
Einer der wichtigsten Faktoren für ein sauberes, ungestörtes Livestreaming-Erlebnis ist der richtige Umgang mit Netzwerküberlastungen – eine Aufgabe, die unsere Plattform größtenteils automatisch, rund um die Uhr und mit nur wenigen menschlichen Eingriffen erfüllt. Als Teil des Live-Event-Streaming-Teams von Fox Sports für den Super Bowl LIV konnten wir beobachten, wie diese Automatisierung an einem der wichtigsten Tage im Sportkalender ihre Wirkung entfaltet. Im Folgenden erfahren Sie Schritt für Schritt, wie Netzwerkautomatisierung, ein kleines Team von Entwicklern und wichtige Erkenntnisse aus vergangenen trafficlastigen Ereignissen es uns ermöglichen, unseren Kunden skalierbare Performance zu liefern.
Dreamteam Automatisierung und Fachkräfte
Unser Livestreaming-Prozess beginnt mit der direkten Verbindung zu zahlreichen ISPs im ganzen Land. Wir tun alles, um unseren Live-Video-Traffic auf diesen direkten Wegen zu unseren Verbindungspartnern zu halten, damit Videostreams so nah wie möglich am Endnutzer ausgeliefert werden. Wenn der Traffic aber zunimmt, sind diese Verbindungspunkte irgendwann überlastet. Dann leidet die Qualität. Livestreaming-Zuschauer haben aufgrund von Paketverlusten mit Performance-Problemen wie Videopufferung oder verringerter Streamingqualität zu kämpfen – mehr als die Hälfte der Zuschauer bricht eine schlechte Online-Übertragung innerhalb von 90 Sekunden oder weniger ab.
An diesem Punkt wird unsere integrierte Netzwerkautomatisierung – intern als Auto Peer Slasher (oder APS) bezeichnet – aktiviert. Unterstützt wird diese Orchestrierung von StackStorm. Wir hoffen, bei einem zukünftigen Blogpost genauer auf den Aufbau eingehen zu können.
Wenn APS erkennt, dass sich die Auslastung der Verbindung der vollen Kapazität nähert, wird eine Warnung an unser Team gesendet und automatisch ein kleiner Teil des Traffics umgeleitet, um die Verbindung unterhalb der Überlastungsschwellen zu halten. Die Umleitung zum jeweiligen ISP erfolgt automatisch über bestmögliche alternative Pfade, was in der Regel über IP-Transit ist. Bei umfangreichem Livestreaming-Traffic kann dies innerhalb weniger Minuten mehrmals passieren, sodass die Plattform den Traffic immer wieder von den Verbindungspartnern auf IP-Transit umleitet. In den meisten Fällen bleibt der Verbindungsstatus erhalten, sodass der Player die Sitzung nicht von Grund auf neu starten muss.
Unten sehen Sie ein Beispiel für diesen Prozess in Aktion. Nach Eingang einer Warnung führte APS einen bestimmten Workflow aus, der mehrere Aktionen für Verbindungen zu einem ISP im Großraum Washington D.C. vorsah, während unserem Team über Slack gleichzeitig Bericht erstattet wurde.

In der folgenden Grafik sehen Sie, dass APS jedes Mal, wenn diese Verbindungen zu 90 % ausgelastet sind, gerade genug Traffic abschaltet, um die Verbindungen aus der Überlastungszone herauszuhalten.
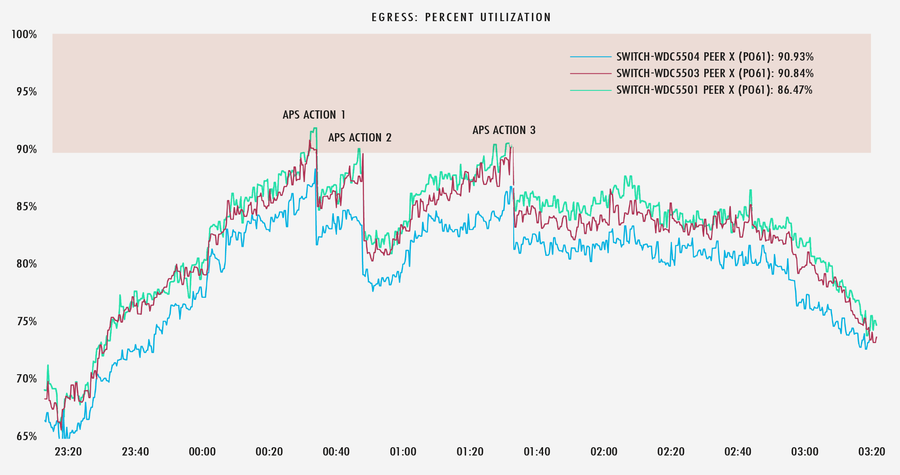
Gegen Ende einer Live-Veranstaltung, wenn Traffic-Spitzen abnehmen, weiß APS, dass diese Aktionen rückgängig gemacht werden müssen, und wir fangen sozusagen wieder bei null an.
