
Network Error Logging (NEL) kann wertvolle Einblicke in Netzwerkprobleme liefern, die Ihre Nutzer beim Zugriff auf ihre Website haben könnten. Da es sich um eine W3C-Spezifikation handelt und von einigen Browsern unterstützt wird, hat es auch ein großes Potenzial, bei der Fehlererkennung und -meldung zu helfen.Wir haben mit Fastly Insights experimentiert und festgestellt, dass die Verarbeitung von NEL-Berichten ein toller Anwendungsfall für Compute, die neue Serverless-Compute-Umgebung von Fastly, ist.Mit Compute können wir die Daten effizient parsen und anreichern, dann das JSON neu serialisieren, bevor wir den daraus resultierenden Bericht an einen Logging Endpoint eines Drittanbieters, wie z. B. BigQuery, senden. Und all das ohne die komplexeren und fehleranfälligeren Verarbeitungspipelines, die wir vorher zur Lösung dieses Problems verwendet haben.
Wir sprechen schon seit geraumer Zeit über Compute – wie es das Hochladen und Bereitstellen komplexer Logik auf der Edge im Rahmen des sichersten, leistungsfähigsten und skalierbarsten Ansatzes für serverloses Computing ermöglicht –, aber hier erzählen wir zum ersten Mal, wie wir C@E zur Lösung eines internen Problems eingesetzt haben.In diesem Beitrag erläutern wir also, wie wir eine NEL-Reporting-Pipeline aufgebaut haben, wo es Optimierungspotenzial gab und wie Compute unter gleichzeitiger Verbesserung von Performance und Sicherheit zur Lösung dieser Probleme beigetragen hat.
Eine typische Reporting-Pipeline
Grundsätzlich gibt es nur wenige Anforderungen an die Erstellung eines NEL Reporting Endpoint:
OPTIONS-Anfragen mit „204“ (Kein Inhalt) und den entsprechenden CORS-Headern beantworten, um die Sicherheitsanforderungen vor der Übertragung zu erfüllen
POST-Anfragen, die einen Bericht enthalten, mit einer HTTP-Antwort „204 No Content“ beantworten
Berichte sammeln, sie bei Bedarf mit Metadaten versehen und in einer Analysepipeline protokollieren
Die protokollierten Daten in ein für die Analyse geeignetes Format konvertieren und in einer Datenbank speichern
NEL-Berichte werden von Browsern als POST-Body-Payloads im JSON-Format übermittelt.Auch wenn sie in ihrer derzeitigen Form analysiert werden können, will Fastly noch viel mehr über die Anfrage erfahren. Für uns ist es nützlich, diese auf der Edge verfügbaren Metadaten zu erfassen, um den Berichten einen gewissen Kontext zu geben.Für unsere Zwecke wollen wir jedem Bericht Geo-IP-Informationen und einen Zeitstempel hinzufügen, bevor wir ihn mit den Echtzeit-Log-Funktionen von Fastly protokollieren.
Um die Sache noch interessanter zu machen, können Browser mehrere NEL-Fehlermeldungen stapeln (und unseren Beobachtungen zufolge tun sie das auch) und sie alle auf einmal in einer einzigen POST-Anfrage senden – höchstwahrscheinlich, um auf diese Weise ihre Ressourcen effizienter zu nutzen.Das bedeutet, dass der POST-Body, den wir für jede Anfrage sehen, einen oder mehrere Berichte enthalten kann, die als Array von JSON-Berichtsobjekten gesendet werden.
Da das Parsen und die Konstruktion komplexer JSON-Objekte auf der Edge keine leichte Sache ist, haben wir uns für den Ansatz entschieden, ein neues JSON-Objekt zu konstruieren, das als Umschlag fungiert, die Metadaten als individuelle Eigenschaften des Objekts anzugeben, das Berichts-Array als weitere Eigenschaft des Objekts hinzuzufügen und dann das Umschlag-Objekt im Zeilenumbruch getrennten JSON-Format an einen Speicherendpunkt (in diesem Fall Google Cloud Storage) zu übertragen.
