wie möglich umgeleitet wird, und zweitens so, dass Autopilot diesen Traffic beobachten kann, um ihn in seine Entscheidungen einzubeziehen.
Beim ersten Einsatz von Precision Path haben wir eine Feinabstimmung der Konfiguration vorgenommen, um Fehlalarme zu minimieren. Fehlalarme würden dazu führen, dass der Traffic von einem optimalen Pfad, auf dem vorübergehend ein kleines Problem auftritt, auf längere Pfade mit schlechterer Performance umgeleitet würde, was wiederum zu einer stärkeren Beeinträchtigung der Performance der betroffenen TCP-Verbindungen führen könnte. Ausführlichere Informationen zu unseren Tuning-Experimenten finden Sie in diesem Artikel</u>. Das alleine reicht aber nicht aus, denn selbst wenn wir zum Zeitpunkt der Umleitung einer Verbindung die richtige Entscheidung treffen, kann es sein, dass sich der ursprünglich bevorzugte Pfad einige Minuten nach der Umleitung wieder erholt. Das ist typischerweise der Fall, wenn BGP den Ausfall bemerkt und keinen Traffic mehr über den ausgefallenen Pfad weiterleitet. Um sicherzustellen, dass Verbindungen wieder auf den bevorzugten Pfad umgeleitet werden, sobald der Ausfall behoben ist, prüft Precision Path den ursprünglichen Pfad alle fünf Minuten nach der ersten Umleitung. Wenn der bevorzugte Pfad wieder verfügbar ist, wird die Verbindung zurück auf diesen Pfad geleitet. Dies ist besonders hilfreich für langlebige Verbindungen wie beim Videostreaming, die sonst während ihrer gesamten Lebensdauer auf einem Backup-Pfad festsitzen würden. Außerdem wird so der Anteil des Traffics minimiert, der nicht mit Autopilot gesteuert werden kann, und gleichzeitig der Handlungsspielraum maximiert.
Schwieriger ist es hingegen, den Umfang des von Precision Path gerouteten Traffics für Autopilot sichtbar zu machen. Wie bereits erwähnt, erfährt Autopilot das Traffic-Volumen, das über jede Schnittstelle gesendet wird, aus sFlow Paket-Stichproben, die von den Switches gesendet werden. Unter anderem verraten diese Stichproben, über welche Schnittstelle die Pakete gesendet wurden und welches MPLS-Label sie trugen. Sie enthalten allerdings keine Informationen darüber, wie dieses MPLS-Label angewendet wurde. Unsere Lösung bestand darin, einen neuen Satz alternativer MPLS-Labels für unsere Egress Ports zu erstellen und sie ausschließlich für Precision Path zu verwenden. Auf diese Weise können wir durch Nachschlagen eines MPLS-Labels in unserer IP-Adressverwaltungsdatenbank schnell herausfinden, ob dieses Paket gemäß BGP-Pfadauswahl oder gemäß Precision Path Rerouting weitergeleitet wurde. Wir geben diese Informationen an den Autopilot Controller weiter, der Precision Path als „nicht steuerbar“ – also als Traffic, der nicht von seinem aktuellen Pfad abweicht – behandelt, selbst wenn der bevorzugte Pfad für sein Zielpräfix aktualisiert wird.
Sichere Automatisierung
Unsere Kunden vertrauen uns als Vermittler zwischen ihren Services und ihren Nutzern, und wir nehmen diese Verantwortung sehr ernst. Während die Automatisierung des Netzwerkbetriebs unseren Kunden ein nahtloses Erlebnis ermöglicht, möchten wir auch die Zuverlässigkeit unseres Netzwerks gewährleisten. Bei der Entwicklung aller unserer Automatisierungssysteme stehen Sicherheit und Nutzerfreundlichkeit im Mittelpunkt. Unsere Systeme sind so aufgebaut, dass es bei Problemen zu keinem Totalausfall kommt und dass die Netzwerkbetreiber jederzeit eingreifen und das Verhalten der Systeme durch Anpassung der Routing-Regeln umgehen können. Letzteres ist besonders wichtig, da es den Betreibern ermöglicht, Tools und Techniken anzuwenden, mit denen sie aus Umgebungen ohne Automatisierung vertraut sind. Die Minimierung des kognitiven Aufwands durch erfolgreiche Automatisierung immer größerer Abläufe ist besonders wichtig, um Probleme schneller lösen zu können, wenn Sie unter Zeitdruck arbeiten. Hier einige Beispiele, wie wir dafür gesorgt haben, dass unsere Automatisierung sicher und nutzerfreundlich ist:
Von Netzwerkbetreibern genutzte Standard-Tools : Sowohl Precision Path als auch Autopilot lassen sich mit den Standard-Tools und -methoden der Netzwerkbetreiber steuern.