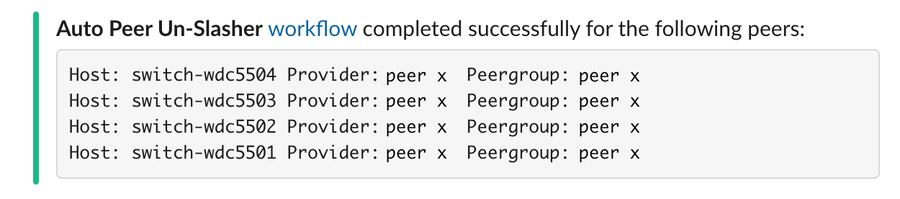
Die Auslastung der Verbindungen ist jedoch nur ein Maß und sagt nicht unbedingt etwas über eine mögliche Überlastung in bestimmten Backbones oder ISP-Netzwerken aus. Verlustraten und erneute Übertragungen sind äußerst nützliche Informationen, die wir mit einer anderen Technik, die wir Fast Path Failover (FPF) nennen, in Echtzeit beobachten und entsprechend behandeln. Unsere Edge-Caches überwachen den Fortschritt der einzelnen TCP-Flows der Endnutzer. Sobald der Datenfluss über einen bestimmten Pfad ins Stocken gerät, löst der Cache automatisch einen Versuch aus, den Datenfluss über einen alternativen Pfad weiterzuleiten – in der Hoffnung, einen stabilen Zustand und eine gute Verbindungsqualität zu erhalten.
Wenn die Menge des automatisch umgeleiteten Traffics die verfügbare Kapazität der alternativen Pfade übersteigt oder wenn FPF nicht in der Lage ist, unbelastete alternative Pfade zu finden, müssen wir eine Entscheidung darüber treffen, wie der Traffic als Nächstes umgeleitet werden soll. Und genau hier kommt unser Team ins Spiel.
Aus vergangenen Großveranstaltungen haben wir gelernt, dass die Komplexität des Traffic Engineering durch den Ansatz „alle Mann an Bord“ unnötig erhöht wird. Das talentierte Netzwerk-Engineering-Team bei Fastly ist bereits eine unglaublich effiziente Gruppe, aber bei großen Live-Events reduzieren wir die Anzahl der Entscheidungsträger noch weiter – im Durchschnitt sind es dann nur noch 12 Entwickler. Wir unterteilen die Region in Quadranten und weisen jedem einen leitenden Entwickler zu. Jedem leitenden Entwickler steht ein Co-Pilot zur Seite, der Warnungen und Schwellenwerte im Auge behält und bei Bedarf Informationen an den Leiter des Quadranten weitergibt, während er die vom leitenden Entwickler vorgenommenen Änderungen ein zweites Mal validiert und überprüft. Wenn unsere automatische Verlagerung des Traffics von den direkten ISP-Verbindungen an die Obergrenze der verfügbaren POP-Kapazität (Points of Presence) stößt, entscheidet das Entwicklerduo gemeinsam, wie und wohin der Traffic als Nächstes verlagert werden soll. Dies geschieht in der Regel durch Änderung unserer BGP-Anycast-Ankündigungen (Border Gateway Protocol) oder Beeinflussung der POP-Auswahl der Endnutzer über unsere DNS-Verwaltungsplattform (Domain Naming System). So in etwa läuft der Prozess hinter den Kulissen ab, um eine gestochen scharfe Echtzeit-Übertragung jedes Live-Events gewährleisten zu können.
Umsetzung des Prozesses in die Praxis
Die oben beschriebenen Automatisierungen und Systeme laufen täglich rund um die Uhr – eine dauerhafte Verbesserung, von der alle unsere Kunden zu Zeiten mit hohem Traffic-Aufkommen profitieren. Nichtsdestotrotz sind wir immer wieder gespannt, wie das Ganze bei Traffic-Spitzen und bei der Vorbereitung auf große Livestreaming-Events tatsächlich umgesetzt wird.