Zu diesem Zeitpunkt sind die unbearbeiteten Logs nicht unbedingt für die Analyse geeignet, da jede Zeile immer noch viele Berichte enthalten könnte. Wir würden es vorziehen, wenn jeder Bericht in der Datenbank eine einzelne Zeile in Anspruch nehmen würde.Um dieses Problem zu lösen, haben wir mithilfe von Google Cloud Funktionen ein gängiges (ETL-)Pipelinemuster (Extrahieren, Transformieren, Laden) eingesetzt, um die Protokolle verarbeiten, die einzelnen Berichte segmentieren, sie mit den Metadaten zusammenführen und dann jeweils als separate Zeile in BigQuery einfügen zu können.Dieses Diagramm zeigt den allgemeinen Ablauf von Anfang bis Ende:

Was wir entwickelt haben, war funktional und hat uns im Betrieb gute Dienste geleistet. Aber wir haben schnell gemerkt, dass es noch Raum für Verbesserungen gab: Wenn wir die Berichte auf der Edge parsen, einzelne JSON-Objekte pro Bericht erstellen (und jedem die zusätzlichen von Fastly bereitgestellten Metadaten hinzufügen) und dann das Ergebnis direkt von der Edge aus in BigQuery protokollieren könnten, würden wir die Anzahl der sich bewegenden Teile im Prozess reduzieren und eine effizientere Sammel-/Log-/Analyse-Pipeline schaffen, die sich auch in Zukunft leicht erweitern lassen würde.
Dies ist genau die Art von Umsetzung, die Compute ermöglicht, und dies war die Hauptmotivation für die Migration der aktuellen Pipeline auf die neue Plattform.
NEL-Berichtserfassung mit Compute
Compute ist sprachunabhängig und ermöglicht es uns, in vertrauten Programmiersprachen – wie Rust – auf der Edge zu programmieren. Rust unterstützt Dinge wie das Parsen von JSON in stark typisierte Datenstrukturen sowie leistungsstarkes Pattern-Matching. Mit diesen Funktionen können wir einen speziell entwickelten Sammelendpunkt erstellen und bereitstellen, der die Berichte extrahiert, umwandelt und in BigQuery loggt, wodurch viele der Komponenten unserer vorherigen Ausführung überflüssig werden. Werfen wir einen Blick auf einen Teil der Kernlogik, um zu sehen, wie wir dies erreicht haben (Sie können sich die gesamte Anwendung auch auf GitHub ansehen):
Routing
Wie die meisten serverlosen Plattformen haben Compute-Programme einen Einstiegspunkt, der aus einer einzigen Funktion besteht: eine Anfrage empfangen und eine Antwort zurückschicken.Zunächst müssen wir also die Einstiegsfunktion unseres Programms definieren, die unsere HTTP-Routing-Logik enthalten wird.Zum Glück erlaubt uns die Syntax für Mustererkennung von Rust einen einfachen Abgleich mit der Struktur und den Werten von Typen wie den einer eingehenden Anfrage, sodass wir bestimmen können, dies zu tun, wenn die Anfrage ein POST ist, oder jenes, wenn nicht.
#[fastly::main]
fn main(req: Request<Body>) -> Result<Response<Body>, Error> {
// Pattern match on the request method and path.
match (req.method(), req.uri().path()) {
// If a CORS preflight OPTIONS request, return a 204 no content.
(&Method::OPTIONS, "/report") => generate_no_content_response(),
// If a POST request pass to the `handler_reports` request handler.
(&Method::POST, "/report") => handle_reports(req),
// For all other requests return a 404 not found.
_ => Ok(Response::builder()
.status(StatusCode::NOT_FOUND)
.body(Body::from("Not found"))?),
}
}Hier machen wir einen Abgleich mit der Methode und dem URL-Pfad der Anfrage.Wenn es sich um eine OPTIONS-Anfrage an den Berichtspfad handelt, geben wir sofort eine 204-Antwort zurück. Wenn es sich um eine POST-Anfrage an denselben Pfad handelt, übergeben wir sie an eine handle_reports-Funktion, andernfalls geben wir eine „404 Not Found“-Antwort zurück.
JSON-Parsing
Der Hauptzweck der CloudFunction in unserer bisherigen Pipeline bestand darin, das JSON zu analysieren, jeden Bericht zu extrahieren, die globalen Metadaten zu transkodieren und dann als einzelne Zeilen an die Datenbank zu senden.Eines der wichtigsten Merkmale von Compute ist, dass wir das reichhaltige und ausgereifte Ökosystem von Modulen nutzen können, um diese Probleme auf sichere und effiziente Weise zu lösen, wie z. B. das äußerst hilfreiche serde_json-Rust-Crate.
Mit Serde können wir den Traffic des Anfragekörpers lesen und als JSON in eine von uns vordefinierte, stark typisierte Rust-Datenstruktur parsen. Da es sich bei NEL um eine W3C-Spezifikation handelt, ist die POST-Payload ebenfalls eine vordefinierte Struktur, der alle User Agents entsprechen müssen. Dies hat den angenehmen Nebeneffekt, dass alle fehlerhaften oder böswilligen Berichte, die an unseren Endpunkt gesendet werden, von Serde verworfen werden, da sie nicht der Spezifikation entsprechen. Das bedeutet auch, dass wir keine Nachbearbeitung vornehmen müssen, um die Daten in BigQuery zu bereinigen, bevor wir sie verwenden. Typsicherheit FTW!
/// `Report` models a Network Error Log report.