Precision Path kann für einzelne Pfade deaktiviert werden, indem eine bestimmte BGP-Community in eine einzelne Pfadankündigung injiziert wird. Dies ist eine sehr häufige Aufgabe, die Netzwerktechniker aus verschiedenen Gründen durchführen. Precision Path kann auch für eine einzelne TCP-Sitzung deaktiviert werden, indem eine bestimmte Weiterleitungsmarkierung auf dem Socket gesetzt wird. Dadurch ist es möglich, aktive Messungen durchzuführen, ohne dass Precision Path aktiviert wird und die Ergebnisse verfälscht.
Die Pfadauswahl von Autopilot basiert auf dem Bester-Pfad-Algorithmus von BGP. Es wird also versucht, den Traffic auf den zweitbesten Pfad gemäß dem Bester-Pfad-Algorithmus von BGP umzuleiten. Folglich können Netzwerkbetreiber Einfluss darauf nehmen, auf welchen Pfad Autopilot ausweicht, indem sie die BGP-Richtlinien ändern, zum Beispiel durch Änderung der „MED“- oder „local pref“-Werte.
Außerdem sammeln unsere Netzwerktelemetriesysteme Daten darüber, ob die Verbindungen über die von Precision Path oder Autopilot ausgewählten Pfade geroutet wurden, wodurch wir Geschehnisse nachvollziehen können.
Auditing der Datenqualität: Wir prüfen die Qualität der Daten, die in unsere Automatisierung einfließen, und haben unsere Systeme so konfiguriert, dass keine Änderungen vorgenommen werden, wenn die eingehenden Daten nicht stimmig sind. Bei Autopilot vergleichen wir zum Beispiel die Schätzung des Egress Flows anhand von Paket-Stichproben mit einer Schätzung anhand von Schnittstellenzählern. Liegt die Abweichung über einem bestimmten Schwellenwert, bedeutet dies, dass mindestens eine der Schätzungen falsch sein muss, und wir nehmen keine Änderungen vor. Im nachfolgenden Diagramm sehen Sie die Differenz zwischen diesen beiden Schätzungen an einem nordamerikanischen POP während des Super Bowl.
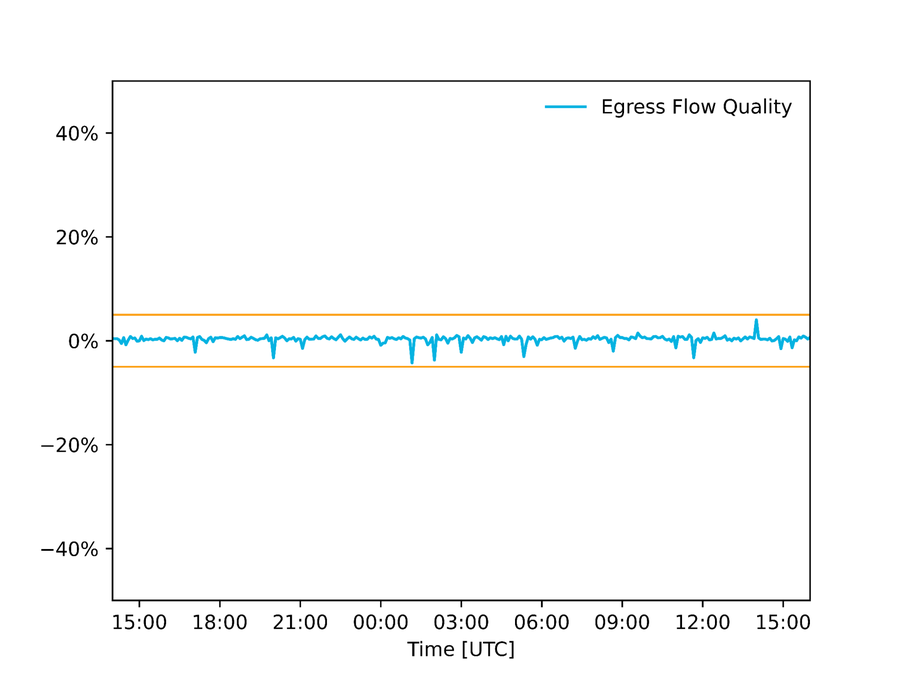
Abbildung – Differenz zwischen Schätzungen zur Verbindungsnutzung über Schnittstellenzähler bzw. Paket-Stichproben. Die akzeptable Fehlermarge liegt bei einem Schwellenwert von +/- 5 %.