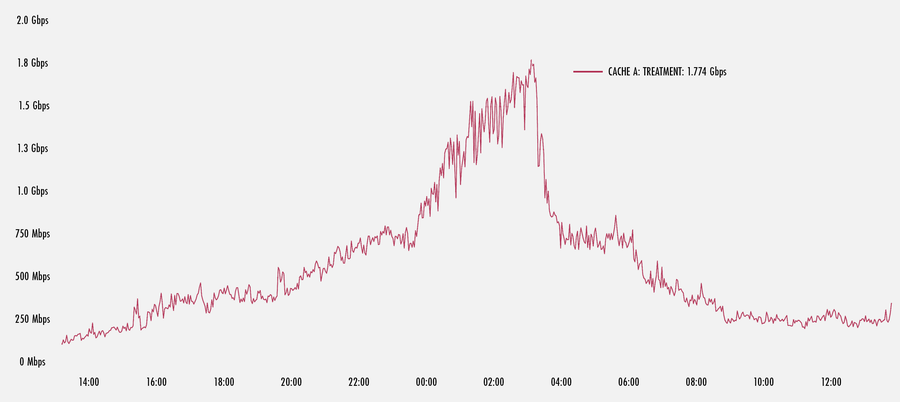
Wie Sie der Grafik unten entnehmen können, hat ein starker Anstieg des Traffics an einem unserer US-amerikanischen POP FPF in Gang gesetzt. Hier sehen wir, wie ein Cache im POP die FPF-Datenströme mit fast 1,8 Gbit/s in die Höhe treibt, bis der Datenanstieg endet. Dies ist nur ein kleiner Prozentsatz des gesamten Traffics, der von diesem einen Rechner verarbeitet wird. Hochgerechnet auf viele Rechner in einem POP, kann der gesamte umzuleitende Traffic also extrem hoch sein.
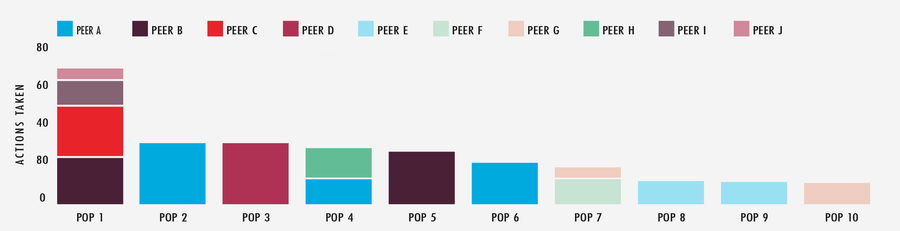
Bei der Untersuchung eines weiteren mehrtägigen Großereignisses wird deutlich, welch erheblichen Einfluss unser APS-System hat. In einem Zeitraum von 48 Stunden hat APS bei den 10 aktivsten POPs und Verbindungspartnern insgesamt 349 Aktionen gegen das Netzwerk durchgeführt. Da APS einen Großteil der schweren Arbeit erledigt, kann das Team seine Energie für die Feinabstimmung einiger Systementscheidungen aufwenden und sich auf andere Elemente der Performance der Edge-Cloud-Plattform konzentrieren.
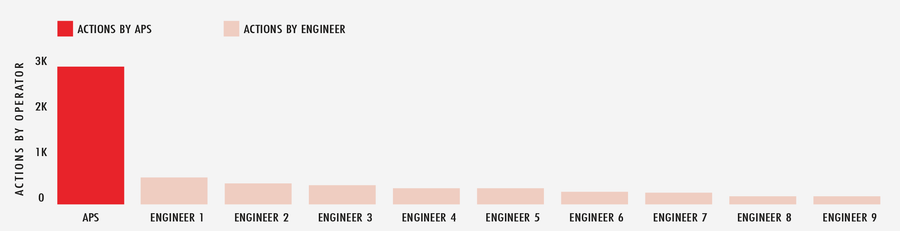
Wenn wir den gesamten Monat Februar im Jahr 2020 ganzheitlich betrachten, hat APS mehr als 2.900 automatisierte Aktionen im gesamten globalen Netzwerk durchgeführt, um auf die sich ständig ändernden Internetbedingungen zu reagieren. Dem gegenüber stehen nur etwas mehr als 500 Aktionen, die von dem Entwickler, der auf Abruf bereitstand, im gleichen Zeitraum vorgenommen wurden. Kurz gesagt entspricht APS also zusätzlichen Teams auf dem Spielfeld.
Erfolgreiches Livestreaming in 3, 2, 1 … Action
Das Streaming von trafficlastigen Live-Events ist ein anspruchsvolles Unterfangen. Aber mit integrierter Automatisierung, einer talentierten Gruppe von Entwicklern und einem leistungsstarken Netzwerk im Hintergrund kann unsere Plattform diese genauso gut bewältigen wie einen stinknormalen Dienstag. Wir wissen, welche Kapazitäten, Technologien und Vorbereitungen erforderlich sind, damit unsere Kunden jeden großen Moment mit einem Gefühl der Begeisterung angehen können, weil sie wissen, dass ihr Name, ihr Ruf und die Qualität des von ihnen bereitgestellten Erlebnisses in guten Händen sind.