#[derive(Serialize, Deserialize, Clone)]
pub struct Report {
pub user_agent: String,
pub url: String,
#[serde(rename = "type")]
pub report_type: String,
pub body: ReportBody,
pub age: i64,
}
// Parse the NEL reports from the request JSON body using serde_json.
// If successful, bind the reports to the `reports` variable, transform and log.
if let Ok(reports) = serde_json::from_reader::<Body, Vec<Report>>(body) {
// Processing logic...
}Transformation und Logging
Da wir jetzt Zugriff auf eine Liste strukturierter, vom Client gesendeter NEL-Berichte haben, können wir diese mit unseren Geo-IP-Metadaten anreichern, bevor wir sie schließlich in unserem BigQuery-Endpunkt loggen.Hier zeigt sich die wahre Stärke einer flexiblen Programmierumgebung auf der Edge.
Zunächst modellieren wir die Metadaten in Form einer ClientData-Struktur und implementieren ihre Konstruktormethode, die eine IP- und User-Agent-Zeichenfolge akzeptiert.Der Konstruktor ist für einige erwähnenswerte Dinge zuständig:
Zunächst kürzt er die IP-Adresse des Clients auf ein datenschutzfreundliches Präfix, da wir die vollständige IP-Adresse nicht in unserer Datenbank speichern müssen.
Dann ruft er die geo_lookup-Funktion aus dem importierten fastly::geo-Modul auf, die die mit einer bestimmten IP-Adresse verbundenen geografischen Daten wie Ländercode und Name des autonomen Systems zurückgibt.
Schließlich parst er die User-Agent-Zeichenfolge und wandelt sie in eine Zeichenfolge aus Familie, Hauptversion, Nebenversion und Patchversion um, da wir, wie bei der IP-Adresse, nicht alle Informationen benötigen.
use fastly::geo::{geo_lookup, Continent};
/// `ClientData` models information about a client.
///
/// Models information about a client which sent the NEL report request, such as
/// geo IP data and User Agent.
#[derive(Serialize, Deserialize, Clone)]
pub struct ClientData {
client_ip: String,
client_user_agent: String,
client_asn: u32,
client_asname: String,
client_city: String,
client_country_code: String,
client_continent_code: Continent,
client_latitude: f64,
client_longitude: f64,
}
impl ClientData {
/// Returns a `ClientData` using information from the downstream request.
pub fn new(client_ip: IpAddr, client_user_agent: &str) -> Result<ClientData, Error> {
// First, truncate the IP to a privacy safe prefix.
let truncated_ip = truncate_ip_to_prefix(client_ip)?;
// Lookup the geo IP data from the client IP. If no match return an
// error.
match geo_lookup(client_ip) {
Some(geo) => Ok(ClientData {
client_ip: truncated_ip,
client_user_agent: UserAgent::from_str(client_user_agent)?.to_string(), // Parse the User-Agent string to family, major, minor, patch.
client_asn: geo.as_number(),
client_asname: geo.as_name().to_string(),
client_city: geo.city().to_string(),
client_country_code: geo.country_code().to_string(),
client_latitude: geo.latitude(),
client_longitude: geo.longitude(),
client_continent_code: geo.continent(),
}),
None => Err(anyhow!("Unable to lookup geo IP data")),
}
}
}Jetzt da wir unsere Metadaten-Implementierung erstellt haben, können wir daraus eine neue Instanz kreieren und unsere Liste der zu loggenden Berichte generieren.Zu diesem Zweck wird jeder der geparsten Berichte gemappt und unser LogLine-Umschlag erstellt, der den Berichtstext und die Client-Metadaten unter Berücksichtigung eines Zeitstempels in einem einzigen Objekt zusammenfasst.Im Rahmen von NEL wollen wir lediglich die bereits auf der Edge vorhandenen Metadaten zur Ausschmückung nutzen. Wenn wir jedoch ausgefallenere Dinge tun wollen, wie beispielsweise zusätzliche Daten von einem Origin-Service abrufen, würden wir das hier tun.
// Construct a new `ClientData` structure from the IP and User Agent.
let client_data = ClientData::new(client_ip, client_user_agent)?;
// Generate a list of reports to be logged by mapping over each raw NEL
// report, merging it with the `ClientData` from above and transform it
// to a `LogLine`.
let logs: Vec<LogLine> = reports
.into_iter()
.map(|report| LogLine::new(report, client_data.clone()))
.filter_map(Result::ok)
.collect();Und schließlich durchlaufen wir die Liste der Logs, serialisieren jedes über Serde zurück zu einer JSON-Zeichenfolge und senden diese Zeile an unseren BigQuery-Logging-Endpunkt. Wenige Zeilen Rust genügen also, um unsere ETL-Pipeline überflüssig zu machen 🎉.