Was-wäre-wenn-Analyse und Kontrollgruppen: Neben der Überwachung der Eingangsdaten prüfen wir auch die von den Systemen getroffenen Entscheidungen und greifen bei Fehlverhalten korrigierend ein. Precision Path nutzt Behandlungs- und Kontrollgruppen. Wir wählen zufällig einen kleinen Prozentsatz von Verbindungen aus, die zu einer Kontrollgruppe gehören, bei der Precision Path deaktiviert ist. Anschließend überwachen wir deren Performance im Vergleich zu Verbindungen, bei denen Precision Path aktiviert ist. Wenn die Verbindungen aus der Kontrollgruppe besser funktionieren als die Verbindungen aus der Behandlungsgruppe, wird unser Engineering Team benachrichtigt, sich um die Untersuchung und Behebung des Problems zu kümmern. Analog dazu lassen wir Autopilot vor der Implementierung einer Konfigurationsänderung an unserem Algorithmus im „Shadow“-Modus laufen, in dem der neue Algorithmus zwar Entscheidungen trifft, diese aber nicht auf das Netzwerk angewendet werden. Der neue Algorithmus wird nur dann bereitgestellt, wenn er mindestens so gut abschneidet wie der derzeitige.
Fail-static: Wenn eine Systemkomponente ausfällt, wird sie nicht in den „fail close“- oder „fail open“-Modus, sondern in den „fail static“-Modus versetzt. Die letzte bekannte funktionierende Konfiguration des Netzwerks wird also beibehalten und unser Engineering Team wird alarmiert, um das Problem zu untersuchen.
Fazit
Dieser Blogpost ist eine Zusammenfassung davon, wie Fastly das Routing von Egress-Traffic automatisiert, um sicherzustellen, dass der Traffic unserer Kunden zuverlässig zu ihren Endnutzern gelangt. Wir arbeiten weiter an Innovationen und verschieben die Grenzen des Machbaren, während wir uns gleichzeitig auf unübertroffene Performance konzentrieren. Wenn auch Sie Ihren Traffic lieber von Experten verwalten lassen möchten, die nicht nur vom Fach sind, sondern auch Engagement zeigen, dann setzen Sie sich am besten gleich mit uns in Verbindung</u>. Und wenn Sie sich vorstellen können, selbst mit an solchen Innovation zu tüfteln, finden Sie hier unsere Stellenangebote: /about/careers/current-openings</u>.
Open-Source-Software
Die in unser Netzwerk integrierte Automatisierung basiert auf Open-Source-Technologie. Open Source gehört bei Fastly zur DNA. Unsere Lösungen basieren auf Open Source und wir stellen den Code für unsere eigenen Projekte nach Möglichkeit ebenfalls der Open-Source-Community zur Verfügung. Außerdem haben wir Fast Forward</u> kostenlose Services im Wert von 50 Millionen US-Dollar zur Verfügung gestellt, um Projekte zu unterstützen, die das Internet und unsere Produkte antreiben. Für die Automatisierung unseres großen Netzwerks haben wir folgende Tools genutzt:
Kafka</u> – eine verteilte Plattform für das Streaming von Ereignissen
pmacct</u> – einen sFlow Collector
goBGP</u> – BGP Routing-Daemon-Bibliothek zur Entwicklung der Route Collector/Injector-Funktion von Autopilot
BIRD</u> – BGP Routing Daemon, der auf unseren Switches und Servern läuft
Es ist uns wichtig, einen Beitrag zur Community zu leisten. Deshalb haben wir Verbesserungen und Fehlerkorrekturen, die wir im Rahmen unserer Arbeit vorgenommen haben, an die Maintainer weitergeleitet. Wir möchten uns abschließend von ganzem Herzen bei denjenigen bedanken, die diese Projekte in die Tat umgesetzt haben. Wenn Sie ein Open-Source-Maintainer oder -Beitragender sind und sich für eine Teilnahme an Fast Forward interessieren, kontaktieren Sie uns hier</u>.