// Create a handle to the upstream logging endpoint that we want to emit
// the reports too.
let mut endpoint = Endpoint::from_name("reports");
// Loop over each log line serializing it back to JSON and write it to
// the logging endpoint.
for log in logs.iter() {
if let Ok(json) = serde_json::to_string(&log) {
// Log to BigQuery by writing the JSON string to our endpoint.
writeln!(endpoint, "{}", json)?;
}
}Hier ein Beispiel des Ergebnisses der Programmverarbeitung: ein gut strukturiertes JSON-Objekt, das zu unserem BigQuery-Schema passt:
{
"timestamp": 1597148043,
"client": {
"client_ip": "",
"client_user_agent": "Chrome 84.0.4147",
"client_asn": 5089,
"client_asname": "virgin media limited",
"client_city": "haringey",
"client_country_code": "GB",
"client_continent_code": "EU",
"client_latitude": 51.570,
"client_longitude": -0.120
},
"report": {
"url": "https://www.fastly-insights.com/",
"type": "network-error",
"body": {
"type": "abandoned",
"status_code": "0",
"server_ip": "",
"method": "GET",
"protocol": "http/1.1",
"sampling_fraction": "1",
"phase": "application",
"elapsed_time": "27"
},
"age": "34879"
}
}Wir haben jetzt alle Informationen, die wir brauchen: welche Art von Netzwerkfehler aufgetreten ist und in welchem Netzwerk, die Art des User Agents, der den Bericht erstellt hat, und eine ungefähre Angabe, wo in der Welt er aufgetreten ist. Die Daten sind so umfangreich, dass wir Echtzeit-Dashboards und Warnsysteme erstellen können, die uns helfen zu verstehen, wo und welche Probleme unsere Kunden beim Erreichen unserer Netzwerke haben.
Reduzierung der Komplexität und Erhöhung der Geschwindigkeit und Sicherheit
Durch die Migration unserer NEL-Reporting-Pipeline auf Compute konnten wir zwei sich bewegende Teile des Systems (den temporären Speicherbehälter und die CloudFunction) eliminieren, was wiederum den betrieblichen Aufwand und die Gesamtkosten des Systems reduzierte.
Ich halte allerdings die Verbesserungen bei Performance, Sicherheit und Datenintegrität für die ausschlaggebendsten Vorteile:
Die Berichte erscheinen nun innerhalb von Sekunden nach Erhalt in BigQuery, anstatt wie bisher erst nach mehreren Minuten. Damit kehren wir zu dem Echtzeit-Logging zurück, das wir von Fastly gewohnt sind.
Durch die Verwendung eines starken Typsystems in Rust für das JSON-Parsing loggen wir jetzt nur noch gültige Berichte. Dadurch entfällt die Notwendigkeit der Nachbearbeitung, da eine einzige Code-Base ausreicht, um Schemaänderungen einzuführen.
Das sich daraus ergebende Architekturdiagramm unserer neuen Pipeline sieht gleich viel unkomplizierter aus:
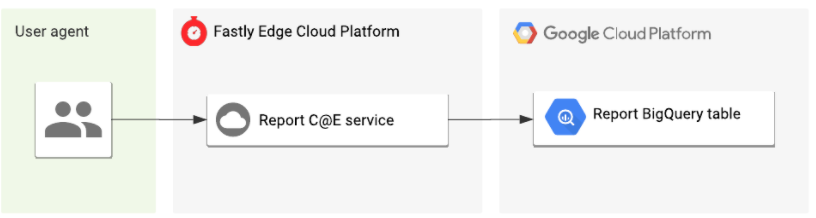
Dies ist nur ein kleines Beispiel dafür, wie wir intern bei Fastly die Vorteile der Plattform nutzen. Ich freue mich bereits jetzt darauf, Ihnen in Zukunft weitere Beispiele vorzuführen.
Probieren Sie’s selbst aus
Wenn Sie immer noch nicht überzeugt sind oder den Code für die vollständige Anwendung in seiner ganzen Pracht sehen wollen, können Sie ihn sich auf GitHub anschauen.Noch einfacher ist es, wenn Sie ein Compute-Beta-Kunde sind, denn mit unserem NEL-Starterkit können Sie ein neues Projekt mit einem einzigen CLI-Befehl initialisieren:
$ fastly compute init --from https://github.com/fastly/fastly-template-rust-nel.gitNeue Beta-Kunden können sich hier anmelden.Wir sind gespannt, welche weiteren Anwendungsfälle sich noch ergeben werden, jetzt da unsere Kunden das wahre Potenzial der Plattform zu erschließen beginnen. Teilen Sie uns Ihre Erfahrungen also bitte gerne mit.Wir wünschen Ihnen bei all Ihren C@E-Unternehmungen viel Freude und Erfolg!